이 글은 나동빈님의 'Transformer : Attention Is All You Need' 논문 리뷰 영상을 보고 정리한 글입니다.
Seq2Seq 의 문제 : 하나의 문맥 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
해결 방안 : 그렇다면 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까?
==> 'Attention' 메커니즘 사용해 인코더의 모든 출력 참고 가능
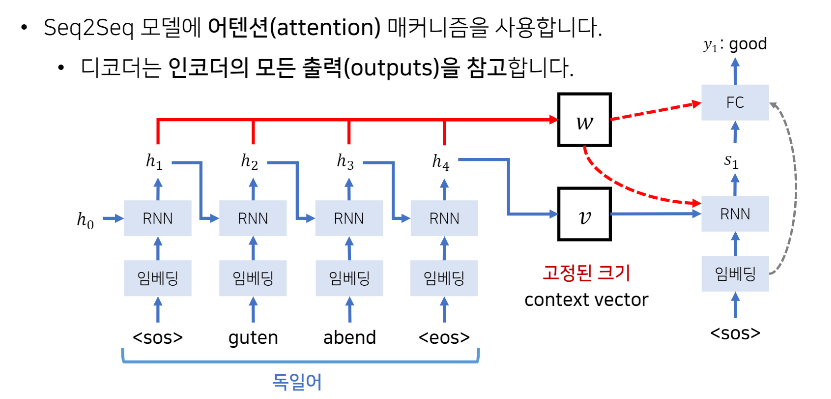
- 매번 단어가 출력되어서 hidden state 가 나올 때마다 그냥 그 값들을 전부 출력 값으로써 별도의 배열(w)에 다 기록해놓음
- 각각의 단어를 거치면서 나오는 h1, h2, h3, h4 들을 다 저장.
- 출력 단어 생성할 때마다 이 소스 단어들(w)을 다 참고하겠다는 아이디어
- 각 단어들을 다 똑같이 그냥 참고하는 것이 아니라, 각 단어별 중요도에 따라 가중치를 두고 참고함
ex) 디코더 파트에서 매번 hidden state (s1, s2 ... ) 갱신하게 되는데, s2 를 만드는 과정을 살펴보면,
바로 이전의 hidden state 값 s1 과 소스 문장의 hidden state 값들 h1, h2, h3, h4 을 서로 묶어 행렬곱을 수행해서 energy 값 계산
- energy 값 = 현재 단어를 출력하기 위해서 소스 문장의 어떤 단어에 초점을 둘 필요가 있는지 수치화한 값
- 그러한 energy 값에 softmax 취해서 확률 값 구함
- 소스 문장 각각의 hidden state 값 h1, h2, h3, h4 에 대해서 어떤 벡터에 더 많은 가중치를 두어서 참고하면 좋을지를 반영
- 각 hidden state 에 가중치 값 곱한 것을 각각의 비율에 맞게 더해줌
- 그 weighted sum 값을 매번 출력 단어를 만들기 위해서 반영
"Seq2Seq with Attention" 결론
단순히 context vector 만 참고하는 것이 아니라, 거기에 더불어 소스 문장에서 출력 되었던 모든 hidden state 값들 h1, h2, h3, h4 전부 반영해서 이 소스 단어의 단어들 중 어떤 단어에 더 주의 집중해서 출력 결과를 만들 수 있을까를 모델이 고려하도록 하여 성능을 개선
디코더 계산과정 살펴보기
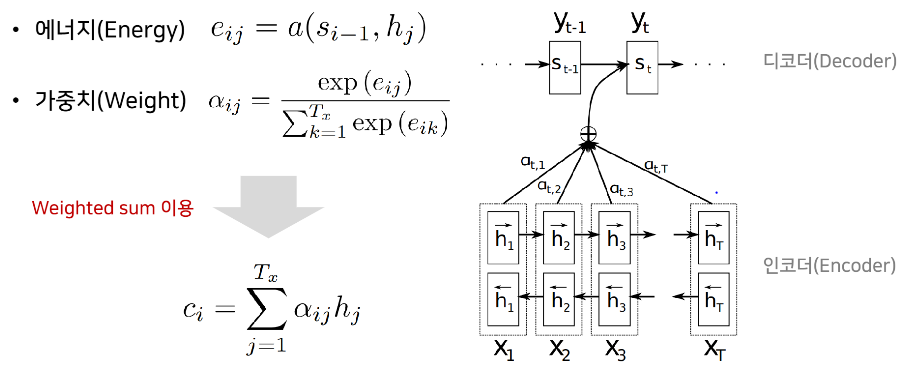
- i = 현재 디코더가 처리중인 인덱스. 디코더가 매번 한 번에 하나의 단어를 만드는데, 각각의 처리 중인 인덱스가 i
- j = 인코더 파트에서 출력 인덱스.
