2021.11.19-20 에 진행된 한국음성학회 가을 학술대회 발표를 듣고 리뷰를 남깁니다.
1. 특강 - "언어병리학 음성장애 영역에서의 AI 연구 최신 경향 및 임상 특성" - 김근효님(부산대병원)
* 언어병리학 음성장애 영역에서 일반적인 연구 절차
1) 데이터 수집 : 연장 모음 /아/ or 연속 발화 음성샘플
2) 데이터 레이블링 : 음성샘플 길이 및 질환명 확인
3) 데이터 분석 : 섭동/켑스트럼 분석, 청지각적 평가, 음성설문지
4) 통계분석 : ANOVA, Regression analysis, ROC curve
5) 결과해석 : 연구의 의의
* 머신러닝과 딥러닝의 비교
- 인공지능 : 알고리즘을 이용해서 데이터를 분석, 학습하고, 학습한 내용을 기반으로 판단이나 예측
--> 머신러닝 : 데이터의 특징을 사람이 먼저 입력(지정) 해주어야 함
--> 딥러닝 : 데이터의 특징을 선정하는 것가지 인공신경망을 통해 학습
* An Open-Source Computer Vision Tool for Automated Vocal Fold Tracking From Videoendoscopy
- 연구목적 : 성대의 움직임(성문 최대각)의 자동 추적을 위한 새로운 커뮤터 비전 도구를 소개
- 연구방법 : 정상 성인 20명, 편측성 성대마비 20명, 최대 성문 개방각을 추적, 후두내시경에서 성대 위치 파악을 위해 딥러닝(DNN) 알고리즘 훈련, 알고리즘 정확도는 전문가의 수기(manual) 측정과 비교
- 연구결과 : 정상과 성대마비 간의 각도 ROC 분석 : cutoff value 58.65, 민감도/특이도 0.85, AUC 0.888
* A Convolutional Neural Network for Real Time Classification, Identification, and Labelling of Vocal Cord and Tracheal Using Laryngoscopy and Bronchoscopy Video
- 연구목적 : CNN을 이용하여 성대와 기도의 입구를 탐지
- 연구방법 : 775개의 후두내시경, 기관지내시경 영상, 3개의 CNNs 성능 비교(ResNet, Inception, MobileNet)
- 연구결과 : The availability of AI may improve airway management and bronchoscopy by helping to identify key anatomy real time. (Vocal cords - ResNet 0.84, Inception 0.78, MobileNet 0.64)
* Comparison of Convolutional Neural Network Models for Determination of Vocal Fold Normality in Laryngoscopic Images
- 연구목적 : CNN 기반의 딥러닝을 통해서 정상과 병리적 상태의 성대 영상을 변별
- 연구방법 : 2216명(성대용종 500명, 성대결절 147명, 성대 육아종 167명, 후두백반증 236명, 후두암 267명, 정상 성대 899명). Simple 6 layered CNN(CNN6) 과 VGG16, Inception V3, Xception 성능 비교 - 모델별 민감도, 특이도, 예측 정확도 비교
- 분석모델
--> Simple 6 layered CNN(CNN6) : 2 convoluional layers, 2 max pooling layers, first fully connected layer with Relu activation and fully connected output layer with Softmax activation
--> VGG16 : ImageNet Challenge 에서 Top-5 테스트 정확도를 92.7% 달성하면서 2014년 컴퓨터 비전을 위한 딥러닝 관련 대표적 연구 중 하나로 자리매김. VGG - Visual Geometry Group / 16 - 16 layers. 13 convolution Layers + 3 fully-connected Layers, 3*3 convoution filters, stride 1, padding 1, 2*2 max pooling(stride 2), Relu
--> Inception V3 : 2014년 IRSVRC 대회에서 1등을 차지한 v1 모델 GoogleNet을 응용한 버전. 이미지를 비교하여 찾아내는 모델
--> Xception : Inception을 기초로 한 모델(extreme version of Inception module)
