Human Speech Production Mechanism
acoustic system : 말소리를 만들어내는 기관 - 조음기관

위 그림은 횡격막에서 허파, 그리고 성대까지의 그림이다.
- diaphragm 횡격막 : 갈비뼈 밑 부분
- 횡격막이 피스톤 운동을 하면서 air pressure 를 성대쪽으로 불어넣음
- 그 후 인강, 비강, 구강 소리통에서 소리가 울림
ex) 바이올린 & 첼로 - 모양 비슷 + 현으로 킨다는 공통점
- 바이올린과 첼로 각각의 나무통이 각각의 소리통
- 동굴 속에서 아~ 하면 소리가 울리는것처럼 sound source 에서 소리 입력이 들어오고 공기의 움직임을 자극하면 소리통 안에서 소리가 울리게 됨
- 울리는 패턴에 따라 바이올린, 첼로의 소리가 남
- 현이 달라서라기보다 소리통의 구조가 달라서 소리가 다르게 나는 것
인간의 목소리도 마찬가지이다.
아래 그림의 소리통 모양이 어떻게 변하느냐에 따라서 바이올린, 첼로 소리처럼 소리가 달라진다.
- 아~, 어~, 에~, 크~ 등등 자음, 모음의 소리 값을 갖는, 즉 우리들이 구별할 수 있는 소리 값들이 이 소리 통에서 소리가 어떻게 울리느냐에 따라 달라진다.
- 입력으로 횡격막이 주기적인 압력을 성대쪽으로 불어넣을 때 어떤 식으로 소리 입력을 넣어주냐에 따라서 소리 값이 달라진다.
아~ : 하면 떨린다
크~ : 하면 안떨린다
아래 모델은 소리가 만들어지는 과정을 보여준다.
- 모델의 모든 파라미터들이 개별적인 소리 값마다 다 다름
- 허파는 위 그림처럼 실린더로 생각할 수 있다.
- 허파가 실린더이고, 횡격막이 피스톤이다.
- 소리를 말하려면, 성대를 떨리게 하든, 안떨리게 하든, 성대쪽으로 통과하는 공기압력이 입술 쪽으로 올라가야한다.
그럼 그 공기압력은 어떻게 만들어지는 것일까?
- 횡격막이 왔다 갔다 피스톤 작용을 하면서 공기를 성대 쪽으로 불어 넣는 것이다.
성도 (vocal tract) : 소리가 지나가는 길
성대~입술 (위 그림은 튜브로 모델링)
- 단면적이 일정하지 않음
- 소리가 울리는 공간인 소리통이 존재
- '인강', 입안의 '구강', 코의 '비강' 의 소리통들
- 횡격막이 피스톤 운동을 해서 공기 압력 변화를 성대 쪽으로 불어 넣으면 "아~" 하면서 성대가 떨림
- 이 때 성대가 떨리는 것은 공기 압력이 성대(vocal folds) 를 밀치고 올라가면서 생긴다.
- 성대(vocal folds)가 밑으로 내려와있어 소리가 통과하는 길인 성도를 막고 있고, 이를 공기압력이 지나가면서 성대를 밀치고 올라가서 성대를 떨리게 한다.
- 이렇게 성대를 떨리게 하는 소리를 "유성음" 이라고 한다.
"크~" 소리를 낼 때는 성대가 떨리지 않는다.
- 성대(vocal folds) 가 관 있는 곳에 딱 붙어있어서 공기 압력이 성도를 통과할 때 그냥 통과하면서 성대를 울리지 않는 것이다.
- 이렇게 성대를 떨리지 않는 소리를 "무성음" 이라고 한다.
- 유성음은 주로 모음이고, 자음 중 유성 자음(성대를 떨리게 하면서 나타나는 자음)이 있다.
- 무성음은 주로 자음이다.
공기 압력이 성대를 통과한 후 인강, 구강, 비강 등의 소리가 울리는 소리통에서 소리를 울리면 소리 값을 갖게 되는 것이다.
- 성도는 단일한 튜브가 아니라 중간에 소리가 울리는 구간들이 있음
- 그 구간들을 그것보다 단면적이 더 좁은 튜브로 연결되어 있는 구조
중간에 '연구개(velum)' 가 존재한다.
- 아~ 하고 거울을 보면 목젖이 보이는데, 그게 연구개이다.
- 코로 들어가는 소리의 통로를 열고 닫는 벨브의 역할을 한다.
- 연구개가 닫히면 코로 들어가는 벨브가 닫혀 비강 쪽으로 소리가 안 올라간다. 그럼 그냥 인강, 구강, 즉 입 안에서만 소리가 울려 입술 밖으로 나가게 된다.
