2021.11.19-20 에 진행된 한국음성학회 가을 학술대회 발표를 듣고 리뷰를 남깁니다.
2. 음성공학 발표 3편
2) 영어-한국어 대화체 자동통역을 위한 Cascade 및 End-to-End 접근 방식 비교 - 방정욱, 이민규, 윤승, 김상훈 (ETRI)
1. 연구 배경
자동 통역(speech translation; ST)
- 소스 언어 음성으로부터 타겟 언어 번역문을 생성
ex) 영어 음성 --> 한국어 번역문
- 두가지 대표 접근법
1) Cascade 통역 (cascade ST; CAS-ST)
- 보편적으로 많이 사용되는 방법
- ASR (음성인식기), MT(기계번역기) 의 두가지 모듈을 사용
- 영어 음성이 들어갔을 때, 음성인식기로 전사문을 만들고, 인식된 결과를 다시 기계 번역기로 집어 넣어줌

- 음성인식 (automatic speech recognition; ASR)
- 기계번역 (machine translation; MT)
2) End-to-end 통역(end-to-end ST; E2E-ST)
- 영어 음성이 주어졌을 때 direct 로 한국어 텍스트를 출력하게끔 하는 인코더-디코더 구조로 구성됨
- 기본적으로 Transformer 구조를 일반적으로 사용함

- 인코더-디코더 구조(encoder-decoder architecture)
CAS-ST vs E2E-ST
E2E-ST 가 주목받는 이유
- 복잡한 파이프라인 없이 매우 단순화된 구조
--> 모듈 2개씩 필요하지 않고 매우 단순화된 구조 사용
- 번역 시스템에 음성인식 오류가 전파되는 것을 방지
--> Cascade 에서는 음성인식 결과가 나오면 그 결과에는 분명 오류가 포함됨 - 그게 기계번역기로 그대로 들어간다는 단점.
--> E2E 에서는 딱 정형화된 문자가 아닌 임베딩 벡터가 들어가기 때문에 오류 전파 방지
- ASR 디코딩 시간 감소 및 ASR/MT 사이의 지연 우회
- 하지만, E2E-ST는 학습 데이터 수집에 어려움이 있음
--> Cascade 의 경우에는 1) 영어와 영어전사문 pair + 2) 영어 전사문과 한국어 번역문 pair 만 따로따로 모으면 됨
--> E2E의 경우 영어음성에 대한 전사문에 번역문까지 3가지가 동일하게 일치되는 데이터를 수집해야해서 데이터가 많이 부족한 상황
자동통역 코퍼스

- 코퍼스 구성 : (음성파일, 전사문, 번역문)
--> 음성파일, 전사문, 타겟 언어에 대한 번역문
- 대부분 영어나 유럽어 중심이며, 한국어는 소량의 낭독체 및 강연 코퍼스만 존재함
--> 최근 서울대 김남수교수님 연구실에서 Kosp2e (2021.7) 코퍼스 배포
--> ETRI 에서도 EnKoST-C (2021.7) 이라는 Ted 기반 영한 코퍼스 배포
- 영어-한국어 대화체 통역 코퍼스를 수집하여 CAS-ST 및 E2E-ST 성능 확인 필요
--> 한국어 코퍼스 뿐만 아니라 대화체 코퍼스가 필요
--> 1000 시간 이상 학습데이터가 필요한데, 배포된 데이터들은 대부분 500 시간 분량의 미미한 데이터들 ==> 대량의 데이터 수집 필요
2. 코퍼스 수집
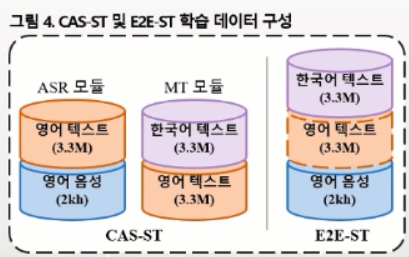
영어-한국어 대화체 통역 코퍼스 구축

- 영어 비디오, 영어 및 한국어 자막 파일로부터 통역 코퍼스 구축
--> 대화체 통역 코퍼스 구축을 위해, 드라마나 방송 데이터 등 다양한 미디어 데이터의 비디오와 영어,한국어 자막 파일을 수집
1) 데이터 전처리 : 자막을 문장 단위로 변환, 오디오 추출

- 처리방법으로는 자막에서 문장단위로 먼저 텍스트 전처리 한 후, bilingual text alignment 기법을 이용해서 어떤 한국어 문장이 어떤 영어 자막 문장과 같은지를 먼저 찾음 - 대역 문장이 형성됨 - 영어 대역 문장을 기준으로 영어 음성 파일들과 speech to text alignment 수행하게 됨 = 음성 파일과 그에 대한 전사문, 한국어 번역문이 형성됨.
