역전파 알고리즘 (Backpropagation algorithm)
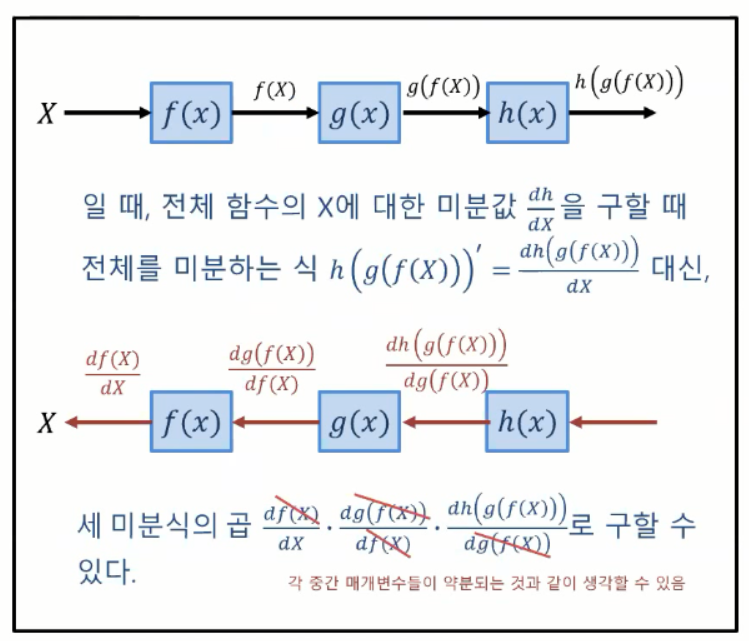
- 인공 신경망과 같은 수 많은 함수의 연쇄 꼴로 되어 있는 함수에서 각 변수의 편미분 값을 효율적으로 구할 수 있는 알고리즘
- 미분의 연쇄 법칙 (chain rule of derivatives) 을 활용
- 역전파 알고리즘을 통해 딥러닝 모델의 각 계층 파라미터에 대한 편미분값(기울기)을 효율적으로 구할 수 있음
- 역전파 알고리즘 : 미분 값들을 컴퓨터로 간단하게 계산할 수 있는 방법이다라고 생각하면 됨.
- 복잡한 합성함수를 미분하는 것은 어려움 : 두 개의 합성함수도 미분하는 것 복잡한데, 딥러닝은 수천 수만개의 합성함수 --> 따라서 이 것을 미분의 연쇄 법칙을 활용한 '역전파 알고리즘' 을 통해 쉽게 계산
훈련/검증/시험 데이터 분리 (train/validation/test split)
- 모델에게 주어진 데이터는 훈련 용도로도 사용되지만 모델이 본 적 없는 데이터에 대한 성능을 알아봐야만 모델이 일반화된 (generalized) 학습에 성공하였는지 알 수 있음
--> 모델이 훈련 데이터에 적응하여 훈련 데이터에만 성능이 높고 새로운 데이터에 대해서는 성능이 낮은 현상을 '오버피팅(overfitting)' 이라고 함
- 따라서 훈련용 데이터 외에도 시험용 데이터를 마련해야 함
- 또한 검증(validation) 데이터라 하여, 모델의 최적 학습 조건(하이퍼파라미터)을 찾기 위해 별도의 데이터셋을 구성하기도 함
- 검증 데이터와 시험 데이터는 절대 훈련에 사용되어서는 안 됨
--> 검증 데이터는 학습을 중단하는 시점을 결정할 때는 사용됨 (이게 훈련에 사용된다는 의미는 아님) - 예를 들어 validation loss 를 계산했을 때 이전보다 loss 가 증가해서 학습을 종료시킬 때.
즉, validation set 과 test set 의 공통점은 둘다 해당 데이터를 통해 모델을 업데이트, 즉 학습을 시키지는 않는다.
모두 이미 학습을 완료한 모델에 대해 평가하고 학습을 시키지는 않는다.
하지만, 둘의 차이는 validation set 은 모델을 업데이트하는데 "관여" 는 한다. 그리고 tests set 은 아예 학습에 전혀 관여도 하지 않고 마지막 최종 성능을 평가하는데만 사용한다.
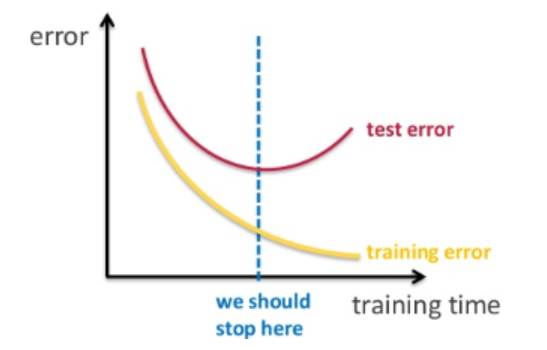
--> 그렇다면 어떻게 관여하는걸까?
- train set으로 학습을 할 때 너무 높은 epoch 으로 학습시키면 overfitting 의 문제가 있다. 따라서 딱 이 파란색 line 까지만 학습하는게 바람직하다. 이 파란색 line 에 해당하는 epoch 을 찾아야하는데, 이것을 찾기 위해서 test set 을 사용할 수는 없다. test set 은 최종 성능 평가할 때만 사용하기 때문에. 따라서 validation set 을 사용해서 저 파란 선을 찾는 것이다.
- validation set 을 사용하여 train set 에 대한 epoch 을 바꿔가면서 위의 error 곡선을 그리고, 파란 line 인 epoch 을 찾으면 그 해당 epoch 까지만 모델을 학습시키고 종료시킨다. 그리고 마지막 최종으로 test set 으로 최종 모델 성능 평가를 하는것이다.