- 연구개가 열리면 공기압력이 성대에서 인강을 거쳐 올라오다가 비강을 통해 코로도 갈 수 있다.
--> 콧소리를 낼 때 이 연구개, 벨브가 열려서 코로 소리가 날 수 있고, 이렇게 해서 나는 소리를 '비음' 이라고 한다.
말소리의 생성과정

1. 발동 (initiation)
- 말소리가 만들어질 때 initiation 단계는 폐에서 air steam 이 만들어짐.
- 폐에서 만들어진다는 것 : 위 그림의 muscle force 에 의해서 피스톤이 움직임 - 횡격막이 움직임 - 허파에서 바람을 짜내서 주기적인 공기 압력의 변화가 성대로 올라감 - 이게 initiation 발동 단계
- 아직 말소리의 성격을 띠고 있지는 않음
2. 발성 (phonation)
- 성대를 울리느냐 안울리느냐에 따라서 1차적으로 변형이 됨
- 유성음(성대를 울리는 소리)이냐 무성음(성대를 울리지 않는 소리)이냐
- 성대의 작용에 의해서 air stream 이 1차적으로 변형됨
- 말소리의 기본 성격을 띠게 됨.
3. 조음 (articulation)
- 성도 (vocal tract) : 성대 ~ 입술 까지의 구간으로 소리가 지나가는 길
- 여기서 울리면서 소리값을 가지게 됨.
- 즉 2차 변형이 생기게 되고 이것에 따라서 우리가 알아듣는 구체적인 말소리의 소리값이 만들어지게 됨.
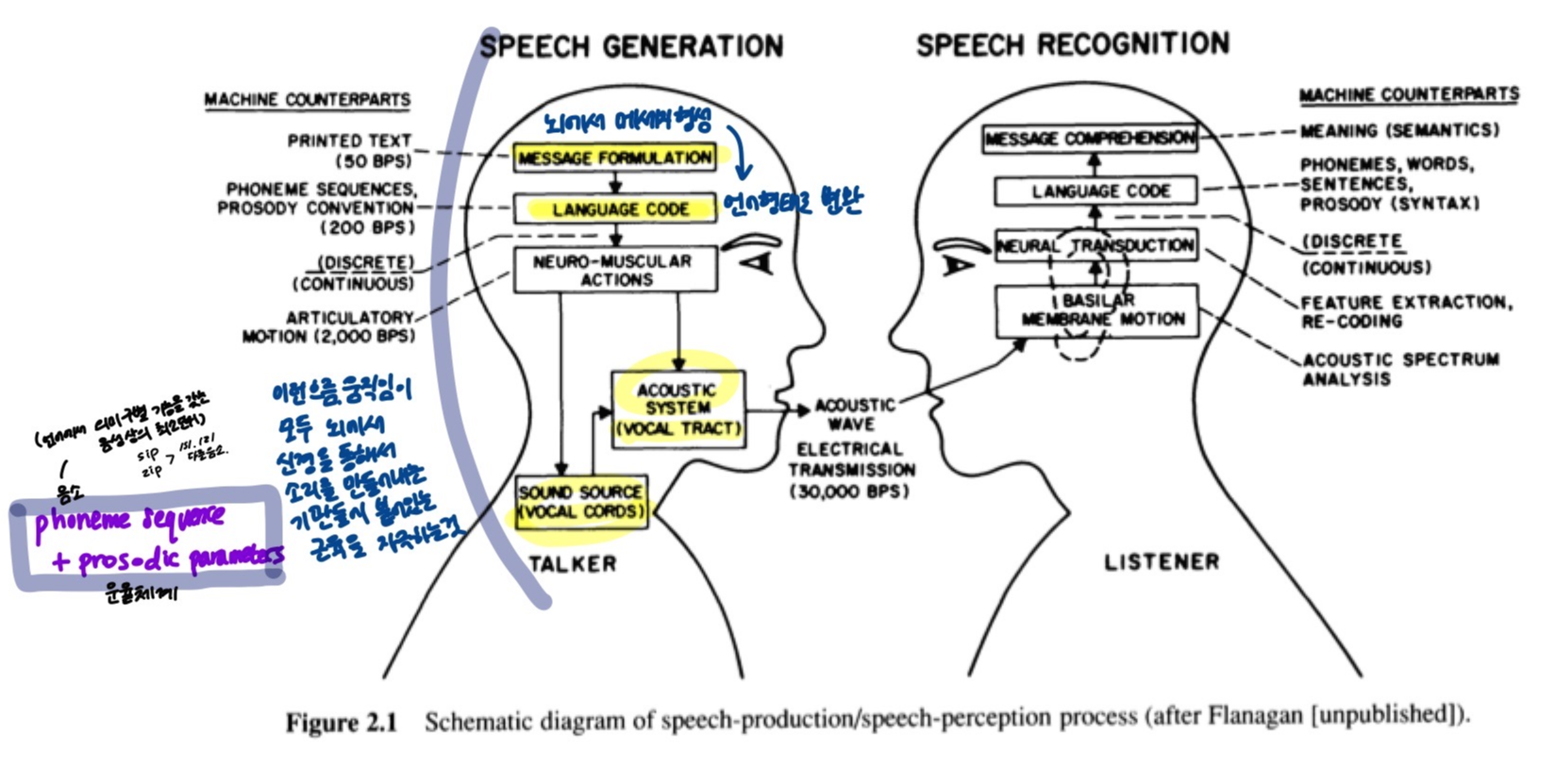
우리들이 생각하고 있는 자음, 모음
- 머릿속에 모델이 되어있는 소리들이고 다 각각의 소리값을 가지고 있음
- 소리를 만들어내는 과정에서 모양이 다 다름.
