이 글은 나동빈님의 'Transformer : Attention Is All You Need' 논문 리뷰 영상을 보고 정리한 글입니다.
트랜스포머 (Transformer - Attention Is All You Need)
- '어텐션' 이라는 메커니즘을 전적으로 활용하는 아키텍쳐
- 많은 최신 자연어 처리 모델이 활용하고 있는 아키텍쳐 - 트랜스포머 제안
- Transformer 의 메인 아이디어는 BERT, GPT 와 같은 최신 아키텍처에 채택되어 Google 번역기, 파파고 등에 활용되고 있음
딥러닝 기반의 기계 번역 발전 과정
- 2021년 기준 최신 고성능 모델들은 트랜스포머 아키텍쳐를 기반으로 하고 있음
- GPT : 트랜스포머의 '디코더(decoder)' 아키텍처 활용
- BERT : 트랜스포머의 '인코더(encoder)' 아키텍처 활용
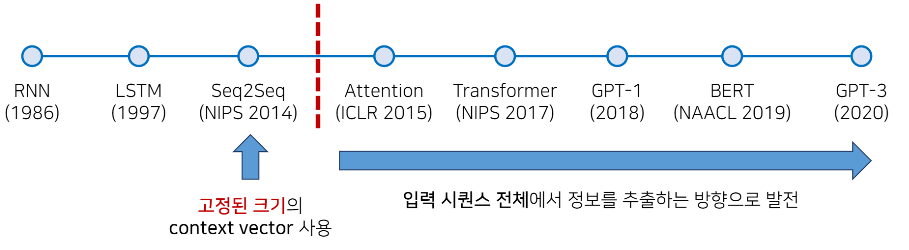
자연어처리 중에서도 핵심인 기계번역을 주로 살펴보면,
- RNN (1986) : RNN 첫 시작. 10년 후 LSTM
- LSTM (1997) : 다양한 시퀀스 정보 모델링 가능 - 주가예측, 주기함수 예측
- Seq2Seq (NIPS 2014)
- LSTM 활용해서 딥러닝 기반 기술로 탄생. 현대의 딥러닝 기술들이 나오던 시점에 탄생.
- LSTM 을 활용해서 고정된 크기의 context vector 를 사용하는 방식으로 번역 수행.
- 따라서 소스 문장을 전부 고정된 크기의 한 벡터에 압축해야 하는 성능적인 한계가 존재했음 - Attention (ICLR 2015) : Seq2Seq 모델에 어텐션 기법 적용하여 성능 더 올릴 수 있었음
- Transformer (NIPS 2017)
- 아예 RNN 자체를 사용할 필요가 없다고 제안.
- 오직 어텐션 기법에 의존하는 아키텍쳐를 설계했더니 성능이 엄청 향상.
- 트랜스포머를 기점으로 자연어 처리 기법으로 RNN 더이상 사용하지 않고 어텐션 메커니즘을 더욱 더 많이 사용
- 어텐션 메커니즘 등장 이후 입력 시퀀스 전체에서 정보를 추출하는 방향으로 연구 방향 발전.
- 어텐션 기법을 활용하는 트랜스포머 아키텍쳐를 따르는 방식으로 다양한 고성능 모델들이 제안되고 있음.
기존 Seq2Seq 모델들의 한계점
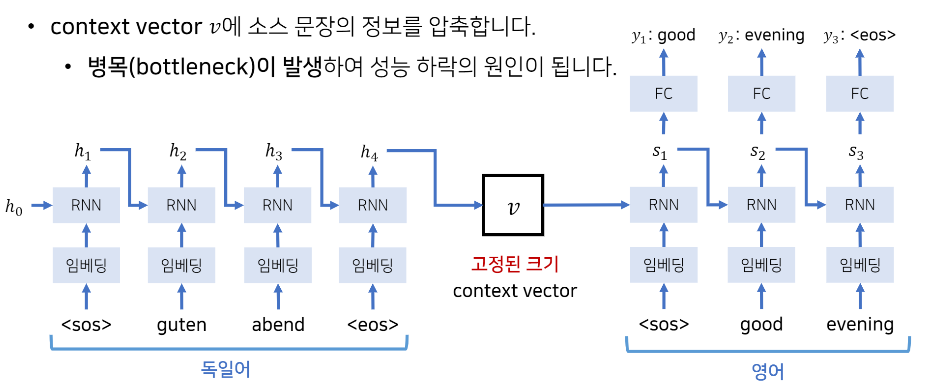
- context vector v 에 소스 문장의 정보를 압축
- 병목현상 (bottleneck) 이 발생하여 성능 하락의 원인이 됨
- 각각의 단어들로 구성된 시퀀스가 들어왔을 때 중간에서 하나의 고정된 크기의 context vector 로 바꾼 뒤, 다시 그 context vector 로부터 출력 문장을 만들어 냄
- 한쪽 시퀀스로부터 다른 한 쪽의 시퀀스를 만들어 낸다는 의미에서 - Seq to Seq
- 단어가 입력될 때마다 이전까지 입력되었던 단어들에 대한 정보를 포함하고 있는 hidden state 값을 받아서 hidden state 값 갱신
- 차례대로 순서에 맞게 단어 입력될 때마다 hidden state 값 갱신
- hidden state 값들은 이전까지 입력되었던 단어들에 대한 정보를 가지고 있음
- 따라서 마지막 단어가 들어왔을 때의 hidden state 값 = 소스 문장 전체를 대표하는 하나의 context vector 로써 사용 가능
- 이 context vector 안에는 앞에 등장했던 소스 문장에 대한 문맥적인 정보를 담고 있다고 가정할 수 있음
Seq2Seq 디코딩 파트
- Decoding : context vector 로부터 출발해서 출력을 수행
- 출력 단어 들어올 때마다 context vector 로부터 매번 hidden state 만들어서 출력 내보냄
ex) <sos> 출력 단어 들어오고 - context vector 로부터 hidden state 's1' 만들어서 그걸 이용해 'good' 출력 내보냄