- 2000시간 정도의 학습 데이터 수집하게 됨.
- 수집된 데이터는 다양한 드라마나 방송 데이터로부터 수집했기 때문에 다양한 화자가 포함되어있고, 다양한 도메인의 정보를 가지고 있음 + 배우들의 연기가 포함되어서 화자별로 다양한 감정표현과 노이즈 환경이 포함되어 있음.
- 자막으로부터 수집하다보니까, 영어 전사문은 대부분 잘 맞는데, 한국어 번역문은 Frankie 라는 영어가 프랭키 한국어로 그대로 번역되었다던가, 띄어쓰기나 오타 등등.. dummy 단어 포함(맨 마지막 줄 school 단어 없는데 대화 이해를 위해 '학교' 추가) 등등..
2) 이중언어 텍스트 정렬 : 영어-한국어 대역문장 생성
3) 음성-텍스트 정렬 : 각 대역 영어 문장의 시간 정보 추출
4) 데이터 필터링 : 비 정상적인 발화속도를 가지는 세그먼트 제거
3. 실험 결과
실험 환경
Transformer model (MuST-C recipe in ESPnet)
- ESPnet 이라는 음성인식에서 자주 사용하는 음성 기반 공개 도구 사용. 그 안에 자동 통역 레시피가 있는데, 레시피 대로 실험 수행
- 모든 실험은 트랜스포머 구조로 사용 + 입력 feature 로 80차원의 filterbank, 3차의 pitch 정보 ESPnet을 사용한 Transformer Large 구조를 사용
ST experiments
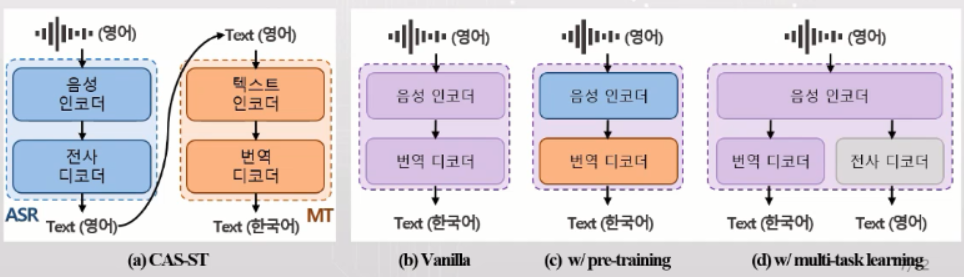
- CAS-ST : (a) ASR + NMT
- E2E-ST : (b) vanilla, (c) w/ pre-training, (d) w/ multi-task learning
--> 자동 통역 실험은 Cascade, E2E 모두 수행
--> Cascade 실험을 위해 음성인식기 별도로 학습, 기계번역기 NMT 별도로 학습
--> E2E 실험은 기본적으로 vanilla 시스템 (트랜스포머 인코더 디코더에 랜덤한 초기값을 준 후 입력과 출력을 주고 알아서 학습해라)
--> 성능 개선을 위해 pre-training, multi-task learning 추가로 실험해봄
--> vanilla 는 인코더 디코더에 랜덤한 초기값을 주었다면, pre-training 의 경우 음성인식기의 인코더 정보가 음성을 잘 표현하는 정보를 입력으로 가지고 있음
--> 음성인코더를 통역기에 가져와서 초기값으로 사용하고, NMT 의 디코더 정보도 임베딩된 텍스트 정보를 한국어로 잘 번역하는 능력이 있기 때문에 번역 디코더를 통역기에 가져옴
--> multi-task learning 방법 보편적으로 사용되는데, vanilla system 처럼 영어 음성을 한국어로 번역만 하는걸 목표로 학습하는 것이 아니라, 학습할 때 영어 음성을 영어 전사문으로 음성인식까지 같이 수행하도록. 음성인식과 번역을 같이 수행하도록 multi-task learning.
이런 경우 음성 인코더에서 학습된 임베딩 벡터가 조금 더 전사문의 형태를 가질 수 있도록 할 수 있다는 장점이 있어서 다른 연구에서도 많이 사용됨.
