기계번역
- 소스언어를 타겟언어로 번역하는 프로그램
- 단순하게 data mapping 하는 문제 + 자연어는 생략과 중의성이 많아 컴퓨터가 이해하기 어렵, 표현도 많아서 훨씬 더 복잡한 문제 + 언어마다 다른 특징
- 기계번역은 NLP 에서 어려운 task 에 속함
- 예전에는 기계번역기 만들 때 많은 resource + 복잡한 규칙 + 많은 통계규칙들 다 활용하여 여러 개의 모듈들을 따로 만들어 합침
- but 최근에 데이터 많아지고 + 딥러닝 등장 = 하나의 모듈에서 모든 일을 처리하는 방식으로 바뀜
- 예전보다는 상대적으로 쉽게 개발 가능
준비물 1 - 오픈소스 : Fairseq

- 기계번역을 위한 여러 오픈 소스 존재
- 그 중 facebook 에서 만든 fairseq
- WMT 라는 기계번역 대회에서 fairseq 가 활발하게 사용되고 있음 + 최근 WMT 대회에서 1등 모델 fairseq 많음
- fairseq : command line 명령어 제공한다는 점이 장점
준비물 2 - 학습 데이터
1) 병렬 데이터
- 소스와 타겟 언어 쌍으로 된 데이터
- AI Hub 개방 데이터 참고
2) 단일 데이터
- 하나의 언어로 된 데이터
- 라벨링되어 있지 않아서 학습 데이터로 바로 사용 불가
- but 단일 데이터가 병렬 데이터보다 양도 많고 상대적으로 쉽게 구할 수 있어서 사용함
- Wikipedia 데이터 참고
기계번역기 만들기
일반적인 텍스트 기반 머신러닝 파이프라인
+ 기계번역은 텍스트 생성하는 단계 = 디코딩 단계 추가
- 크게 보면 데이터 처리, 모델링, 성능평가로 구분됨 - 이 파트들에서 각각 성능 향상 시킬 수 있음
- 이러한 파이프라인 : 왼 -> 오 one way 가 아니라 사이클이 있음
- 사이클을 통해 점진적, 반복적으로 발전해나감
- 전체를 감싸는 cycle : 데이터 준비부터 성능 평가까지 쭉 + 다시 돌아와 보완하면서 최종적으로 성능 높임
- 기계번역의 경우 작은 cycle 추가
- 병렬 데이터로 최초 학습, 학습된 모델을 base model 이라고 함
