앞 게시글에 이어서 Kim, H. et al. (2021) Multi-domain Knowledge Distillation via Uncertainty-Matching for End-to-End ASR Models 논문 리뷰를 이어가겠습니다.

이제 음성인식에 불확실성을 적용해보자면,
음성 인식의 불확실성은 일반적으로 소음 레이블링, 스피커간의 변화, 또는 혼동되는 발음에서 발생합니다.
예를 들어, 그림 1은 ground-truth token 이 주어졌을 때, 왼쪽 토큰 수준 class 확률과 오른쪽aleatoric 불확실성 인식 결과를 보여주는데,
- 입력 발음에 모호한 발음이 있을 경우, 인식 결과는 HEAR 과 HOR 사이의 혼동 발음 오류를 보여줍니다. 또 모델은 HEAR 토큰에서 낮은 클래스 확률 값과 높은 불확실성 값을 보입니다.
- 앞 논문의 방법을 활용해서 aleatoric 불확실성을 계산할 수 있다고 했는데, 따라서 이 식을 통해 aleatoric uncertainty 는 명시적으로 모델링될 수 있으므로, 이 uncertainty 를 KD 지식 전달에 활용할 수 있습니다. 특히 모델은 소프트맥스 연산 후 확률 벡터 pi를 형성하는 각 토큰에 대한 logit vector fi를 예측합니다.
- 토큰별 불확실성(token-wise aleatoric uncertainty)을 모델링하기 위해, 네트워크는 로짓 벡터 fi와 치수가 같은 분산 벡터 시그마 i 제곱을 생성하고, 여기서 hi는 이전 로짓 계층에서 토큰 i의 표현이고, 시그마 i 제곱은 hi가 주어졌을 때 선형적으로 투영됩니다.
- 비선형 함수 f의 경우, RELU 처럼 제약 조건을 만족하는 한 어떤 함수라도 사용할 수 있습니다.
- 그 이후 벡터 gi는 소프트맥스 함수를 통과해 pi 로 나타낼 수 있습니다.
Uncertainty-matching 지식 증류를 위해서 최종 loss 는 일반적인 지식 증류와 같이 ground truth 와 hard prediction 과의 비교인 student loss 와 teacher network 의 soft label 간의 distillation loss 의 가중합으로 이루어져있습니다.
여기서도 아까 E2E ASR 을 위한 일반적인 hard prediction 간의 loss 인 L NLL 과 distillation loss 인 L KD 의 가중합을 통해 최종 loss 를 구하게 됩니다. 여기서 distillation loss 인 L KD 를 구할 때는 token-level 의 loss 뿐만 아니라 uncertainty 를 고려한 loss 를 더해서 최종 L KD 를 구하게 됩니다. 그리고 이 불확실성을 고려한 loss function 의 경우, 정규화된 해당 MSE 함수를 사용해 교사와 학생 네트워크의 token-level noise vectors 에 있는 지식을 전송합니다.
여기서 하이퍼파라미터 알파는 NLL과 KD 손실 함수 사이의 상대적인 중요성을 제어하고, 베타는 tok-KD와 unc-KD 손실 함수 사이의 상대적 중요성을 제어합니다.
오른쪽과 같이 여러개의 교사 네트워크가 주어졌을 때는 r k 의 k번째 교사 모델에 대한 상대적 가중치를 둬서 loss 를 구할 수 있습니다.
다음으로는 experiment 셋업입니다.
이 실험은 LibriSpeech, Tedlium2 및 WSJ 의 다중 도메인 데이터셋을 이용해 실험하였고,
각각 데이터셋에 대해서는
- LibriSpeech는 960시간의 public books 리딩으로 구성되어 있고,
- Tedlium2 데이터셋은 207시간의 TED 강연 오디오에서 추출되었습니다.
이 두 개의 데이터셋을 이용해 teacher networks 를 훈련시켰고,
WSJ 의 경우에는 대략 81시간의 speech인 si-284 를 훈련 셋으로, nov93을 development 셋으로, nov92를 테스트셋으로 사용했습니다.
Student network는 이 WSJ 데이터셋을 이용해 훈련되었고, WSJ 의 LM 의 경우, 512 필터, 5048 히든유닛, 8 heads 의 12 레이어 트랜스포머 LM 을 사용했습니다.
또 모든 음성 데이터셋에 대해 입력 신호를 3차원 pitch features 를 가진 80차원 log-Mel 필터 뱅크의 시퀀스로 나타내고, SentencePiece 토크나이저 사용, 출력 단위 모델링을 위해서 blank, unk, space 를 포함한 31개의 문자를 선택했습니다.
- ASR 모델 훈련을 위해 0.15 label smoothing 과 100k gradient updates 후 sampling 을 진행했고, 최종 모델로서, 토큰레벨 validation 셋에서 가장 높은 인식 정확도를 내는 5개의 checkpoints 를 평균내서 사용하였습니다.
- 또, WSJ 실험에 대한 전반적인 기본 설정은 ESPnet의 기본설정을 따릅니다. 모든 모델은 weight 0.3의 CTC 손실 함수와 공동으로 훈련되게 하였으며, 토큰 레벨 확률 사이 로그 선형 보간 융합을 통해 신경망 기반 LM 을 E2E ASR 모델과 통합했습니다. 마지막으로 평가 지표는 단어 오류율 (WER) 을 통해 평가했습니다.

