[AI 콜로퀴움] 이경무 교수님의 'Human Pose Estimation 기술의 발전과 미래' 강연을 보고 정리한 글이다.
(해당 강연은 www.youtube.com/watch?v=GBpnsFfLt2Q 에서 확인할 수 있다.)
< 딥러닝 이전의 휴먼포즈 추정기법 >
* 초창기 접근 방법 : pictorial structure model
- 사람의 신체를 신체부위(part)와 관계(spring)로 모델링. 영상에서 해당 부위를 매칭함으로써 포즈 추정. 최초의 휴먼포즈 추정 기법
- Mixture of parts : 더 작은 단위의 신체파트와 이들의 결합으로 표현. 유연성과 정확도 향상.
* 이미지 뿐 아니라 거리정보(depth) 기반 포즈 추정 기법 == Kinect (거리측정장비)
- Microsoft 가 개발한 단기간에 가장 많이 팔린 컴퓨터 하드웨어. Kinect 이용해 xbox 적용. 장비 없이 자기가 움직이면 그대로 게임에 적용가능.
* Kinect 을 가지고 human pose estimation 기법 == random decision forest
- 딥러닝이 나오기 전 random decision forest 가 머신러닝 쪽에서 가장 훌륭한 방법 중 하나였지만, 딥러닝 이후 지금은 random forest 별로 사용 x.
- Kinect 가 좋은 기술 만들었지만 사업적으로 성공하지는 못함 : privacy 문제(집안에 카메라 설치하는 거부감), 재미있는 응용소프트웨어 게임들이 많이 나오지 못해서 적용 불가. 결국 Kinect 단종.
< 딥러닝 기반 휴먼포즈 추정기법 >
* 2014년부터 딥러닝이 휴먼 포즈에 적용되기 시작함
- <DeepPose> by Toshev : 최초의 딥러닝 기반 2D 휴먼포즈 추정 기법의 논문.
- 몇 개의 간단한 CNN + Fully connected layer 달아서 이미지 들어오면 원하는 관절의 x, y 좌표 값이 나오게 함. 이 좌표 값을 가지고 원 영상으로 가서 estimated 된 좌표의 주위로 다시 crop 한 이후 조금 더 자세히 보고 더 정확한 x, y 좌표 값을 찾는 방식을 recursive 하게.
- 입력 RGB 영상에 대해 CNN-regressor 를 이용해서 점진적으로 신체 joint 의 2D 좌표를 추정. 하지만 결과는 기존의 classic 한 방법보다 크게 좋지 않음. (첫 딥러닝 휴먼포즈 논문임에도 불구 1487회 인용 밖에)
--> 이유 : 네트워크 구조 + output 자체를 x, y 포지션 값 직접 내려고 하는게 문제. 너무 정확한 값을 추정하라고 하니까 네트워크가 힘들어함.
- 그래서 2015년 뉴욕대 딥러닝의 3대 대가 ‘얀 레쿤 그룹’ : output 을 x,y 좌표 대신에 block 으로 하자. 확률을 나타내는 확률값으로 output 을 나타내자. == heatmap.
* Heatmap 의 이용
- 한 점이 아니고 좌표를 나타내는 확률값으로 하자. 여러 input 의 variation 을 잘 cover하고 robust 함. Heatmap 중에서 가장 높은 확률을 주는 position 을 output 으로 만들자. 실제적으로 이런 구조, heatmap 을 사용함으로써 (물론 네트워크도 다르지만) 엄청난 성능 향상.
- 좌표 대신 joint 가 나타날 확률 (heatmap) 을 추정함으로서 정확도 향상.
- 그래프 모델과 CNN 을 결합함으로써 joint 들간의 위치관계 사용
- 여전히 신체 구조적 정보 부족 : 여전히 신체가 갖는 독특한 정보. Human body 의 구조적 정보라던지 context 를 이용하지 못하는 단점이 있음.
< Context, Receptive field, local & global feature >
* Context 와 신체 구조 정보의 활용

- 작은 부위만 보면 잘 모르고, 전체(맥락)를 봐야 잘 알 수 있다. --> 맥락 정보를 사용하자!
- 2016년에 맥락을 활용한 논문이 나옴.
- CPM(convolutional pose machines) : body joint 들의 공간적 관계 정보 학습을 위하여 큰 receptive field 를 이용
- context 를 본다는 것은 큰 영역을 봐야한다는 것.