- Overall flow of applying deep learning technique on a real-time video stream
--> Video stream - Object dtection & ROI cropping - Classification with the trained CNN model - Real-time classification of larynx on each frame from video - Calculating cumulative probability of the whole video stream with size-weighting - Implementation of Grad-CAM to highlight important regions
- 연구결과
--> VGG16 - validation 99.6%, epochs to the highest validation accuracy 79
--> Inception V3 - validation 98.9% epochs to the highest validation accuracy 98
* Diagnostic Accuracies of Laryngeal Diseases Using a Convolutional Neural Network-Based Image Classification System
- 연구목적 : 딥러닝 기반의 분류모델을 사용하여 성대질환에 대한 커퓨터 보조 진단(CAD)을 수행하기 위해서
- 연구방법 : 후향적 데이터를 사용한 실험 연구, 4106장의 성대 사진 분석 - 낭종, 결절, 용종, 백반증, 유두종, 육아종, 마비 및 정상
- 연구결과 : EfficientNet-B0 showed the highest validation accuracy in discriminating laryngeal diseases and the most affordable memory size. Training 결과 99% 이상의 정확도, Validation 결과 90.6~98.4%(평균 94.5% +_ 2.8%)
* A Survey on Machine Learning Approaches for Automatic Detection of Voice Disorders
- 연구목적
--> 음성장애를 자동탐지하기 위한 다양한 머신러닝 기법 조사(98개 논문)
--> 다양한 데이터베이스, 특징 추출 기술, 머신러닝 접근 방식 분석
--> 음성장애 자동 탐지 시스템 (automatic voice disorder detection, AVDD) 은 환자와 임상가에게 도움(음성장애의 조기발견 및 치료 결정) - 후두내시경 검사는 침습적 검사, 환자의 협조 필요, 기기 유지관리가 어렵고 큰 비용 소요. 음향학적 음성검사는 비침습적 검사, 간단한 검사 절차, 데이터 관리 수월
- AVDD(Automatic voice disorder detection) system : (Recorded Audio files) --> Audio Data Labelling --> (Labelled Audio) --> Divide Audio data into Frames --> Extract Features <특징 추출> --> (Feature set) --> Generate Train and Test set --> Train set으로 develop ML model, Test set으로 evaluate ML model <머신러닝 알고리즘 - 훈련, 검증, 평가> --> AVDD System
- 프레임별로 특징 추출하고 머신러닝 알고리즘 적용
-- 특징 추출 기법
1) Acoustic analysis
- Perturbations in the fundamental pitch period and peak amplitude : perturbation 속도, 주파수 강도에 대해서
- Vocal noise included in the signal : 노이즈에 대해 판단
- Cycle-to-cycle wave form variations : cycle-to-cycle에 대해서
- Average frequency characteristics : longterm 에 대해서
- Transition characteristics of the signal : 스펙트럼에 대해서도 특징 추출 가능
2) Mel-frequency cepstral coefficient (MFCC)
- 음성 샘플을 일정 구간(short time)으로 나누어, 이 구간에 대한 스펙트럼을 분석하여 특징을 추출하는 기법
- SLP 보다는 ASR에 더 익숙. 음성신호에서 frame 별로 처리. mel filterbank, mel spectrum 통해서 변수 측정.