- 테이블 2와 같이 교사와 학생 모델 기본 성능을 살펴보면, 학생 모델 크기가 줄어들면서 인식 성능은 더 저하되고,
Nov92 에서 압축 비율이 base에서 tiny로 0.3일 때, WER은 4.9%에서 5.6% 으로 증가했습니다.
또, 두 교사 모델인 Libri 와 Ted 모델의 인식 성능은 student model 들보다 더 좋고, Libri 모델이 2.9%의 최고 WER 을 보여줍니다. Tedlium2 모델은 Libri 보다 더 작은 언어 코퍼스로 훈련되었기 때문에 Libri 보다는 살짝 더 성능이 떨어집니다.

본 논문에서 제안된 지식 증류 방법의 효과는,
전반적으로 baseline performance 를 다 능가했고, uncertainty-KD 방법 또한 서로 다른 도메인의 teacher networks 를 사용했을 때도 잘 적용되었습니다.
Libri 와 Ted 모두 사용했을 때 3.1%로 baseline performance 보다 WER 이 36.7% 감소하였고, uncertainty KD를 함께 썼을 때 nov92 에서 WER은 각각 3.0% 3.3%를 달성하여 tok-KD 만 사용한 지식 증류 방법보다 Libri, Ted 각각 14.3%, 10.8% 개선을 보였습니다.
두 교사 네트워크를 함께 사용했을 때의 최종 WER은 5.0%, 3.1%로 student baseline performance 에 비해 35.9%, 36.7%의 상대적인 개선을 보여줍니다.

- 테이블 4에서는 WSJ 기반 모델보다 네트워크 크기가 작은 학생 모델의 전반적인 인식 성능을 보여주는데, WSJ 보다 더 모델 크기가 작아졌음에도 불구하고 KD 를 수행하면 모든 경우에 WSJ 기반의 baseline performance 를 넘었습니다.
제안된 uncertainty KD 방법에 의한 WSJ small 과 tiny 모델의 최종 WER은 nov92에서 3.8%, 4.3%로 각 baseline performance 에 비해 29.6%(5.4à3.8), 21.8%(5.5à4.3)의 상대적인 WER 개선을 보였습니다.
- tok-KD 방법만 사용했을 때와 비교해보면 uncertainty KD 는 인식 성능을 개선하는데 도움을 준다는 것을 확인할 수 있습니다.
마지막으로 학생 모델에 적용한 최종 KD 결과가 Tedlium2 의 baseline performance 인 4.5%를 능가한다는 것을 보이면서, 본 논문에서 제안한 uncertainty KD 를 적용한 학생 모델이 결국 teacher model 을 능가했다는 것을 보여줍니다.

불확실성 모델링이 언어 모델에 미치는 영향을 살펴보면, uncertainty 모델링을 통한 훈련이 전체적으로 결과가 좋았고, 특히 불확실성이 있는 트랜스포머 ASR 모델은 LM 없이 디코딩했을 때 상대적인 개선을 보였습니다.
오른쪽 그림에서는 Librispeech 와 Tedlium2 교사 모델에서의 각 토큰에 대한 확률과 uncertainty 분포를 보여주는데, 두 교사 모델의 출력 확률 분포는 비슷한 모양을 하고 있지만, 두 모델간의 불확실성 분포는 토큰마다 상당히 다르다는 점이 흥미로운 부분입니다.