- 피스톤이 어떤 주파수로 움직이면서 air pressure 만들어내는지
- 성대가 울리는지 안울리는지
- vocal tract 소리통의 모양
Phoneme (음소)
- 음성학을 배웠다면 음소 = 분절음. 어느 정해진 구간 내에서 어떤 특성을 가지고 있느냐에 따라 나누는 것이 음소.
- 음소는 개별 분절 단위라면, 운율은 넓은 구간에 걸쳐서 말소리들이 가지고 있는 특성을 설명할 때 사용
- 분절음 = segmental phoneme --> 이게 phoneme
- 초분절음소 = suprasegmental phoneme --> '분절음소'보다 더 초월한(supra) 요소인 초분절음소
Prosody (운율)
- intonation(억양), accent 를 어디에 줘서 문장을 얘기하냐
- 빨리 말하기 / 늦게 말하기 / duration 다르게 말하기
- 높은 소리 / 낮은 소리 / 고저 / 장단 / 강약 / 자체적인 억양 패턴 등등
- 분절음 단위에서 만들어지는 특성이 아니라 조금 더 긴 구간에 걸친 말소리의 특성
조음기관이 움직이는 것을 얘기한다면 분절음, phoneme
조음기관이 움직이는데 긴 시간에 걸쳐서 어떤 패턴을 형성하면서 움직이는 것을 얘기한다면, prosody parameter.
말소리는 어떻게 해서 만들어지는가?
- 뇌에서 language code 가 생성되면, sound source, vocal cord, vocal tract 의 신경 움직임을 통해 소리를 만들어내는 기관들에 붙어있는 근육들을 자극
- sound source : 횡격막에서 허파
- vocal cord : 성대에서 vocal tract - 자극을 받은 근육들이 수축 이완
- 뇌에서 메세지를 형성 - 소리를 언어 형태로 변환
- 맨 마지막 단계는 phoneme sequence
- 조음기관은 phoneme 별로 달리 움직이기 때문에 맨 마지막 단계는 phoneme sequence 임. - language code 의 맨 마지막 단계는 phoneme sequence 와 prosodic parameters 로 생각할 수 있음.
- 실제로 사람이 말소리를 어떻게 만들어내는가에 대해 알아낸 결과라고 할 수 있음.
- 머릿 속에서 메세지가 형성되면 어떤 식으로던간에 language code 로 변환이 됨.
언어학 기초 이론을 하위에서 상위로 살펴보자.
phonetics(음성학) - phonology(음운체계) - morphology(형태론) - syntax(구문론, 통사론) - semantics(의미론)
- speech signal 로부터 의미까지 연결하는 과정이 언어 현상을 설명하는 이론.
- 뇌에서의 메세지가 실제 말소리를 만들어내기 위한 여러 언어 현상 단계들이 실제로 존재하는가에 대해 여러 연구들이 진행되고 있음.
- 그리고 실제로 여러 언어 현상들을 설명하는 증거자료들도 많이 나오고 있음.
- 그렇지만 뇌에서 high 레벨의 언어 현상을 설명할 수 있는 원칙은 아직 발견된 것이 없음.
- 하지만 low 레벨에 있어서 낮은 수준에서는 말소리가 만들어지는 기계적인 메커니즘은 우리가 잘 알고 있음.
- 조음기관이 움직여서 소리 값을 만들어내는데, 소리 값이 만들어질 때 '발동-발성-조음' 과정을 통해서 이루어지고, 이 과정에서 이루어지는 모든 것들이 다 파라미터임.
- 이 파라미터가 소리마다 다 다름.
- 연구자들은 뇌에서 메세지들이 결국 다 이런 파라미터들도 변환이 되어서 조음기관을 물리적으로 움직여서 말소리가 나오는게 아닌가 추측하고 있음.