- deep CNN 이 쭉 가면서 중간의 layer의 한 노드는 원 영상의 영역을 보게 되어있는데, 깊이 갈수록 점점 큰 영역을 보게됨. 이게 receptive field.
- Receptive field 를 크게 해야 전체 global 한 context 정보를 얻을 수 있음. 따라서 굉장히 깊게 네트워크를 쌓음. 동시에 pooling 을 통해서 size 를 줄여가서 훨씬 더 큰 receptive field 를 얻을 수 있음.
이렇게 해서 원 영상의 정보와 context 정보를 활용해서 우리가 원하는 key point 를 찾을 수 있음.
- 순차적으로 receptive field 를 키우고 context 정보를 이용하여 joint 추정의 정확도를 높임
* 전역(global)과 지역(local) 특징 정보의 활용
- CPM 은 크게만 보자고 하는 것인데, 크게 보지만 정확한 position 을 찾으려면 local 한 지역적인 정보도 잘 봐야함. 따라서 크게도 보고 해당하는 위치에서의 정보도 둘다 잘봐야함. 이 전역특징, 지역특징을 모두 잘 활용할 수 있을까?
- 이게 2016년의 ECCV 에서 발표된 “a stacked hourglass network”
- 풀링과 업스케일링으로 이루어진 hourglass 네트워크를 연속으로 사용하여 다중 스케일에서의 전역과 지역적 특징을 모두 활용.
: 모래시계 형태의 하나의 모듈을 보면, 레이어의 사이즈가 점점 작아졌다가 다시 커지는 형태. 풀링을 하며 작아지고 다시 업 스케일링 하며 커지는 형태. Pooling 하면서 receptive field 를 크게 보는 효과가 있고, 업 스케일링 하면서 resolution 이 커지니까 local 한 정보를 다시 잘 보게 됨. 이렇게 해서 양쪽 정보를 같이 잘 활용할 수 있는 구조. 이런 네트워크를 여러 개를 연속사용함으로써 효과를 얻을 수 있음.
- CPM 보다 훨씬 좋은 결과를 가져옴.
- residual module + intermediate supervision
< Multi person 2D Pose >
- 지금까지는 한 사람 대상으로 pose 추정이었다면, 여러 사람 대상으로 pose 추정.
- 2017년에 CVPR 에 멀티 휴먼포즈 추정기법 OpenPose 가 처음으로 나오게 됨.
* 딥러닝 기반 2D 멀티 휴먼 포즈 추정 기법
- OpenPose : 최초의 딥러닝 기반 2D 멀티 휴먼 포즈추정 기법
- Bottom-up 방식 : 입력영상내의 모든 2D joint 들을 추정한 후, joint 들간의 관계성 (part affinity field) 정보를 이용하여 개별 사람의 포즈 검출
- 한 장의 영상에 여러 사람이 등장하고 일단 모든 가능한 body joint 를 다 찾음.
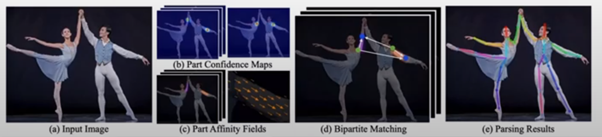
일단 찾은 후에 어떤 joint 가 어떤 사람것인지 알기 위해 이 논문이 제안한 방법은 “part affinity field” 정보 이용.
- 어떤 사람의 한 body point 가 있으면, 그 사람의 shoulder point 에서부터 그 사람의 팔 관절 point 가 어디에 있을까 하는 벡터를 같이 찾음.
그렇게 해서 다른 사람의 왼쪽 팔 관절이 있다고 하더라도 본인에 해당하는 팔의 관절을 잘 찾을 수 있음.
이렇게 두개의 정보를 따로 찾아냄으로써 개별 사람에 해당하는 body point 를 따로따로 그룹핑할 수 있음.
* 현재 SOTA 2D 다중 휴먼 포즈 추정 기법
- 현재 2D 멀티 휴먼 포즈 추정 기법 가장 최고의 성능을 나타내는 것은?
- COCO dataset 이라는 public benchmark. 그 안에 keypoint challenge 라는 리더보드(순위 점수판)가 있고, 거기에 학습데이터와 test data 가 있어서 본인이 개발한 알고리즘을 올리면 순위가 나오게 됨. 현재까지 1등인 방법이 Megvii. 네트워크를 살펴보면, hierarchical(계층적으로) 하게 scale space 에서 정보를 각각 뽑음(Global, local 정보를 활용하겠다는 것). refine network 를 각각 통과하고 다시 fusion 하고 또 한번 같은 네트워크를 recursive 하게 refine. Recursive 하게 refine 많이 해줌으로써 성능을 높임. 굉장히 큰 네트워크이고 성능면에서는 가장 우수한 네트워크.