- 에너지 = 디코더가 하나의 출력 단어를 생성할 때 소스 문장에서 나왔던 인코더의 모든 출력 값 중 어떤 값과 가장 연관성이 있는지 구하기 위해 수치화한 값
si-1 = 디코더가 이전의 출력을 만들기 위해 사용했던 hidden state
hj = 인코더 파트의 각각의 hidden state - 에너지 수식 살펴보면, 디코더 파트에서 내가 이전에 출력했던 정보는 s i-1 인데, 이 정보와 인코더의 모든 출력 값 hj 와 비교해서 에너지 값을 구하겠다는 것
예시)
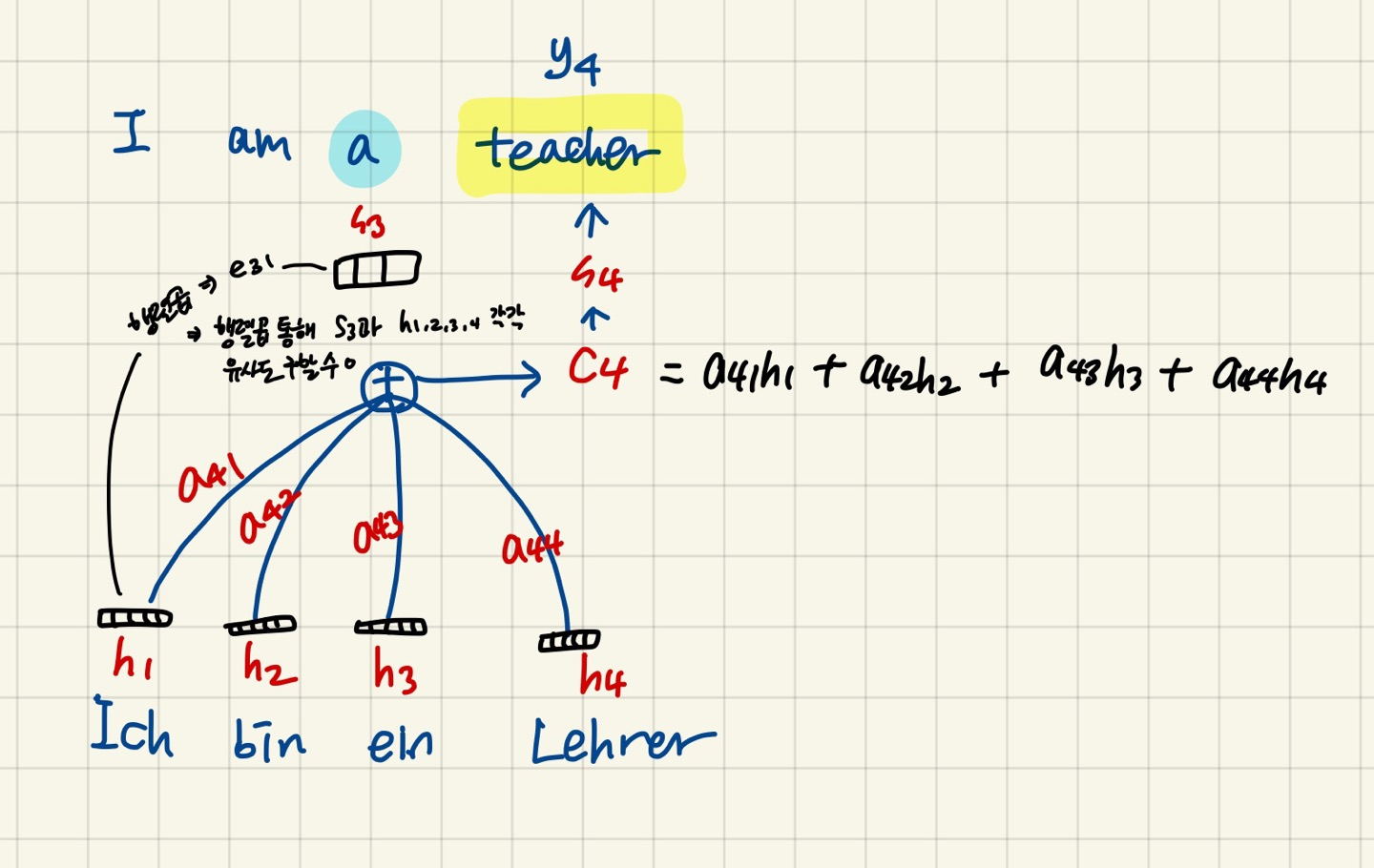
- 예를 들어, I / am / a / teacher 에 해당되는 독일어 입력 문장을 I / am / a / teacher 영어 문장으로 출력 하는 task
- 현재 I am a 까지 디코딩하고 teacher 을 출력할 차례라고 하자.