지금까지 말소리 생성 과정을 알아보았다면, 이 과정을 참고하여 음성 합성기를 만들어볼 수 있다.
- 음성인식기 - 말소리가 만들어지는 과정을 역으로 추적해보기
- 바깥으로 나온 speech signal 로부터 조음기관들이 어떻게 움직였는지 parameter 들을 역으로 알아내는 것.
ex) 조음기관이 이렇게 움직이면 큰 소리가 나오는 거니까 이 speech signal 은 크다. 라는 식으로 생각
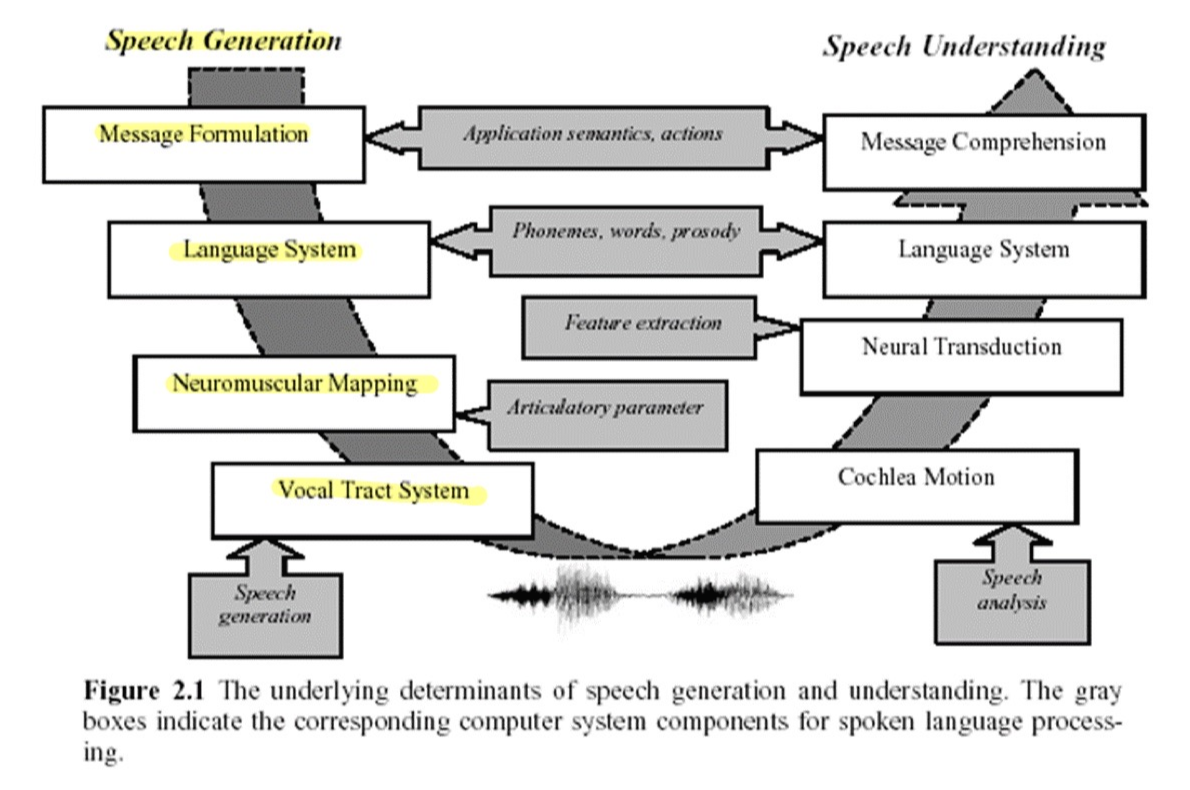
- 말소리 생성 과정을 기반으로 생각해보면,
- speech generation - message formulation - language system - neuromuscular mapping 이라고 생각하면 됨.