- 학습 데이터가 병렬 데이터인 특성을 활용 : 데이터 정제, 데이터 확장 가능
- 학습된 base model 통해서 의미적으로 번역해서 병렬 데이터의 노이즈를 걸러낼 수 있음
- 단일어 데이터를 번역해서 병렬 데이터로 만들어 낼 수 있음 - 데이터 양과 품질을 높일 수 있음
- 이런 것들을 통해서 데이터 확장, 정제 등 모으고 모아서 성능 더 높일 수 있음
fairseq 설치
- git clone https//github.com/pytorch/fairseq 와 pip install 을 통해 설치
학습 데이터 준비
- bitext.ko-ja.tsv 처럼 한국어, 일본어 pair 로 되어 있는 병렬 데이터를 텍스트 처리하여 train.ko, train.ja 로 분할해서 저장
- 텍스트 처리 : 위 예시에서는 간단하게 음절 단위로 나눔 + 추가적으로 정규화, 필터링, 좋은 토크나이저 등으로 보완 가능
fairseq-preprocess
- 텍스트 형태로 그대로 사용 X, binary 형태로 변환해주어야함
- 데이터를 바이너리로 변환, 딕셔너리 구축
- 빠른 로딩 속도와 압축 효과
fairseq-train
fairseq-train 이라는 짧은 명령어로 학습 가능

- 학습 파라미터 : https://fairseq.readthedocs.io/en/latest/command_line_tools.html#fairseq-train
- 모델 아키텍쳐 (--arch) : https://github.com/pytorch/fairseq/tree/main/fairseq/models
- 여기서는 가장 기본 transformer 사용했지만, 위 링크에서 최신 모델 업데이트 잘 되니 최신 모델 사용 가능
- 훈련 결과는 매 epoch 마다 checkpoint 생성됨

앙상블(Ensemble) - checkpoint averaging
- 마지막 checkpoint 를 가지고 추론에 사용해도 되지만, 앙상블을 통해 조금 더 성능 높일 수 있음