Evaluation metrics
- ASR task : word error rate(WER(%))
--> 정답 문장과 인식된 결과 문장에 단어가 얼만큼 일치하는가. 낮을수록 좋은 값 가짐
- MT & ST tasks : morpheme-level 3-gram BLEU
--> 기계번역과 통역의 경우, 한국어 형태소 단위의 trigram 사용. 각 gram 별로 확률값에 대한 기하 평균. 높을수록 좋은 값 가짐
자동통역 실험결과
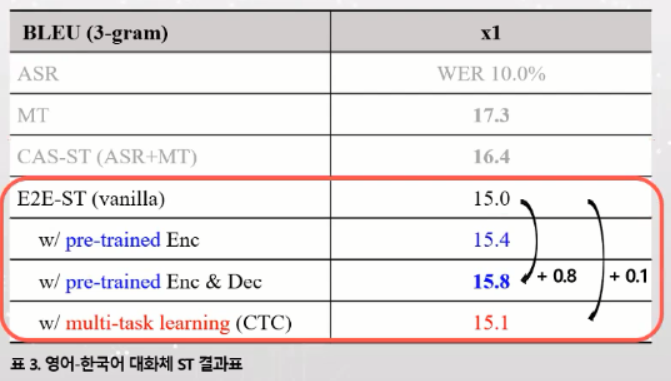
- 2000시간 분량에서 음성인식 수행 결과 대화체에서 10%의 단어 오류율
- MT vs CAS-ST : BLEU -0.9 ; 오류차이
--> 기계번역성능은 17.3%. cascade 의 경우는 10% 음성인식 오류가 포함된 입력이 들어가기 때문에 조금 더 낮은 16.4%.
--> 17.3%와 16.4% 는 0.9 정도의 성능 차이 = 나름 큰 차이
- CAS-ST vs E2E-ST : BLEU -1.4; 모델 크기 및 학습 난이도 차이
--> CAS-ST(ASR+MT) 16.4, E2E-ST(vanilla) 15.0 -- Cascade 의 경우는 영어 전사문 정보 하나 더 사용됨, E2E 는 그런 것 없이 알아서 학습해라 (영어 음성에서 한국어로 바로 학습.. task 가 어려워서 그런지 조금 더 낮은 성능)
- E2E-ST 고도화 : Pre-training >> multi-task >= vanilla
--> 성능 개선 방법은 pre-training 과 multi-task.
--> 음성인식기의 인코더를 통역기에 가져왔을 때 blue score 가 0.4 정도 개선됨 (15.0 --> 15.4)
--> NMT 디코더까지 같이 가져왔을 때 0.8 개선 효과 (15.0 --> 15.8)
--> multi-task learning 에서는 음성인식 디코더로 CTC 사용했는데, 개선 효과 미미.
--> 결과적으로 2000시간 실험 결과로 CAS-ST(ASR+MT) 가 16.4, E2E-ST with pre-trained Enc&Dec 가 15.8 로, 여전히 cascade 가 dominant.
데이터 증강 실험결과
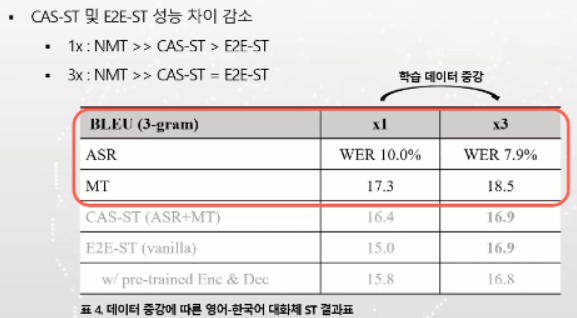
--> 자유도는 E2E 가 더 높은데 왜 cascade 가 더 성능이 더 좋은가? --> 데이터 7000 시간으로 더 수집해봄
--> 결과로는 음성인식은 7.9 WER 로 더 개선, NMT 도 18.5 로 성능 개선. CAS-ST와 E2E-ST 성능 개선 모두 있었지만, Cascade 성능 개선 폭보다 E2E 가 월등히 높음 == 결과적으로 7000 시간 훈련에서는 CAS-ST 와 E2E-ST 가 비슷한 성능 확인됨
--> But E2E-ST with pre-trained Enc & Dec 는 7000 시간이여도 큰 변화 없음. 데이터가 아마 충분해서 그런지 pre-training 에 대한 효과는 없거나 미미했음.