- LPC 분석 : 음성 생성 모델의 파라미터 예측 방법
- frame signal - for each frame : window frame - FFT - Mel Filterbank - Log - DCT - Lifter
-- 머신러닝 알고리즘
1) Hidden Markov model (HMM)
- 시스템이 은닉된 상태와 관찰가능한 결과의 두 가지 요소로 이루어졌다고 보는 모델
2) Gaussian mixture model (GMM)
- Gaussian 분포가 여러 개 혼합된 clustering 알고리즘
3) Support vector machine (SVM)
- 패턴 인식, 자료 분석을 위한 지도 학습 모델이며, 주로 분류와 회귀 분석을 위해 사용
4) Artificial neural netorks (ANN)
- 생물학의 신경망(동물의 중추신경계 중 특히 뇌)에서 영감을 얻은 통계학적 학습 알고리즘
그외 ) Decision trees, Linear classifier, K-means clustering, Combined classifiers
* Detection of Pathological Voice Using Cepstrum Vectors : A Deep Learning Approach
- 연구목적 : 켑스트럼 벡터 기반의 딥러닝을 이용한 병리적 음성의 탐지
- 연구대상 : 정상음성 60명, 병리적 음성 402명 (8개 음성장애 진단군 포함)
- 연구방법 : 모음 3초 샘플에서 MFCCs (MFCC, MFCC+delta, MFCC(N)+delta) 추출. DNN, SVM, GMM의 수행력을 five-fold cross-validation(교차검증), MEEI(Massachusetts Eye and Ear Infirmary)의 데이터베이스 활용
- 연구결과
--> waveform of a pathological voice sample - iiregular and wider variations of amplitude compared with the normal voice sample
--> Wide band spectrogram in the corresponding pathological voice sample - blurred harmonic structures and contained noise-like components in the high-frequency region
* An Automatic Health Monitoring System for Patients Suffering From Voice Complications in Smart Cities
- 연구목적 : 자동 음성장애 감지 시스템 구현
- 연구방법 : 정상과 음성장애 대상의 강도 차이를 분석하기 위해 LPC 기반 스펙트럼 계산, 계산된 스펙트럼을 사용하여 정상과 음성장애 변별. 정상 53명, 음성장애 173명, GMM 모델 이용
(Disordered Samples + Normal Samples --> Linear Prediction Coefficients --> Spectrum --> GMM Models(Normal, Disordered) --> Similarity --> Decision(normal or Disordered)
2. 음성공학 발표 3편
1) Attention 인공신경망을 통한 한국어 방언의 억양 패턴 학습 및 방언 식별
- Attention 인공신경망을 통한 한국어 방언의 억양 패턴 학습 및 방언 식별
- 트랜스포머 기반 실시간 한국어 음성인식 : 트랜스포머 기반 종단형 음성인식
--> 트랜스포머 + CTC (connectionist temporal classification) 음성인식 (based on espnet toolkit)
- Attention 모델에서의 억양 패턴 학습을 통해 방언별 Attention 가중치 분포를 살펴봄
- 프레임별 음향 특징을 시게열 LSTM 모델에서 학습함으로써 억양 패턴 실현
- 50대 이상 경상권 화자를 대상으로 진행하여, 경남 및 경북권 방언 각각에서의 Attention 가중치 분포 확인
- 계획) 음향 특징의 조합을 바꾸어 식별 성능 향상, 다른 방언권에도 적용하여 방언별 학습 패턴 확인, Attention 모델의 학습 패턴과 언어학에서 바라보는 방언 특징 비교
2) 트랜스포머 기반 실시간 한국어 음성인식
트랜스포머 기반 종단형 음성인식
* encoder self-attention
- Uni-directional encoder : current data + previous data
- Block processing : current block data
- Contextual block processing
--> current block data + context vector
--> Transformer ASR with Contextual Block Processing
--> Better than others
--> 기본적으로 block processing 을 사용하지만, 각 block 에 context vector 라는 추가적인 정보를 활용, 이를 통해 성능 개선
* encoder-decoder attention
- decoder의 구조변경이 필요한 방식 : MoCAa(2019), CIF(Continuous integrate-and-fire)(2020), Triggered attention(2020)
- Blockwise Synchronous Beam Search(2021)
--> 이 알고리즘은 디코더 구조의 변경 필요 없이 beam search 방식으로.
--> 기본적인 가정 : decoding for ASR does not depend on far-future context (먼 미래의 정보 활용하지 않는다)
cf) conventional beam search
- 기존 일반적인 beam search 알고리즘 보면, 어떤 i 번째 토큰 예측 위해서 전체 입력 데이터를 기반으로 계산함.
