CNN-RNN-CTC Based End-to-End Mispronunciation Detection and Diagnosis - Leung, W. K., Liu, X., & Meng, H. @ ICASSP 2019 논문 리뷰 글입니다.
Abstract
main point : CNN-RNN-CTC 구조를 가진 모델을 제안 : E2E 모델이 MDD task 에 처음으로 적용된 논문
- phonemic, graphemic 정보가 필요 없고, forced alignment 도 필요없기 때문에 유용하게 사용될 것으로 기대됨
- 다양한 baseline 모델들의 성능과 비교한 결과 - F1 measure 에서 다 이김
| Model | Relative Increase |
| Extended Recognition Network (ERN) (S-AM) | 44.75% |
| State-Level Acoustic Model (S-AM) | 32.28% |
| Acoustic-Phonemic Model (APM) | 9.57% |
| Acoustic-Graphemic Model (AGM) | 5.04% |
| Acoustic-Phonemic-Graphemic Model (APGM) | 2.77% |
- This paper focuses on using Convolutional Neural Network (CNN), Recurrent Neural Network (RNN) and Connectionist Temporal Classification (CTC) to build an end-to-end speech recognition for mispronunciation detection and diagnosis (MDD) task.
- Our approach is end-to-end models, while phonemic or graphemic information, or forced alignment between different linguistic units, are not required.
- We conduct experiments that compare the proposed CNN-RNN-CTC approach with alternative mispronunciation detection and diagnoses (MDD) approaches.
1. Introduction
Key technologies of CAPT : Phone-level MDD
- 음성인식기 성능을 향상시키는 것보다 MDD 성능 향상시키는 것이 더 어려움
- 음성인식기는 언어 모델의 보조를 받을 수 있지만, MDD 는 언어모델을 함부로 썼다가 mispronunciation 을 오히려 놓칠 수 있다는 위험성이 있음
- 따라서 언어모델을 함부로 쓸 수 없어서 성능 향상에 어려움을 겪고 있음
- 대신에, 언어 모델보다 음향적인 모델링을 어떻게 잘 할지에 대한 고민
- acoustic modelling = 해당 발음된 음소가 native 인지, non-native 인지 잘 구분할 수 있게끔 모델링
- Difficult task compared to ASR, because ASR can use the language model
- outweigh the effect of inaccurate acoustics to output the legitimate character sequence - For MDD, the constraints offered by the language model is not helpful
- lead to missed detection of mispronunciations - Hence, strong acoustic modelling is important.
- to discriminate between native production & the deviant non-native pronunciations.
Previous studies
Extended Recognition Network (ERN)
- 언어 모델의 보조를 받는다고 할 수 있음
- canonical 한 발음열에 더해서 학습자들이 자주 범하는 오류 패턴들을 언어 모델 그래프에 추가적으로 뚫어주는 방법론
- 실제로 안정적인 성능을 보여서 application 에 자주 사용되는 방법론
- 단점 ) 예측되지 않은 학습자의 오류 패턴은 절대 찾아내지 못함
- 이걸 최대한 잡아내려고 모든 길을 다 뚫으면, 오히려 잘 되고 있는 phoneme recognition 성능도 떨어질 수 있음 - 해결책 ) free phone recognition - 모든 음소에 대한 경우를 다 모델링할 수 있도록 제안한 모델
- utilizes phonological rules to derive mispronunciation patterns - formulate ERN
- applications : Enunciate, mEnunciate
- drawbacks
- no gurantee whether all mispronunciation possibilities from all language learners are covered
- overly busy recognition network = lower performance on AM models - solution : free-phone recognition
- all possible alternative phones are considered ( = all possible mispronunciations are covered )
- S-AM (State-level Acoustic Model) : 예전에는 text 정보를 함께 넣어줬지만, 이 모델에서는 acoustic feature(spectrogram) 정보를 넣음 - 한 음소 뒤에 뭐가 나올지에 대한 정보를 주지 않은 채로 이 phoneme 이 어떤 phoneme 이야 하고 classification 하도록 만든 모델 - 성능 별로였음
- 따라서 추가적으로 텍스트 정보를 넣어줌 : APM(acoustic-phonemic model), AGM(acoustic-graphemic model), APGM(acoustic-phonemic-graphemic model) - 위 모델들의 단점은 결국에 force-alignment 가 필요하다는 단점
Proposal
Model which 1) does not require force-alignment 2) for free-phone recognition in MDD
- force-alignment 가 없으려면 CTC(connectionist temporal classification) loss 필요
- CNN-RNN
- CNN : 음소인식 과제에서 robust 한 성능을 보인다고 알려져있어서 사용
- RNN (GRU) : CNN 은 local 한 정보를 뽑는다면, RNN 은 global/temporal 정보를 함께 모델링할 수 있기 때문
2. CNN-RNN-CTC model for MDD
- CNN-RNN-CTC model 은 5개 파트로 구성됨
: Input layer, CNN layers, Bi-directional GRU, MLP layer, CTC output layer