--> 따라서, 소량의 데이터에서는 pretraining 과 multi-task 모두 E2E 성능에 도움이 되지만, 대량의 데이터에서는 효과가 미미함.
--> 결국은 학습 데이터 수집이 성능 개선에 가장 큰 영향을 미친다.
4. 결론
영어-한국어 대화체 자동통역을 위한 접근 방식 비교
- 영어-한국어 대화체 학습 데이터 구축
- Cascade ST 및 End-to-end ST 접근법 성능 비교
- End-to-end ST 성능개선 방법 검토
- 데이터 증강에 따른 성능 개선 가능성 확인
3) 딥러닝 기반 단일 클래스 분류를 사용한 한국어 키워드 검출 (서강대학교 지능정보처리 연구실 이승현님, 박형민님)
Korean Key-Word Spotting Using Deep One-Class Classification
Task
Key-Word Spotting (Wake-up word spotting)
- 사용자가 미리 정의된 특정 단어나 어구를 발화했을 때 이를 검출하여 장치를 구동 시키는 기능
- 인공지능 스피커 / 핸드폰 등의 모바일 기기에 탑재된 기능
- 필요성
--> 보다 긴 배터리 사용 기간이 관건인 모바일 장치의 특성상 상당한 양의 메모리, 연산 자원을 소모하는 음성인식 등의 기능을 항상 켜 놓을 수는 없기 때문에, 키워드 발화 지점을 해당 기능을 on/off 하는 기준점으로 삼음.
--> 음성인식 자체적으로 소모하는 자원이 너무 많을 경우에 사용자 음성을 서버로 보내서 서버에서 처리하게 되는데, 해당 기능을 모든 시간 켜놓는 것은 사용자의 사생활 문제에도 관련 있어서 key word spotting 사용할 필요성이 있음
--> 사용자의 User Experience 를 향상시키는 순기능도 있음 - Siri 와 헤이카카오와 같은 보다 친숙한 호칭을 사용함으로써 사용자의 User Experience 를 향상시키는 부가적인 장점도 있음.
Motif
Limit of Multi-class Classification Method
- 기존 방식 : 주로 Key-word 를 포함하는 class 들 간의 classification method 로 접근
- Limitation of the existing method
1) Class Imbalance : Key-word vs Other words 로 할 때, key-word 가 아닌 단 어들의 수가 압도적으로 많아서 class imbalance 가 발생
2) Performance Degradation : key-word 자체를 찾는 True Positive Rate (Recall) 은 준수한 반면, precision 은 낮음. 다시 말하여, 학습에 사용되지 않은 key-word 가 아닌 word 를 rejection 하는 성능이 낮음
--> 오로지 Key-word 단어들 만을 가지고 학습하는 one-class classification method 를 KWS 에 적용
Dataset
Google Speech Command Dataset
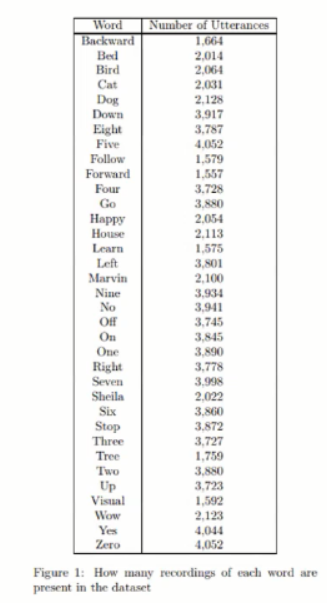
- Contents : 64,727 one-second-long utterance files, 30 target classes
--> 64727 개의 정해진 길이의 1초 단위의 발화데이터들로 구성되어 있음. 30개의 타겟 words.
--> 모델의 성능을 측정할 때는 주로 12 개의 class classifcation 을 측정하게 됨. 30개의 단어들에서 10개의 단어들 추출 + 나머지 20개를 unknown class 로 사용.
- Benchmark : 12 Class classification accuracy - 10 main class (yes, no, up, down, left, right, on, off, stop, go, silence) + unknown(the other classes) + Silence (noise)
Baseline Model
Mean-shifted Contrastive Loss for Anomaly Detection
- 단일 class classification - target 이 되는 class 만 가지고 학습한 후 target 이 아닌 데이터들을 넣었을 때도 rejection 을 할 수 있는 모델을 학습시키는 것이 목적.
- 이미지 data 에 대한 one-class classifcation model
- 해당 모델이 음성 data 에 대한 one-class classification model 로 적합한지 알아보고자 함.