- 다양한 종류의 앙상블 중 가장 단순한 - 여러 개의 checkpoint weight 평균내기
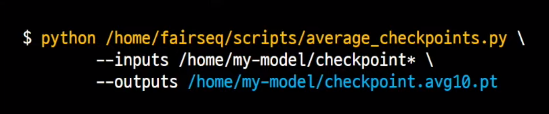
- fairseq 에서 제공하는 average_checkpooints.py 통해 가능
파인 튜닝(Fine-tuning)
한번 더 모델링 할 수 있는 부분
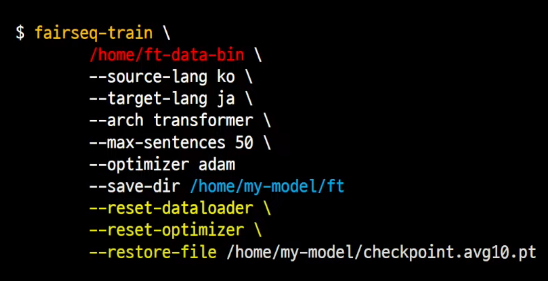
데이터를 모으다 유독 품질이 좋은 데이터가 있을 때 or 상황에 맞게 domain 데이터만 사용하고 싶을 때
- 부분적인 data 로 학습을 한번 더 진행해주는 것이 fine-tuning
- 원래 fine-tuning 은 모델의 최상단에 있는 classifier layer 만 재 학습, but 여기서 학습하는 트랜스포머 구조 상 end-to-end 매핑이기 때문에 - 전체를 아예 다시 학습함 = 따라서 아까 fairseq-train 의 명령어 다시 사용
but 인자가 달라짐 - dataloader, optimizer 추가, 결과저장 경로 수정
- 앙상블, 파인 튜닝 필수는 아님. 상황에 따라 득이 될 수도 아닐 수도 있기 때문에 적절히 잘 선택
학습 후 번역 결과 확인
확인 명령어 두가지
1) fairseq-interactive
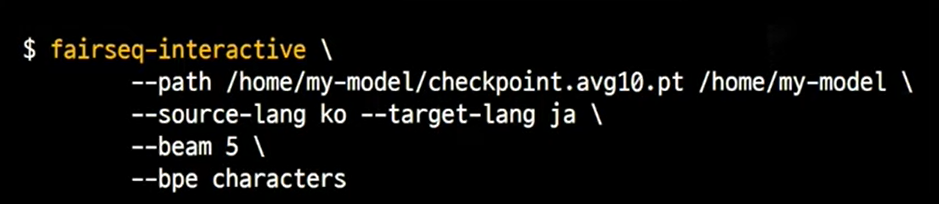
- raw text 번역
- 사용자가 interactive 하게 raw text 데이터를 하나씩 확인해볼 수 있음
2) fairseq-generate
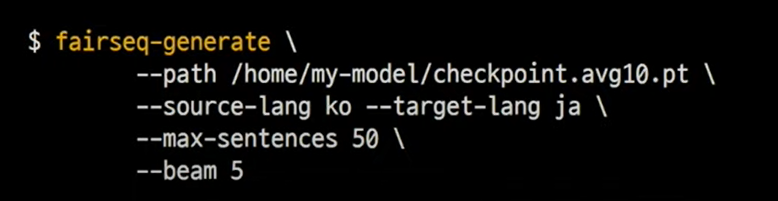
- pre-processed text 번역 & 배치모드
- 대량의 데이터를 한번에 번역할 수 있음
- binary 데이터를 입력으로 받기 때문에 앞의 pre-process 명령어와 함께 사용해야 함
모델 성능 확인
fairseq-score
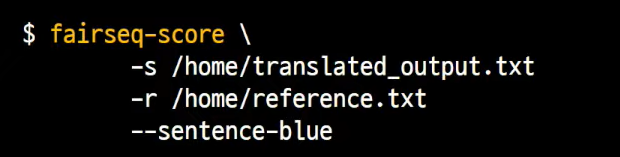
BLEU Score