- teacher 이라는 y4 를 출력하기 위한 hidden state s4는 teacher 를 출력하기 위해 소스 문장에서 출력되었던 모든 hidden state 값들인 h1, h2, h3, h4 를 참고할 것이다.
- 그 중 어떤 값에 집중해서 참조할건지 계산하기 위해, s 3 과 h1, h2, h3, h4 사이 각각의 에너지 값 구하기
(현재 내 hidden state s4 를 모르니까 바로 전인 s3 과의 연관성 에너지 값 구함)
- e41(s3과 h1 연관성 계산한 행렬곱 에너지값), e42(s3과 h2 연관성 계산한 행렬곱 에너지값), e43(s3과 h3 연관성 계산한 행렬곱 에너지값), e44(s3과 h4 연관성 계산한 행렬곱 에너지값) 계산
- a41 = e 41 / ( e41 + e42 + e43 + e44 ) 해서 a41, a42, a43, a44 구하기
- 위의 가중치들과 h1, h2, h3, h4 각각 곱해고 최종적으로 더해서 디코더 인풋인 c4 구하기
- c4 를 디코더에 넣어 출력값 y4 (teacher) 출력하기
- 즉 어떤 h 값과 가장 많은 연관성을 가지는지를 에너지 값으로 구할 수 있는 것
- 이 에너지 값에 소프트맥스를 취해서 확률 값을 구한게 가중치(weight)
- 비율적으로 각각의 h 값 중에서 어떤 값과 가장 연관성이 높은지 구함. - ci : 그 가중치(aij)를 실제로 h 값(hj)과 곱해서 각각의 가중치가 반영된 인코더의 출력값을 더해서 디코더의 입력(ci)으로 활용
- 즉, s t 를 만들기 위해 s t-1 과 인코더 파트의 모든 각각의 hidden state 값 묶어서 에너지 값 구한 후 softmax 취해서 비율 값 구할 수 있음
- 그 비율 값이 각각 a ij.
- 예를 들어 I am a teacher 입력 문장에 대해 I / am / a / teacher 중에서 어떤 값에 집중해야하는지.
I 70%, am 20%, a 5%, teacher 5% . 다 더했을 때 100% 되도록 - 그 비율만큼 h 와 곱해서 마지막 c 만듦
Attention 추가적인 장점
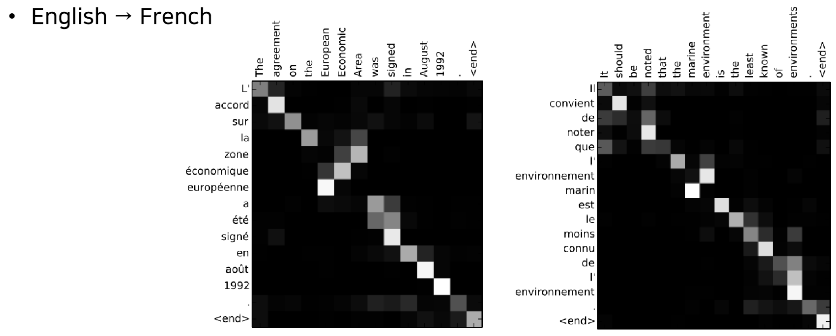
- 어텐션 시각화 - 어텐션 가중치 (위에서 구했던 a) 를 이용해서 매번 출력이 나올 때마다 그 출력이 입력에서 어떤 정보를 참고했는지를 구할 수 있음
- 각각의 단어들이 있을 때 불어의 단어들을 출력할 때마다 입력 영어 단어의 어떤 단어에 가장 큰 초점을 뒀는지 확인 가능.
밝게 표시된 부분이 확률 값 높은 부분 - 딥러닝은 매우 많은 파라미터를 가지고 있어서 세부적인 파라미터들을 일일이 분석하면서 어떤 원리로 동작했는지 알아내기는 쉽지 않음
- 어텐션 메커니즘 - 실제로 딥러닝이 어떤 요소에 더욱 더 많은 초점을 두고 분류 or 데이터 생성 등의 과정을 분석할 때 용이하게 작용할 수 있음
Reference
'Deep Learning' 카테고리의 다른 글
| 트랜스포머(Transformer) (4) - 인코더와 디코더 (1) | 2022.06.04 |
|---|---|
| 트랜스포머(Transformer) (3) - 구조, 동작원리, 포지셔널 인코딩(Positional Encoding), 어텐션(Attention) (0) | 2022.06.04 |
| 트랜스포머(Transformer) (1) - Seq2Seq 모델의 한계점 (0) | 2022.06.02 |
| 신경망 출력층 설계하기 (분류, 회귀에 맞는 활성화 함수 선정) (0) | 2022.05.31 |
| 넘파이(numpy)로 신경망 구현하기 최종 코드 (0) | 2022.05.31 |




댓글