- output token 생성할 때 항상 h 1:n 이용
but 전체 처리 어려움 --> 그래서 blockwise synchronous beam search 에서는 어떤 위치의 토큰을 생성할 때 그 위치의 토큰 생성을 위해 필요한 block 까지만 활용한다는 가정으로 제안된 알고리즘.
- Blockwise Synchronous Beam Search 는 output token 생성할 때 필요한 h 1:b<B 만 이용
--> 첫번째 토큰이나 두번째 토큰 예측은 첫번째 block 까지 보고 확률 계산
--> 세번째, 네번째, 다섯번째 토큰 -- 첫번째, 두번째, 세번째 block 까지의 데이터를 보고 출력토큰 예측
- 이 때의 문제는 이 block 에서 어느 토큰까지를 예측할 수 있는가? -- 이 논문에서는 현재 계산하고 있는 토큰이 생성되었을 때 그 토큰의 확률이 안정적인지를 보고 그 토큰의 확률이 신뢰적이지 않으면 다음 block 을 더 읽어들이고 계산.
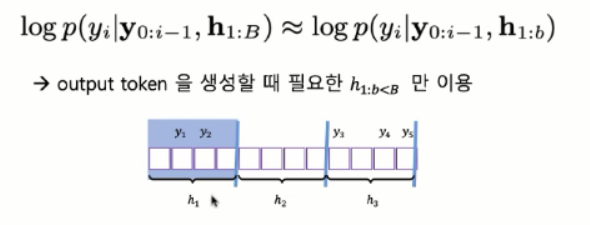
- 세번째 토큰을 계산할 때 첫번째 블락만 보고 계산하면 확률이 신뢰적이지 않아서 그 경우 다음 블럭을 더 보고 두번째 블럭까지 보고 계산. 그 때도 확률이 낮으면 그 다음 block 또 보고 하는 방식.. 세번째 블락에서는 세번째 토큰 출력하기 적당해서 사용하게 됨..
- block boundary detection
--> finds unreliable hypotheses
--> go to the next block
* 기존 논문과의 주요 차이점 : block boundary detection
- 반복된 토큰에 의한 block boundary 사용하지 않음
- reliable score 계산 방식 변경
* 스트리밍 구조
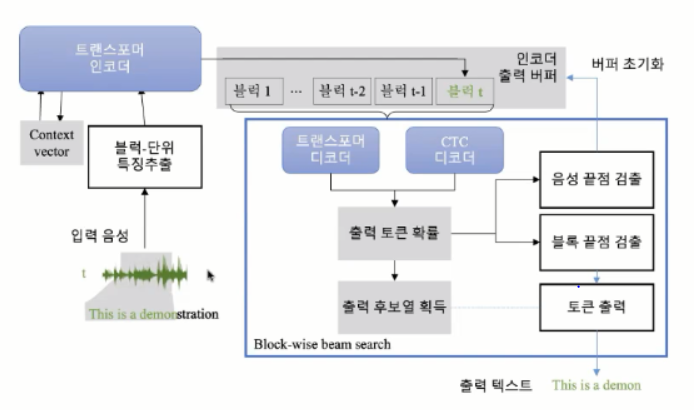
입력 음성이 들어왔을 때 block 단위로 특징을 추출하고 + context vector 계산 --> 이 정보를 가지고 트랜스포머 인코더 통과 --> 트랜스포머 출력을 인코더 출력 버퍼에 저장 --> 출력 버퍼에서 한 블럭씩 데이터를 가져와서 트랜스포머 디코더, CTC 디코더 계산 --> 계산된 값으로 출력토큰 예측 + 확률 계산 --> 확률이 괜찮다면 블록 끝점이 검출 안되었다고 가정하고 다음 출력토큰 계산. 확률이 낮아서 블럭 끝점이 검출되었다면 현재 예측한 토큰은 버리고 다음 인코더 출력 버퍼에서 블럭을 가져와서 출력 토큰을 생성 --> 이 과정 계속 반복하고 음성 끝점이 검출되면 음성인식 종료.
--> 분기를 할 때 인식된 토큰 확률과 끝점 end of speech token 을 따로 가지고 있는데 그것과 비교해서 end of speech 확률이 크면 reliable 하지 않는다고 판단.