그리고 그 y1 인 good 이 다시 그 다음 단계에서 입력으로 들어옴 + 이전까지 출력했던 단어에 대한 정보를 가지고 있는 hidden state 's1' 도 같이 입력으로 들어옴 = RNN 처리 후 새로운 hidden state 's2' 로 갱신됨 - 이런식으로 디코더 파트에서는 매번 hidden state 를 갱신하면서 hidden state 값으로부터 출력 값이 <eos> (end of sequence) 가 나올 때까지 이 과정 반복.
- EOS 가 나왔을 때 출력 문장 생성을 마치고 'good evening' 이 결과로 나옴
Seq2Seq 한계점
- 소스 문장을 대표하는 하나의 context vector 를 만들어야 하는데 입력 문장이 짧을 수도 있고 길 수도 있다.
- 이런 다양한 경우의 수가 있는데 항상 고정된 크기의 context vector 를 만들어야 하는건 병목 현상의 원인이 될 수 있음

- 새로운 아이디어 : 고정된 크기의 context vector 을 디코더의 RNN 셀에서 매번 참고하도록 하면 성능이 조금 더 개선됨 (이전에는 맨 첫번째 출력 생성할 때만 context vector 참고하고, 그 이후로는 context vector 가 아닌 새로 생성된 hidden state 를 참고하는 방식)
- context vector 에 대한 정보가 디코더의 RNN 셀을 거침에 따라서 정보가 손실되는 정도를 더 줄일 수 있음
- 따라서 출력되는 문장이 더 길어진다고 할지라도 각각의 출력되는 단어에 context vector 에 대한 정보를 다시 한번 넣어줄 수 있어서 성능이 기존보다 조금 더 향상 될 수 있음
- 다만 여전히 소스 문장을 하나의 벡터에 압축해야한다는 점은 똑같기 때문에 병목현상에 대한 문제는 그대로임.
Seq2Seq 의 문제 : 하나의 문맥 벡터가 소스 문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됨
해결 방안 : 그렇다면 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까?
- 심지어 최신 GPU 는 많은 메모리와 빠른 병렬 처리를 지원하니까.
- 디코더 파트에서 하나의 문맥벡터에 대한 정보만 가지고 있는 것이 아니라, 출력 단어를 만들 때마다 매번 소스 문장에서의 출력 값 전부를 입력으로 받으면 어떨까
- 최신 GPU 사용 - 소스 문장의 시퀀스 길이가 길더라도 그 소스 문장을 구성하는 각각의 단어에 대한 출력값 전부를 특정 행렬에 기록해둠
- 그러면 소스 문장에 대한 전반적인 내용들을 매번 출력할 때마다 반영할 수 있음 - 성능 개선
- 즉, 하나의 고정된 크기의 context vector 에 담지 말고, 그냥 소스 문장에서 나왔던 출력 값 전부를 디코더에서 매번 입력으로 받아서 처리하자.
==> 'Attention' 메커니즘 사용해 인코더의 모든 출력 참고 가능
Reference
- https://www.youtube.com/watch?v=AA621UofTUA
'Deep Learning' 카테고리의 다른 글
| 트랜스포머(Transformer) (3) - 구조, 동작원리, 포지셔널 인코딩(Positional Encoding), 어텐션(Attention) (0) | 2022.06.04 |
|---|---|
| 트랜스포머(Transformer) (2) - Attention 으로 seq2seq 문제 해결 (0) | 2022.06.03 |
| 신경망 출력층 설계하기 (분류, 회귀에 맞는 활성화 함수 선정) (0) | 2022.05.31 |
| 넘파이(numpy)로 신경망 구현하기 최종 코드 (0) | 2022.05.31 |
| 넘파이(numpy)로 신경망 구현하기 (0) | 2022.05.31 |



댓글