- Anomaly detection on One-class CIFAR-10 Task 에서 SOTA Model 을 이번 실험에 사용함
--> CIFAR-10 이 원래 10가지의 이미지 클래스를 분류하는 task. 10가지 중 한가지의 이미지를 normal 로 설정해서 해당 이미지들로만 학습한 후에 나머지 9가지 이미지를 inference 에 넣어서 성능을 측정하는 task.
- anomaly detection 은 주어진 data 를 새로운 dimension 의 vector 로 representation 함. 이 논문에서는 representation 으로 pre-trained resnet model 을 사용함.
- Loss 로 변형된 Contrastive Loss 사용
--> contrastive loss 는 positive pair와 negative pair 가 있을 때, positive pair 끼리는 거리를 가깝게 하고, negative pair 끼리는 거리를 멀게 하는 loss 를 의미. 지금 one class classification 에서는 데이터가 다 동일한 class 의 데이터만 있기 때문에 contrastive loss 활용하기 위해 = 같은 data로부터 다르게 augmented된 data 는 같은 representation 으로 표현되도록 거리를 가깝게 하고, 다른 data 로부터 augmented 된 data 는 거리를 멀게 하는 방식으로..
- 기존의 One class classification 에 사용된 contrastive loss 의 경우, 같은 data 로부터 다르게 augmented 된 data 는 같은 representation 으로 표현되도록 제한.
Loss
- Mean-shifted Loss 와 Angular Loss 두 loss를 합쳐서 사용
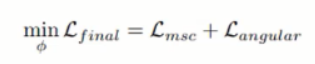
- Mean-shifted Loss
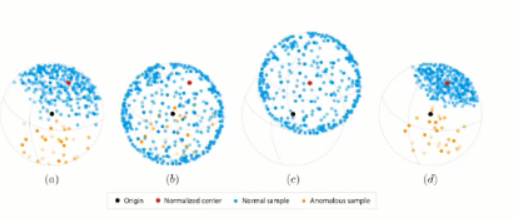
(a) pretrained resnet model 을 처음에 통과했을 때 파랑색-normal, 노랑색-abnormal dataset. origin unit vector 를 기준으로 sphere 에 표현한 것. 아무래도 pretrained 이 되어있다보니까 학습을 하지 않았음에도 불구하고 어느정도 cluster 되어 있는 것을 확인할 수 있음.
(b) 처음 파란색 점들 normal feature 들의 중심인 normalized center 를 구함 - 빨간 점. normalized center 를 구한 후, 파란색 점들을 이 center 기준으로 shift 시킴.
(c) shift 시킨 상태에서 앞의 contrastive loss 를 활용해서 학습 진행.
(d) 그 이후 다시 unit sphere 로 projection. 그러면 (a) 에서 보다 normal 과 abnormal 사이의 관계가 더 뚜렷해짐.
- Angular Loss
- 같은 class 의 data 들인데, angular distance 가 멀어지게 하게 되면, 다시 projection 시켰을 때 center 와의 거리가 멀어지는 문제점이 발생할 수 있음. 결국 목적은 normal dataset 을 cluster 시키는 것이기 때문에 center 를 기준으로 angular distance 를 조금 제한시킴.
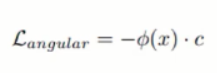
Anomaly Criterion
- 학습된 모델을 통해서 normal 과 abnormal 을 구분하는 anomaly criterion
- 우선, 분류해야 할 target image 와 모든 training image 사이의 cosine distance 를 구함.
- K 개의 nearest feature 만 갖고 아래 식을 통해 s(x) 값이 threshold 보다 큰지 아닌지를 통해 normal / anomalous 를 판단함.
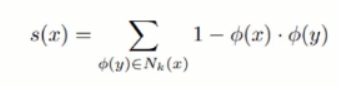
- x 라는 새로운 input 이 들어왔을 때, 이 input 이 normal 인지 abnormal 인지 판단하기 위해서는 output 과 training image 사이의 cosine distance 를 구하게 됨. 모든 trianing image 의 feature 를 사용하는 것이 아니라 가장 가까운 k 개의 nearest feature 만 가지고 판단. 거리가 가까우면 normal, 멀면 abnormal 로 분류하게 됨. distance 가 가깝다는 것은 cosine similarity 가 높다는 것이기 때문에, score 이 작게 나오고, 거리가 멀면 score 이 크게 나옴.
Proposed Model
Modification & Adaptation
- 해당 baseline model 을 어떻게 변형해서 key-word spotting 모델로 사용했는지..