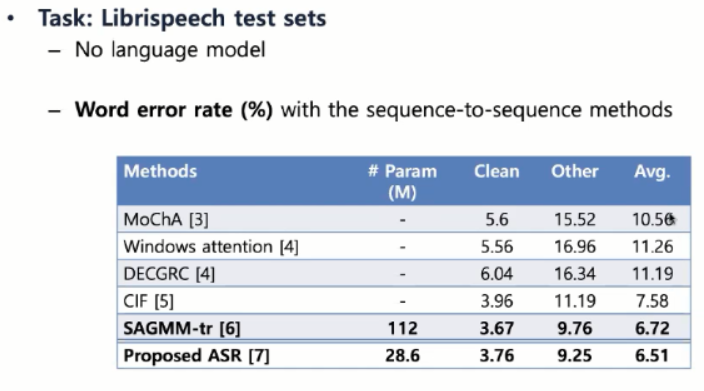
* 실험 및 결과
- Task : Librispeech test sets : no language model
- WER with the sequence-to-sequence methods
- 단말 환경에서 동작 가능한 모델링(작은 모델)임에도 불구하고 기존의 attention 기반 streaming 음성인식보다는 향상된 성능 - 작은 모데리 아니라 큰모델로 실험하면 구글 conformer 기반 성능 나오는 것 확인
- 실시간 음성인식
- 한국어 실시간 음성인식
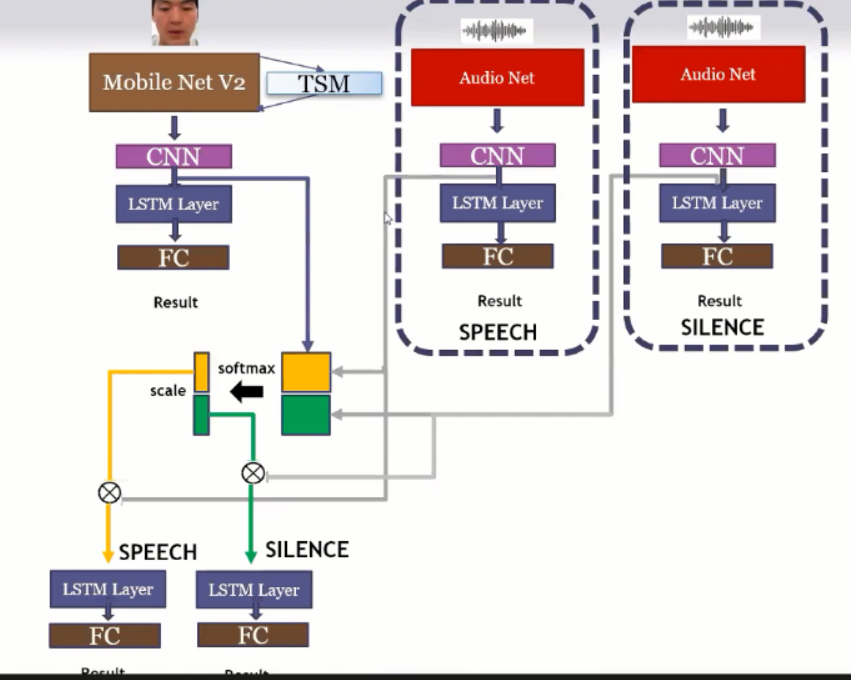
3) 실시간 시청각 발화구간검출 알고리즘
Real-Time Audio-Visual Voice Activity Detection Algorithm
VAD 알고리즘 - 사람이 발화를 할 때 발화 구간에 대해서 포인트를 검출하는 알고리즘
- IOT, Kiosk 등에서 VAD 기술 사용하면 성능향상 가능.
- 현재의 발화 구간 검출은 보통 마이크로폰에 입력된 음성을 통해서 활성화를 구분하는 방식으로 조용한 환경에서 비교적 높은 정확도를 가지고 있음.