- 신경을 타고 근육에 명령이 내려지고, 운동기관에 의해서 vocal tract system 이 작동하여 speech sound 생성
- 실제 뇌에서 조음 기관에 관련된 여러 장기들을 움직이는 근육 = motor nerves (운동신경)
- 초신경을 통해서 근육을 자극해 조음기관을 움직이는 것임 - 그렇게 해서 sound wave 가 나옴
Speech Chain
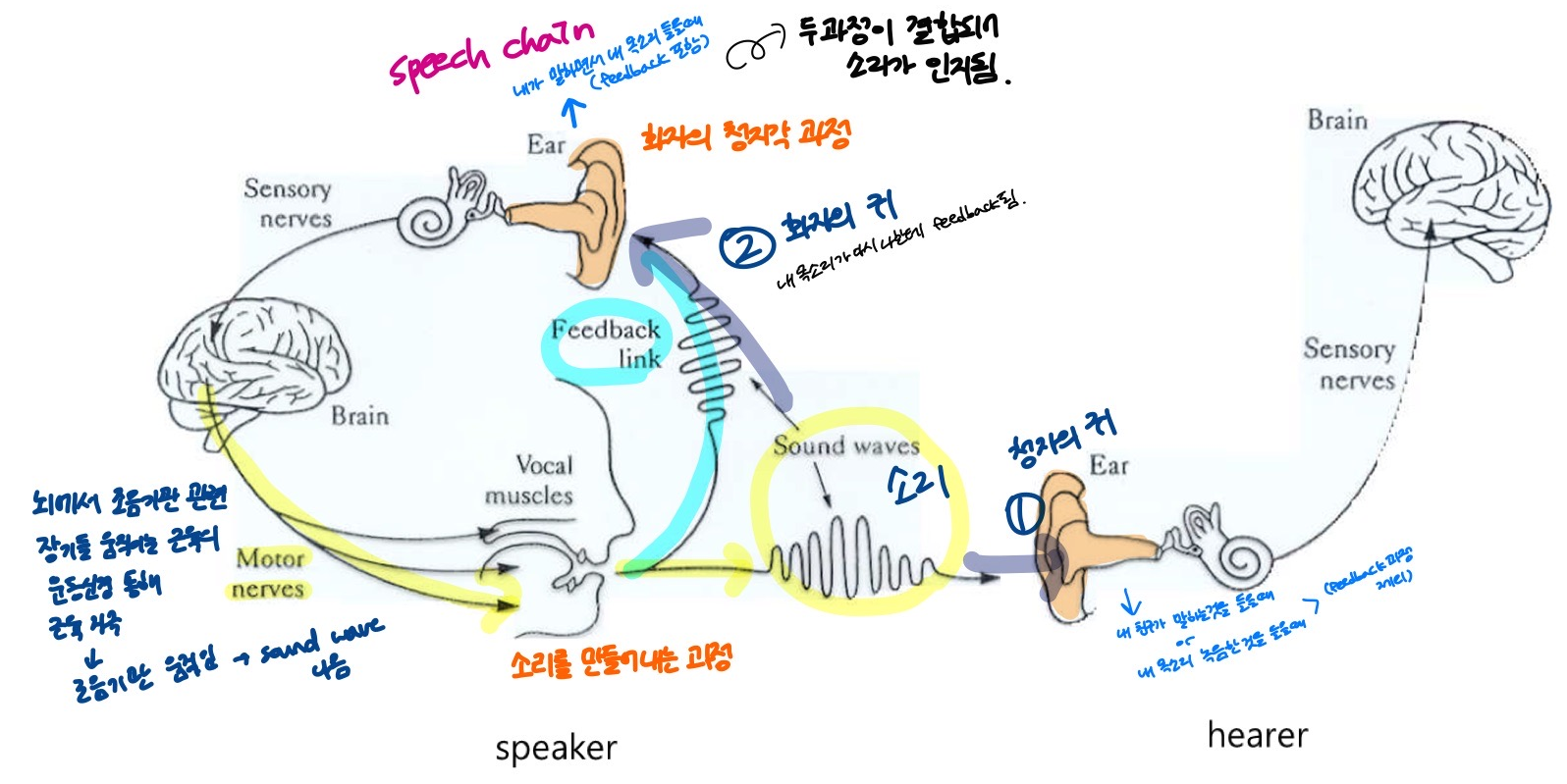
실제로 소리는 1) 청자의 귀를 통해 전해지기도 하고, 2) 화자의 귀를 통해 내 목소리가 다시 나한테 feedback 이 되기도 함.
- 내가 말소리를 만들어 내는데에 있어서도 feedback 자극이 옴.
- 내가 말한 소리가 어떤 소리인지 인식하는데에 있어서 < 소리를 만들어내는 과정 + 화자의 청지각 과정 > 이 결합이 되어서 소리가 인지가 되고, 이게 speech chain 임.
- 전화기를 통해 친구의 목소리를 들을 때나 대화를 하면서 친구 목소리를 들었을 때, 내가 생각하는 친구의 목소리와 친구 본인이 생각하는 본인 목소리가 다름.
- 다른 사람이 말하는 소리를 들을 때는 내 귀로 들어오는 자극이 아니라, 남의 입을 통해 들어온 것을 내 귀를 통해 듣는 소리만 듣기 때문.
- 녹음의 경우에도 이 경우. 동시에 들었을 때와 다르게 1) 의 청자의 귀로 듣는 것과 같음.
- 즉, 내 귀를 통해 feedback 한 2) 의 소리가 빠져있는 것임.
- 내 목소리를 녹음해서 들었을 때와 말하면서 동시에 들었을 때가 또 다름.