다른 ASR 시스템과 비교해보면, 본 논문의 방법론을 적용한 WSJ small과 tiny 모델은 소형 모델임에도 불구하고 기본 WSJ 에 비해 성능이 뛰어나고,
Deep Speech 2 모델은 ASR 모델에 대한 150배 더 많은 트레이닝 데이터와 LM 훈련을 위해 풍부한 텍스트를 사용하여 모델을 훈련시켜서 WER 3.6%가 나왔습니다.
Transfer learning 이 포함된 QuartzNet 의 경우 지도 학습 작업에 대한 WSJ 에서 최고의 문자기반 성능을 보여주었습니다. 이 모델은 960 시간 LibriSpeech 및 mozillas Common voice 데이터셋으로 pre-training 된 다음, WSJ 에 대해 fine-tuned 되어 WER 3.0% 을 보여줍니다.
본 논문에서 사용한 학생 모델은 이러한 다른 모델들에 비해 WSJ 훈련셋을 가지고 81시간동안 순수하게 훈련되면서 + 교사모델의 정보를 활용해 좋은 성능을 낼 수 있었습니다.

마지막으로 본 논문에서는 제한된 데이터로 모델의 성능 저하를 극복하기 위해서 self-attention 기반 E2E 모델에 대한 uncertainty 기반 KD 방법론을 제안했습니다.
Ground-truth 시퀀스에 기초한 교사 모델의 출력 시퀀스의 aleatoric uncertainty 를 KD 손실 함수에 매칭시켰고, 서로 다른 영역의 여러 교사들을 사용했을 때의 결과를 보여주면서 multi-domain 의 효과도 보여줄 수 있었습니다.
WSJ 의 baseline 보다 WER 이 개선됨을 보이면서 제안된 방법론이 의미있다는 것을 보였고, 마지막으로 이 방법론이 불확실성을 모델링할 수 있는 다른 인식 시스템에도 적용될 수 있습니다.
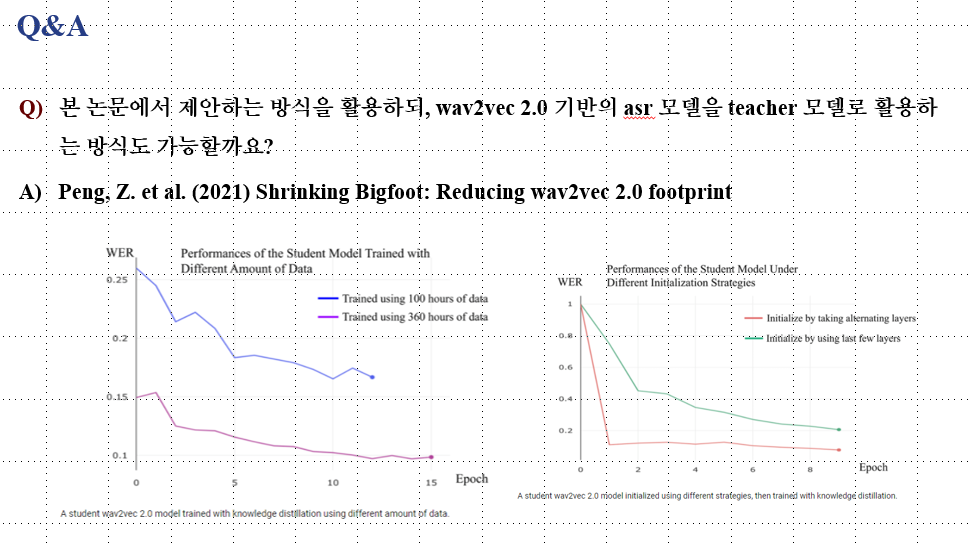
본 논문에서 제안하는 방식을 활용하되, wav2vec 2.0 기반의 asr 모델을 teacher 모델로 활용할 수도 있을까요?Reducing wav2vec 2.0 footprint 이라는 논문을 보면, 이 논문은 처음으로 wav2vec 2.0 에 지식 증류를 시도해본 논문인데, 이 논문에서는 wav2vec 2.0 모델을 teacher model 로 활용해 더 작은 학생 모델로 압축하는 실험을 보였습니다.
wav2vec 2.0 의 가장 큰 버전은 3억 천칠백만개의 매개변수를 포함하는 아주 큰 모델이기 때문에 KD 를 사용해 다양한 압축을 시도했을 때, 앞선 교사-학생 방식을 사용해 원래의 wav2vec 2.0 모델보다 두배 더 빠르고 4.8배 더 작은 학생 모델로 지식을 증류했다고 합니다.
이상 Kim, H. et al. (2021) Multi-domain Knowledge Distillation via Uncertainty-Matching for End-to-End ASR Models 논문 리뷰를 마치겠습니다.




댓글