- Pre-trained Resnet model은 그대로 유지
- 입력 data : image -> MFCC/ log mel spectrogram of waveform
--> 기존 모델에서는 이미지를 입력으로 넣는 반면에, resnet 을 input 으로 활용하기 위해서 MFCC / log mel spectrogram 을 input 으로 넣음.
- Augmentation : crop, flip, color jitter, grayscale, gaussian blur -> Spec augmentation performe d on 2D MFCC feature
--> 해당 논문에서는 이미지에 잘 쓰이는 augmentation (crop, flip...) 사용
--> MFCC / log mel spectrogram 은 채널이 1차원이기 때문에 위의 augmentation 을 바로 적용하기는 힘듦.
--> 음성 딥러닝에 많이 사용되는 spec augmentation 기법 사용 - random 하게 주파수 축 또는 time 축으로 zero-masking 함.
Training & Test
Google Speech Commands Dataset - MFCC
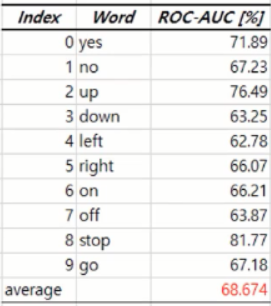
- 단어 별로 normal 로 설정하였을 때 다른 ROC-AUC score 를 보이는 것을 확인할 수 있음.
- Train - Test set 의 구성 : Train dataset 은 normal 로 설정한 class 안에 포함된 utterance의 50%를 사용, 나머지 50%는 test set 에서 사용됨. Test set 은 해당 50% 의 normal data 와 동일한 수의 abnormal utterances 사용. 나머지 9 class 로부터 각 class 마다 같은 개수를 randomly select.
- 평균적으로 AUC score 은 68%
한국어 데이터셋에 대한 성능 검증1
- Target word Dataset
--> 자체 제작된 DB
--> 76명의 화자, 2308개의 "Hi IIPHIS" 발화 Dataset, 길이 1.6sec
- Non-target word Dataset
--> 자체 제작
--> Target word 와 길이가 비슷하고, 발음이 비슷한 한국어 문장들로 구성
- 성능
--> MFCC : 80.34% (AUC)
--> Mel : 84.76% (AUC)
--> 아무래도 baseline model 이 이미지에 특화된 모델이 Mel 이 MFCC 보다 이미지에 특화된 성질을 더 많이 가지고 있어서 라고 추측해봄.
한국어 데이터셋에 대한 성능 검증2
- Target word Dataset
--> 자체 제작된 DB
--> 76명의 화자, 2308개의 "Hi IIPHIS" 발화 Dataset, 1.25 sec random crop
- Non-target word Dataset
--> AIHUB 멀티모달 영상 Dataset 으로부터 음성 wav 만 추출하여 random 하게 1.25sec 를 crop 하여 사용
- 성능
--> MFCC : 93.91% (AUC)
--> Mel : 97.28% (AUC)
--> 아무래도 문장에서 crop 하게 되니, 비어있는 공간이 없는 데이터 + Hi IIPHIS 발화 데이터 비어있는 구간이 있으니 그 차이를 학습해서 조금 더 높게 나오지 않았나 추측.
Conclusion
Contribution
- Key-Word Data 만 갖고 KWS model 을 구현할 수 있음을 확인
- KWS 를 Anomaly Detection Task 적 관점에서 다룰 수 있음을 확인
- Un-seen word 가 포함된 Utterance 를 reject 할 수 있음을 확인
Future Work
- Image Classification 위주의 model 이 아닌 time series data 의 one class classification model 확인
- deep representation model 로써 조금 더 가벼운 model 사용
- pre-trained net 을 사용하지 않거나, 사용하더라도 audio dataset 에 대해 최적화된 neural-net model (PANN network, PASE feature encoder etc.) 적용
- Face recognition, Speaker verification task 의 접근 방식 활용
'Others' 카테고리의 다른 글
| AI 연구자가 가져야 할 태도 및 사고방식 (0) | 2025.05.29 |
|---|---|
| 인지과학 차원의 뇌과학 (0) | 2022.03.23 |
| 2021 한국음성학회 가을 학술대회 리뷰 (2) (0) | 2021.12.04 |
| Intel Korea AI Technical Workshop 2021 리뷰 (0) | 2021.11.24 |
| 2021 한국음성학회 가을 학술대회 리뷰 (1) (0) | 2021.11.19 |



댓글