- 말하면서 동시에 내 목소리를 들을 때는 내가 내 귀를 통해 들리는 소리를 같이 들음 == 1) & 2)
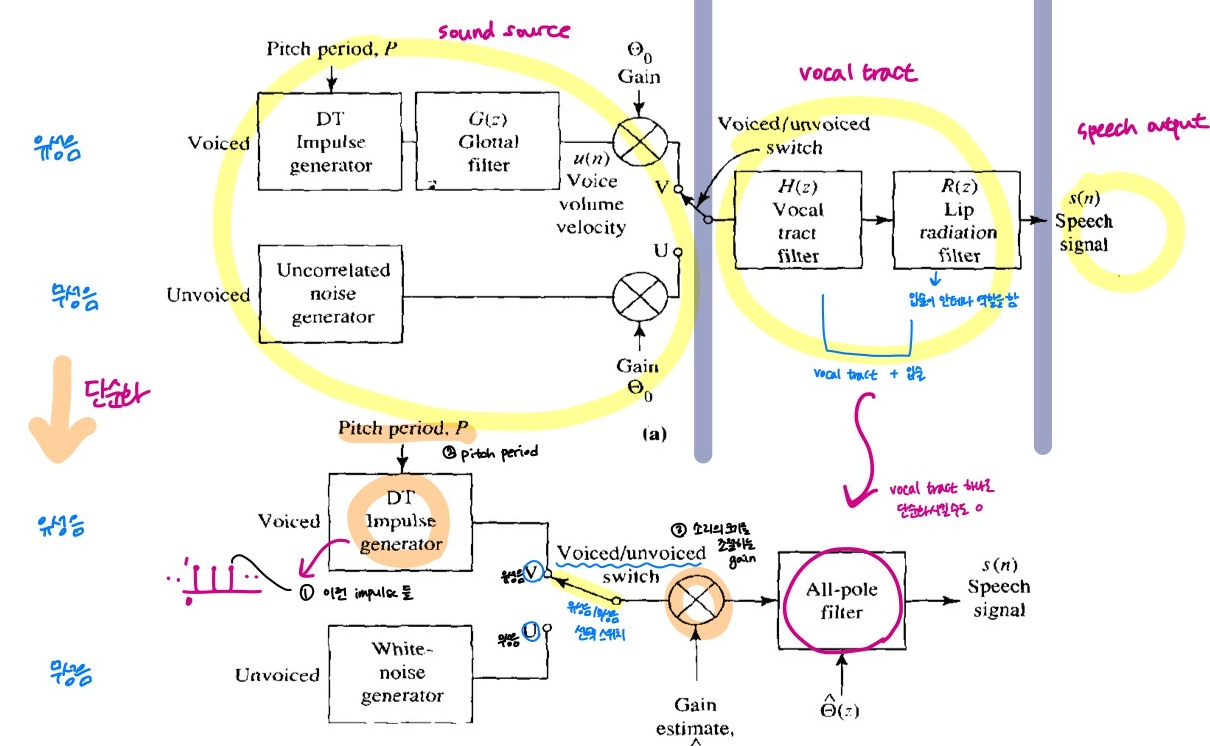
- 첫번째 그림은 소리를 만들어내는 과정을 설명하는 모델.
- 두번째 그림은 첫번째 그림을 block diagram 으로 굉장히 단순화시킨 계산 모델.
- 아날로그 신호처리를 할 때는, 이 모델들을 흉내낼 수 있는 전자회로를 만들어서 실제 소리를 만들어냈었음.
- 컴퓨터로 신호처리를 할 때는, 디지털 시스템에다가 위 과정들에 대한 수학적인 모델을 바탕으로 디지털 필터같은 필터들을 설계해서 수학적으로 모델링하여 사용함.
친구와 핸드폰으로 통화할 때
나의 목소리
- 내 폰 마이크를 통해 소리가 들어옴 - 디지털 신호로 변환 - 안테나 - 통신망 - 친구 폰 (X)
- 이런 식으로 말소리를 디지털 신호로 변환한 것을 그대로 전달하지 않음.
- 한 번 더 변환 과정을 거침
- mp3 음악 파일을 CD로 들을 때 vs mp3 파일 그대로 들을 때 큰 차이가 남
- 1/10 이하로 파일 크기가 굉장히 줄어듦.
- 데이터가 압축됨 - 똑같은 정보를 유지하면서 그걸 나타내는데 쓰이는 디지털 데이터의 양을 줄이는 것을 '코딩' 이라고 함.