- 하지만 주변 잡음이 심한 환경에서는 발화구간 정확히 검출하는 것 매우 어려움.
- 이 연구에서는 마이크 입력 신호 외에 카메라를 이용하여 발화시 화자 입술의 움직임을 검출 + 잡음 환경에서도 강인한 발화구간을 검출하는 기술 제안 + 발화 구간 검출에 사용되는 딥러닝 모델의 경량화를 통해 모델 파라미터 수를 감소시켜 실시간 구동 가능케함
- VAD 사용할 때 음성기반을 많이 사용하는데, 음성기반의 경우 주변 noise 에 취약한 면이 있음. --> 따라서 영상 인식을 추가로 넣어서 멀티 모달 based VAD
Proposed Method
1. Face detection & tracking stage
- 사람이 발화할 때 가장 중요한 부분은 얼굴. 얼굴이 움직이는 걸 감지해야하기 때문에 face detection
1) Data preprocessing
- Track a human face in the video and cut out only the face part.
- Cut out the video using 2D face landmarks and input it into the model.
- We use detection and tracking to explore more robustly.
- A lightweight face recognition technique is used for real-time motion.
- tracking : 2d face alignment 이라는 과정으로 얼굴에서 주요 point 을 잡음.
- detection : 얼굴 점을 잡을 수 있지만 tracking 에 대비해서 시간이 많이 소요되기 때문에, detection과 tracking을 둘다 사용
2. Proposed network model
1) MobileNetV2
- MobileNetV2는 2018년에 나온 논문인데, inverted residuals 과 linear bottlenecks 을 사용하여 모델 파라미터를 줄인 네트워크 모델
- Mobilenetv2 is a network released in 2018 as a complemented network using mobilenetv1.
- The key changes are Inverted Residuals and Linear Bottlenecks.
- Inverted Residuals look like normal Residuals turned upside down.
- Linear Bottlenecks create a linear bottleneck layer, reducing dimensions but retaining important information on the manifold.
2) TSM : Temporal Shift Module
- 효과적인 성능 + 파라미터 감소에 매우 효과적인 방법.
- 일반적인 경우에서 2D CNN 이 3D CNN 보다 성능은 낮지만 파라미터가 매우 적다.
- TSM 의 경우, 2D 를 3D와 같은 입력으로 사용하면서 파라미터 변화는 없도록 하는 방법.
- Temporal Shift Module that enjoys both high efficiency and high performance
- Specifically, it can achieve the performance of 3D CNN but maintain 2D CNN's complexity
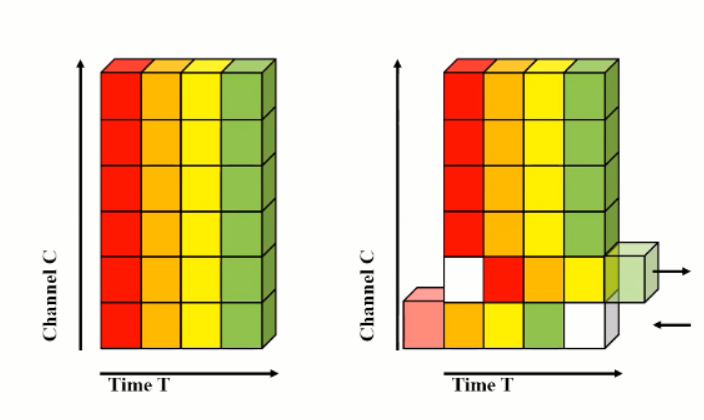
- time 축으로 +-1 씩 shift 과정을 통해 2D feature 을 3D feature 과 같은 느낌으로 사용
- 전체적인 network
'기타' 카테고리의 다른 글
| 2021 한국음성학회 가을 학술대회 리뷰 (3) (0) | 2021.12.05 |
|---|---|
| 2021 한국음성학회 가을 학술대회 리뷰 (2) (0) | 2021.12.04 |
| Intel Korea AI Technical Workshop 2021 리뷰 (0) | 2021.11.24 |


댓글