- 따라서 위의 그림의 test error 는 validation set 으로 성능평가를 하는 validation error 라고 보면 된다.
딥러닝 모델 훈련 과정 정리
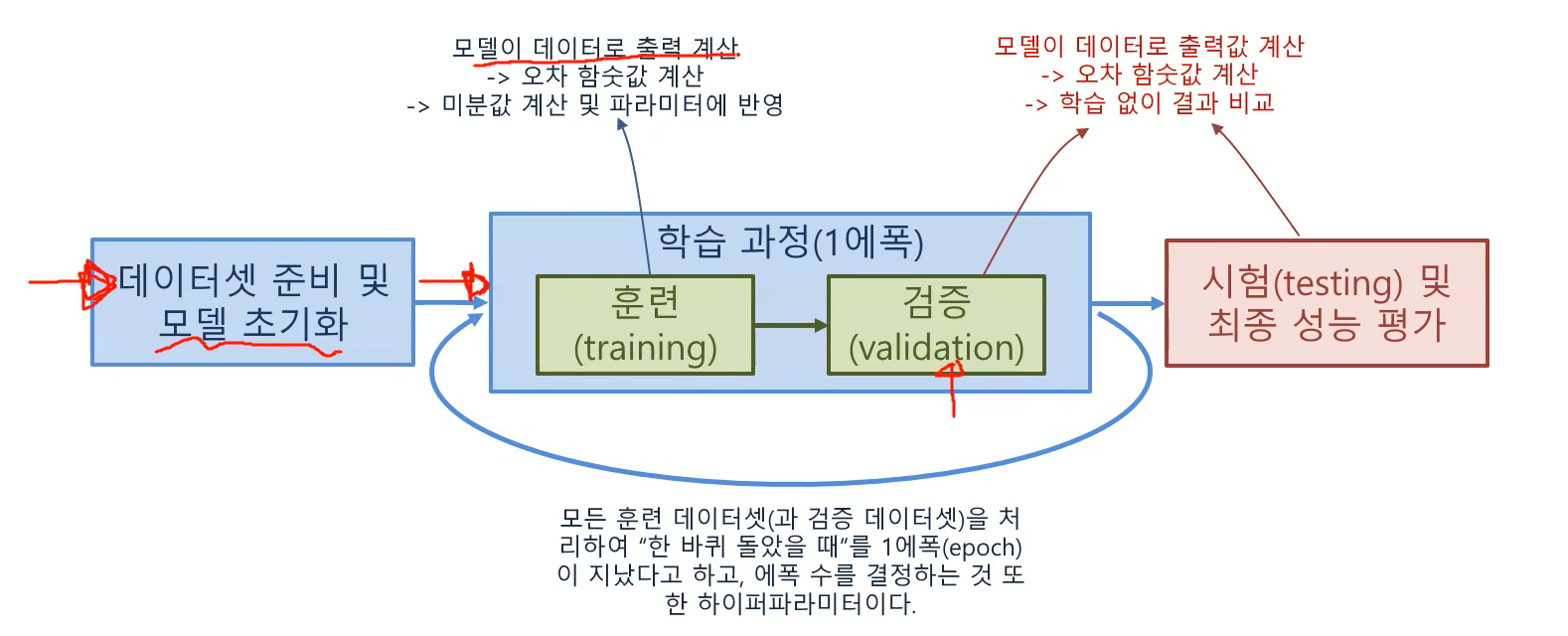
- 여기서 파라미터를 계속 업데이트하면서 훈련을 진행하는 것은 훈련 데이터셋이고, 검증데이터셋은 모델을 검증하기 위해 오차 함숫값을 계산하지만 그 결과로 인해 미분 값을 계산한다던지 파라미터에 반영한다던지 그런 과정은 없다. 검증 데이터셋을 통해 학습과정은 없고 결과만 비교한다. 그리고 여기까지가 1 epoch 이고 만족하면 테스트 셋으로 최종 성능 평가하는 단계로 가고, 아니면 다시 epoch 을 돈다.

즉, training set 을 통해 모델을 만들었다면, validation set 을 통해 그 모델의 성능을 평가하는데, training set 으로 한개가 아니라 여러개의 모델들을 만들기 때문에 어떤 모델이 가장 좋은지 validation set 을 통해 각각 성능평가를 진행한다. 그리고 validation set 으로 성능 평가한 결과 가장 성능이 좋았던 모델을 선택해 최종 모델로 선정하고, 그 모델로 마지막 최종 성능 평가를 위해서 test set 을 이용해 성능 평가를 한다. validation set 은 여러 모델에 반복적으로 사용되었던 데이터셋이기 때문에 한번 더 한번도 사용해보지 않았던 데이터셋인 test set 으로 평가를 진행하는 것이다.
validation set 은 최종 모델을 선정하기 위해 사용했다면, test set 은 최종 모델에 대해 딱 한번 성능을 측정하면서 앞으로 실전에서 이만큼 성능을 낼 것이다 하고 확인하기 위해 사용한다.
(이 글은 '언어와정보처리' 과목에서 '딥러닝 주요 알고리즘' 수업 내용을 정리한 글이다.)
'Deep Learning' 카테고리의 다른 글
| XOR 게이트 (배타적 논리합, 논리회로, 파이썬으로 구현해보기) (0) | 2022.05.29 |
|---|---|
| AND, OR, NAND 게이트 구현 (논리 회로 구현하기) (0) | 2022.05.29 |
| 딥러닝 주요 알고리즘 1 - 딥러닝 기초 이론 (1) 확률적 경사 하강법(Stochastic gradient descent, SGD) (0) | 2021.12.11 |
| Human Pose Estimation 기술 동향 (0) | 2021.05.07 |
| Abstraction & Reasoning in AI systems : (5) Program synthesis + Deep learning (1) | 2021.01.30 |


댓글