= 인코딩 부호화 - 목소리 - 디지털 데이터로 변환 - 폰으로 보내려고 할 때, 데이터 양을 줄임
우리의 목소리를 디지털데이터로 바꾼 후 전화기를 통해서 보낼 때 데이터양을 줄임. 통신채널은 안테나를 통해 전파가 전달되어서 갈텐데, 고속도로 차선처럼 생각하면 됨. 4차선도로, 8차선도로. 4차선은 4대, 8차선은 8대. 데이터는 4대가 다닐 수 있는 전파가 다닐 수 있는 채널이 있음. 데이터 압축해서 차 크기를 줄여서 40대가 다닐 수 있게 하면 똑같은 고속도로 너비에 40차선으로 만들 수 있음. 이게 인코딩임. 디지털데이터를 그냥 보내는게 아니라 mp3 파일로 압축하는 것처럼 음성통신에서도 사람의 목소리를 압축해서. 나중에 사람의 목소리 되살릴 수 있는 파라미터를 중심으로 해서 사람의 목소리 압축해서 데이터 양 줄여서 보냄.
친구의 폰에서 데이터가 오면, 소리를 어떻게 압축했는지 사전약속으로 알고 잇으니, 거꾸로 다시 뻥튀기 할 수 있음. 이걸 디코딩. 복호화라고함.
인코딩/디코딩. : 인코딩을 해서 압축해서 보낸 것을 디코딩 통해 원래 모습으로 살려서 보내면 친구의 목소리가 들리는 것임.
인코딩을 할 때 어떤식으로 압축하느냐?
소리를 만들어내는과정을 얘기했는데, 각각의 자음/모음마다 피스톤이 어떤 주파수로 움직이고, 성대가 진동하고/안하고, 소리가 울리는 통은 어떤 모양을 가지면서 변형시키고.. 이런것들을 설명해주는 파라미터.. 여러가지 파라미터 통해서 이 모양을 확실하게 설명할 수 있는 계산 모델링을 함. 음성통신을 할 때는 데이터 전체를 보내는 것이 아니라 파라미터를 보냄. 이런식으로 인코딩 함.
소리가 만들어지는 과정을 계산모델링 한 이것을 음성인식 때만 쓰는 것이 아니라 음성 통신. human to human communication 할 때. 디지털 통신 하면서. 그 때도 이 과정 (위 그림)에 나온 지식을 바탕으로 해서 모델링을 함. 그렇게 해서 데이터 압축을 함.
이 디지털 필터의 파라미터만 보냄. 엄밀하게 얘기하면, 소리를 만들어내는 과정을 흉내낸 파라미터를 보내는 것이 아니라, 소리를 만들어내고 또 청지각 하는 과정을 모델링 한 후 그걸 한번 더 변형한 후 그 파라미터들을 보내는 것임. 이런 것들은 전기전자공학의 음성통신/디지털 통신 전공하는 사람들이 주로 하는 일. 어떻게 해서 압축하고 어떤식으로 표현하는지..
지금 우리들은 그냥 사람이 실제로 어떻게 말을 할까. 머릿속의 메세지가 language code 로 변환되는데, 이것은 phoneme sequences 와 prosody parameters 들로 대표가 되는 그런 language code 로 변환된다. 그리고 이것이 신경을 타서 근육을 자극해서 조음기관(소리를 만들어내는 기관) 을 움직임. 그리고 각각의 소리값마다 조음기관이 어떻게 움직이는지 다 다름. 뇌에서 이것을 다 달리 조절해주는 것임. 조음기관의 파라미터를 기반으로 해서 디지털음성통신도 이루어짐(친구와 전화로 말을 할 때도 조음기관의 파라미터들을 바탕으로 데이터 압축을 해서 함) .