* Refinement 기법 – PoseFix
- refine 관점에서 보면, 2019년 CVPR 에서 발표한 논문.
- PoseFix : 기존 시스템의 에러를 줄이는 후처리시스템
- 대부분의 휴먼포즈추정시스템은 공통적인 에러특성을 가지고 있으므로 실제 에러특성 확률 모델을 이용해 가상의 에러 데이터를 합성한 refine network 를 학습
: 어떤 네트워크는 당연히 에러를 가지고 있을텐데, 많은 pose estimation system 들에서 공통적인 에러 발견. 특정 왼쪽 shoulder point 는 특정한 error pattern 을 가지고 있고, 발목의 joint 들은 특별한 error distribution 을 공통적으로 가지고 있었음. 이런 것들을 통해서 각 joint 에 대해 statistical model 을 세울 수 있고, statistical model 을 통해 가상적인 에러 데이터를 만들 수 있음.
Ground truth 를 가지고 에러모델을 정의하면 에러 데이터가 나오고, 그럼 pair 가 생성되는 것임.
가상으로 만든 에러와 ground truth 를 가지고 correction 하는 네트워크를 디자인해서 학습시켜버리면 correction network, refinement network 이 됨.
어떤 네트워크라도 기존의 네트워크에 이 네트워크를 붙여주면 error 를 correction 해주게 됨.
기존의 모든 네트워크에 posefix 를 붙였더니 다 성능이 올라감(작게는 2.5 에서 7.3 까지 올라감, 굉장히 큰 것)

< 3D Human Pose >
- 실제는 3차원에서 사람들이 움직임. 3차원에서 해야지 의미가 있을 것임. 왼팔이 앞인지 오른팔이 앞인지는 z 축에서 구별할 수 있는 것이니까 실제로는 3차원으로 하는 것이 realistic 한 것.
- Depth 기반의 문제와 RGB 영상 기반의 문제로 나눌 수 있음.
* RGB 기반 2D 포즈로부터 3D 포즈 추정 기법
- 최초의 single 휴먼 3D 포즈 추정기법
- 3D 포즈 추정문제를 ‘2D 포즈 추정’ + ‘Lifting’ 문제로 분리 해결
: 이미지를 주었을 때 3차원 포즈 추정은 어떻게 할 것인가? 이 문제에 대해 처음으로 접근했던 것이 한 장의 RGB 영상이 들어오면 일단 2D pose 를 추정하고, 이 2D pose 를 가지고 lifting network 를 통해 3차원 pose 로 바꾸어 줌.
* RGB 기반 3D 다중 휴먼 포즈 추정 기법
- 단일 영상에서의 대상 사람의 실제 거리 측정의 모호성 존재
- 학습을 통하여 대상의 나이, 자세 등을 파악하여 영상 내 크기와 실제 거리와의 모호성을 해결
: 문제는 얼만큼 떨어져 있냐 알아야함. 사실 한 장 영상에서 보면, 사람을 detect 했을 때 detect 된 window 가 생기는데, window 크기로 봐서는 그 사람이 실제로 어디에 있는지 알 수가 없음. 두 사람 중 어느 사람이 카메라에 가까운지 먼지 알기 어려움. Window 사이즈만 가지고는 어떤 사람이 더 가깝게, 멀게 있는지 알기 어려움.
-->대상의 나이, 자세 등의 정보 이용으로 모호성 해결
< 3D shape and pose >
- 이제는 pose 뿐만이 아니라 shape 까지 원함.
- 단일 RGB 영상으로부터 인체의 3D shape 과 포즈 정보를 동시에 추정하는 최초의 기법
: 하나의 영상이 주어졌을 때 사람의 3차원적인 pose 뿐만이 아니라 body의 3D shape 까지도 같이 복원하자는 연구가 최근에 많이 있음. 하나의 마라토너 영상이 들어오면 관절이 좌표 뿐만이 아니라 그 사람의 naked body shape 까지도.
- parametric human 모델 (SMPL) 사용
: 특정한 parametric 한 human model 을 가지고 있어서 그 모델을 들어온 영상 내 사람의 pose 에 맞도록 parameter 를 추정함.




댓글