- 텍스트를 n-gram 단위로 다 쪼개고, 정답과 출력이 얼마나 많이 겹치느냐에 따라 점수를 매기는 방식
- BLEU(Bilngual Evaluation Understudy)
- 기계번역 정량 평가 지표
- n-gram 기반 점수 측정 & 페널티 (중복 토큰, 짧은 문장 길이)
추가) 데이터 정제
병렬 데이터 의미적으로 판단하여 정제
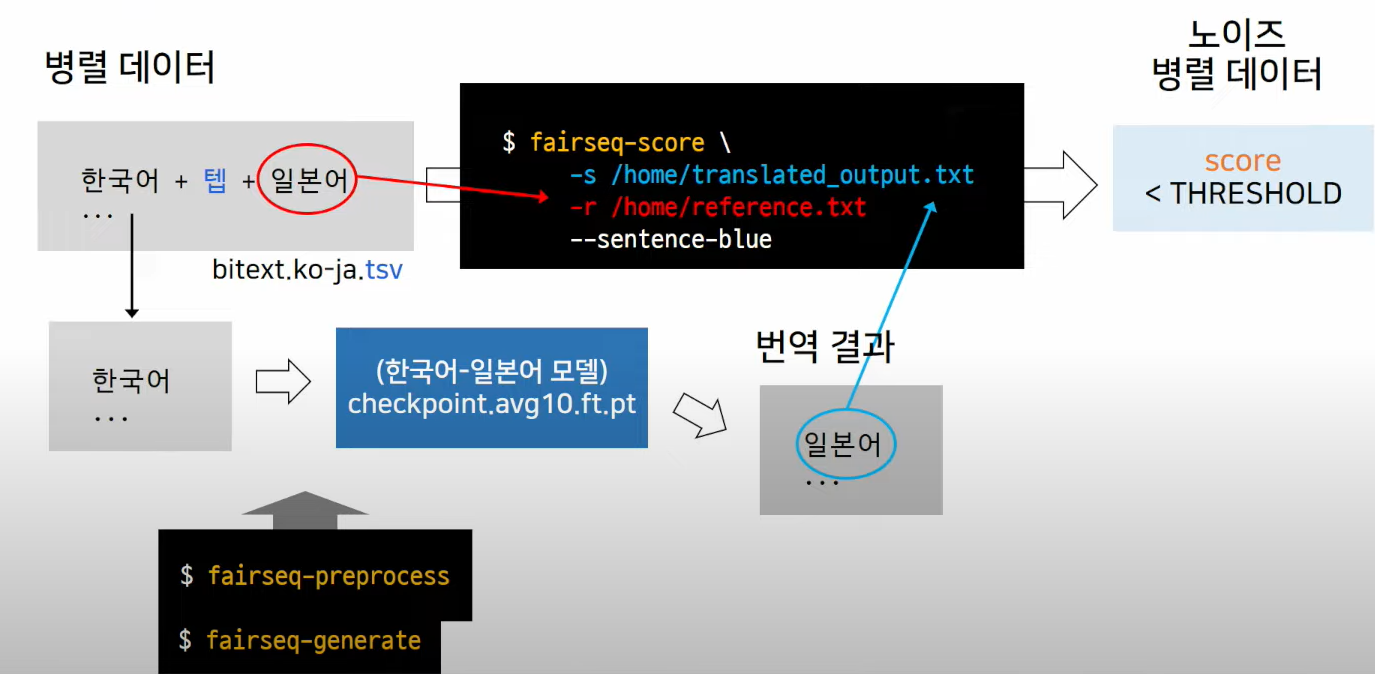
- 병렬 데이터에서 소스 언어만 추출해서 번역 - 다시 병렬 데이터의 타겟 언어와 번역된 결과를 비교해서 BLEU 스코어 측정 - 측정된 점수가 낮으면 noise
- 인터넷에 돌아다니는 데이터로 실험 - 평균적으로 약 3.5% 가 오번역 / noise data로 찾아낼 수 있었음
추가) 데이터 확장(back-translation)
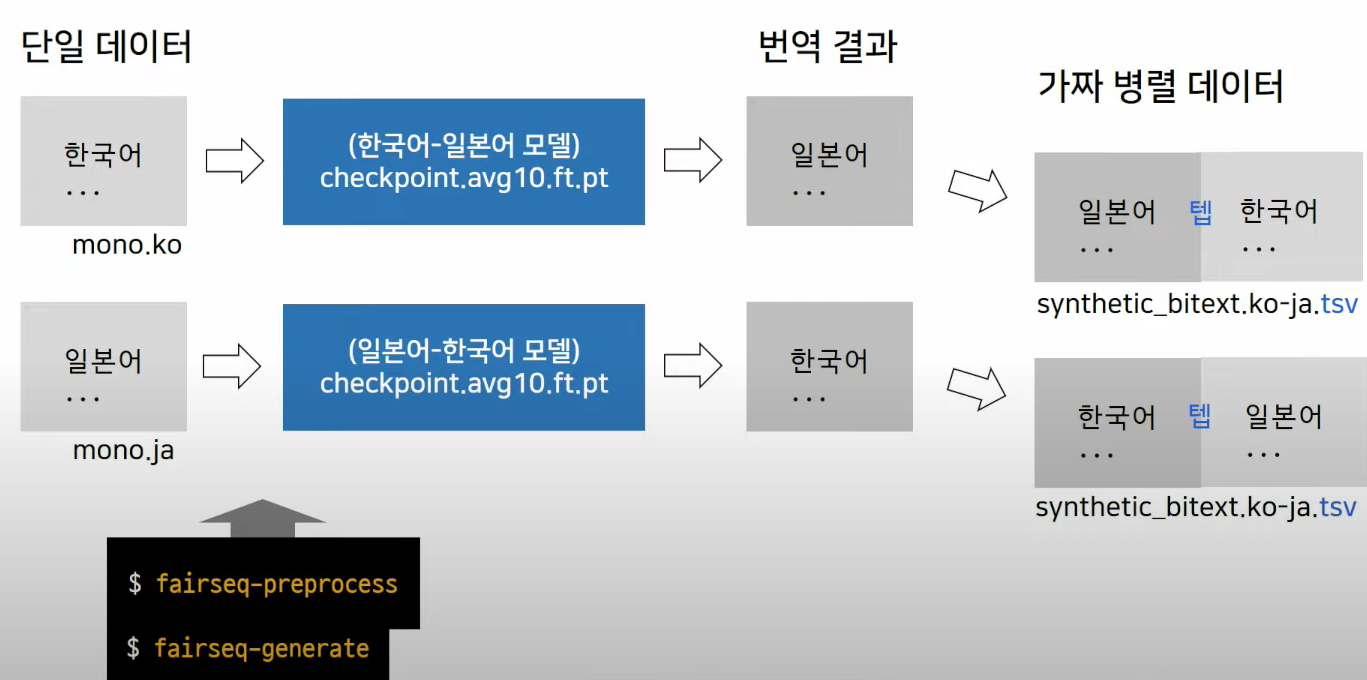
단일어 데이터를 모델 통해 그냥 번역 - 그걸 병렬데이터라고 간주하고 사용하는 simple 한 idea
한쪽 언어만 real data - 따라서 생성된 데이터를 가짜 병렬 데이터에서 target 언어에 위치하도록 해야함
- 학습된 모델이 문자열을 생성할 때 조금 더 자연스럽게 연이어서 생성할 수 있도록 도움
- 즉, 모델의 유창성 능력을 키우게 해줌
이 process 를 위해 따로 코딩이 아니라 기존 fairseq 명령어들 사용하면 가능
Reference
'Spoken Language Processing' 카테고리의 다른 글
| 음성언어처리, 인간의 청지각과정, 베이즈정리, HMM 에 대하여 (0) | 2022.03.10 |
|---|---|
| 한국어 음성인식에 대해서 (0) | 2022.03.10 |
| 음성인식(Speech recognition) 이란? (0) | 2022.03.04 |
| 음성언어의 구조 - (2) 말소리의 생성 과정 (0) | 2021.12.19 |
| 음성언어의 구조 - (1) 말소리의 생성 과정 (0) | 2021.12.15 |



댓글