Input Layer
- accepts framewise acoustic features
- input layer + batch normalization layer + zero padding layer
- zero padding : to force inputs to have the same length
- CNN 에 넣어주기 위해서 일단 input 크기가 같아야 하기 때문에 zero padding
CNN layers
- 2 * ( 2 CNN + 1 Max pool layer) + batch normaliation layer
- captures high level acoustic features (local features)
Bi-directional GRU
- RNN 중에서도 computation 속도가 빠른 GRU 넣어줌
- captures temporal acoustic features
- GRU instead of LSTM : faster training process
MLP layer
- MLP 레이어 중에서도 Time Distributed Dense layers 사용
- applies a layer to every temporal slice
- CTC needs sequence information as input - softmax layer : for classification
CTC output layer
- generate predicted phoneme sequence
- softmax output layer 을 통해 나온 값과 input length, label length, label sequence 정보를 함께 넣어서 CTC loss 계산
3. Experiments
3.1. Setup
Speech Corpus
- TIMIT, CU-CHLOE(Chinese University Chinese Learners of English) 사용
- 모든 문장들은 다 trained 된 음성학자들이 labelling 진행됨
- TIMIT 은 training set, CU-CHLOE 는 training, development, test set 으로 사용됨
- CU-CHLOE 는 speaker independent 하게 구성되어서 사용됨
Model Training
- Input for model : spectrogram
- 스펙트로그램을 위해서 FFT 사용 - Input for CTC loss : softmax output, input length, input labels(annotated label sequence), label length

- Input length : output layer 에서 나온 것의 length
- Label length : blank 와 반복되는 것들을 없앤 length
- each experiment trained with 30 epochs
- implemented by Keras, Tensorflow
- Metric : F-measures
3.2. Evaluation
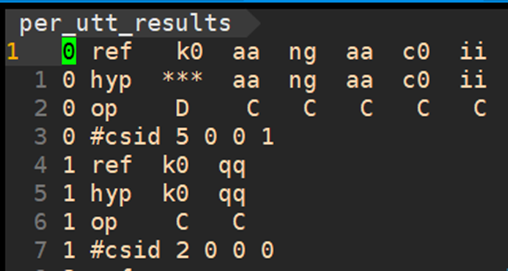
- Kaldi 돌려서 나오는 결과와 비슷 : reference 와 CNN-RNN-CTC output 인 phoneme sequence 를 강제정렬한 것 바탕으로 - 해당 음소가 잘 발음 되었는지, insertion/deletion/substitution 되었는지에 대한 판단
- recognized phoneme sequence are aligned with the annotated sequences
- Needleman-Wunsch Algorithm

- aligned phone sequences are used to count correctness, insertion, deletion, and substitution
Performance of Phone Recognition
: 모델이 얼만큼 음소를 잘 분류하는가 / 얼마나 음성인식 성능이 좋은가

- investigation on how hidden unit size affects the performance with same number of layers
- best recognition result : 87.93%, hidden size : 1024 - 마지막 hidden unit 의 hidden size 에 대해 - hidden size 가 1024 였을 때 가장 좋은 음성인식 성능 보임



- 선행연구들과의 비교 - recognition rate for correct pronunciation
- 음소인식 성능 : S-AM, ERN(S-AM) 보다 성능 더 좋았지만, APM, AGM, APGM 보다는 성능 더 낮았음
- 이유 : APM, AGM, APGM 과 달리 proposed 모델은 phonemic, graphemic 정보를 사용하지 않아서


- 각 음소마다 더 살펴보면, S-AM 보다는 모든 음소에 대해서 더 좋은 성능을 보임
- AGPM 보다는 더 낮은 성능을 보였지만, /ah/, /ih/, /d/, /t/, /s/ 에 있어서는 더 좋은 성능을 보임
Performance of MDD
- True Acceptance (TA) : correct pronunciation 을 correct pronunciation 으로 잘 판단했는지
- True Rejection (TR) : mispronunciation 을 mispronunciation 으로 잘 판단했는지
- correct diagnosis (CD) : 진짜 그 음소로 잘못 발음했다고 잘 얘기했는지에 대한 척도
- diagnosis error (DE) : 틀렸다고 말했는데, 엉뚱한 음소로 발음했다고 디코딩한 경우 - False Acceptance (FA) : mispronunciation 인데 correct pronunciation 이라고 잘못 판단한 경우
- False Rejection (FR) : correct pronunciation 인데 mispronunciation 이라고 잘못 판단한 경우
Mispronunciation diagnosis

- False Rejection Rate (FRR) : performance on correct pronunciations
- 잘 발음한 것에 있어서 얼마나 성능이 나오는지 - False Acceptance Rate (FAR) : performance on mispronunciations
- 잘못 발음한 것에 있어서 얼마나 성능이 나오는지 - Diagnosis Error Rate (DER) : performance on mispronunciations (in detail) / related to True Rejection

- Precision : mispronunciation 이라고 판단한 것 중 얼마나 정확하게 mispronunciation 이라고 판단하였는지
- Recall : mispronunciation 음성 중 얼마나 정확하게 mispronunciation 이라고 판단하였는가
- F-measure : Precision 과 Recall 의 조화평균 (harmonic mean value)
- 얼마나 mispronunciation 을 잘 판단하였는가

- Mispronunciation detection & diagnosis
- detection accuracy (잘발견했는지)
- diagnosis accuracy (음소인식기가 얼만큼 성능이 좋았는지)
Performance with different hidden sizes

- best f-measure : 74.62%
- hidden unit size : 1024
Comparison with previous studies (F-measure)

4. Conclusion
- MDD task 에 end-to-end approach 를 적용한 첫번째 논문
- 그 덕분에 forced alignment 사용 X, phonemic, graphemic 정보도 필요 없었음 - 이것 없이도 성능 이뤄냄
- 실험 결과, MDD task 에 있어서 기존 baseline 모델보다 더 좋은 성능을 보였음
- contribution point : MDD task 에 end-to-end 모델을 사용했다는 점
- future work : linguistic information 이 하나도 사용되고 있지 않기 때문에 어떻게 적용할까 생각해보겠음
Reference
- 서울대 음성언어처리연습 논문리뷰 여은정님 발표
- CNN-RNN-CTC Based End-to-End Mispronunciation Detection and Diagnosis - Leung, W. K., Liu, X., & Meng, H. @ ICASSP 2019




댓글