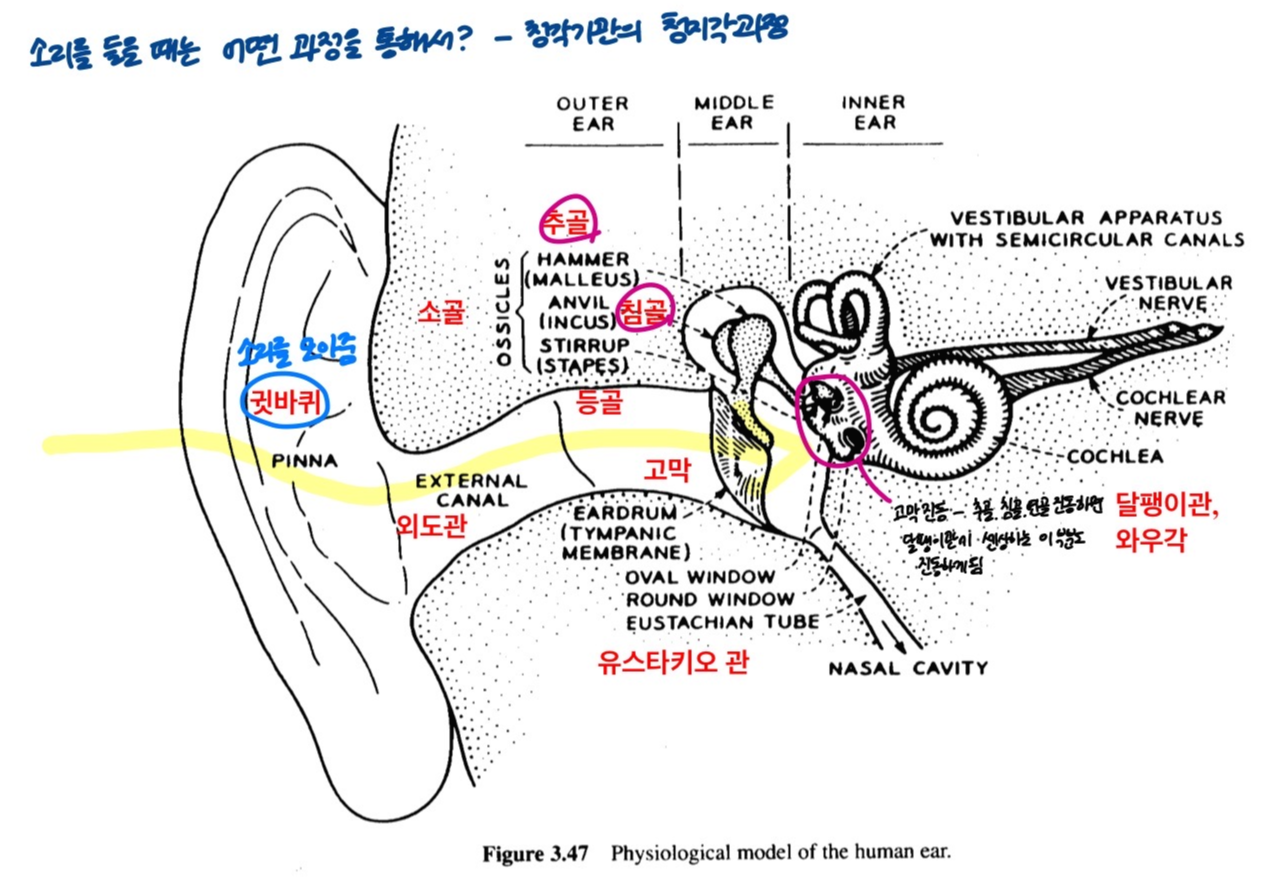
소리륻 들을 때는 어떻게 할까? -- 청각 기관의 청지각 과정.
- 귀의 구조 : 바깥 귀(outer ear), 가운데 귀(middle ear), 속귀(inner ear).
귓바퀴 모양 - 주름이 져있음. 쭈글쭈글 왜? - 바깥의 소리가 들어오면 귓바퀴를 통해서 소리가 모여서 외도관을 타고서 고막으로 전달이 됨. 귓바퀴의 주름은 인간의 진화과정에서 바깥의 소리를 잘 모을 수 있도록 모양이 만들어진 것임. 여러 방향에서 들어오는 소리들을 귓바퀴에서 잘 모을 수 있도록. 만약 죄다 반사시키고 고막으로 잘 전달이 되지 않느 모양으로 되어있으면 많은 소리를 놓칠 수 있는데, 인간의 생존을 위해서 인간에게 중요한 성분의 소리들을 음향 신호들을 뇌로 전달할 수 있도록 잘 전달할 수 있도록 긴 시간에 걸쳐 진화를 거쳐 최적의 구조를 갖춘게 현재의 귓바퀴의 모양. 귓바퀴가 하는 역할 : 소리를 모아준다. 관을 타고서 고막으로 소리를 전달해줌.
귓바퀴 ~ 고막전까지 : outer ear
(아이디어 : 보청기.. 귓바퀴 주름 모양 어떻게 다르게 해서 어떤 소리값들을 모을 수 있는지 분석.. 후에 보청기 기능 - 조음기관 파라미터 값 조정해서 잘 들리게 할 수 있는 연구)
(이 글은 서울대학교 정민화 교수님 '언어와정보처리' 과목에서 '음성언어의 구조' 수업 내용을 정리한 글입니다.)
'Spoken Language Processing' 카테고리의 다른 글
| 음성언어처리, 인간의 청지각과정, 베이즈정리, HMM 에 대하여 (0) | 2022.03.10 |
|---|---|
| 한국어 음성인식에 대해서 (0) | 2022.03.10 |
| 음성인식(Speech recognition) 이란? (0) | 2022.03.04 |
| Fairseq로 기계번역기 만들기 (0) | 2022.01.13 |
| 음성언어의 구조 - (2) 말소리의 생성 과정 (0) | 2021.12.19 |



댓글