음성인식(ASR) 이란?
- 사용자의 발화를 입력으로 받아 음성인식을 거친 후 텍스트로 전사하는 과정
- 음성인식
- 사용자의 발화(발음적인 신호 자체에 대한 확률들) = acoustic model
- 발화 자체가 있을 법한 문장인가 = language model

위의 두가지 확률들을 합쳐서, 사용자가 발화를 했을 때 그것이 어떤 말인지 가장 있을 법한 텍스트를 추론하는 것
End-to-End(E2E) ASR
기존 음성인식 모델링
- 입력 음성을 음소 단위로 mapping
- 음소 단위를 다시 텍스트로 전사하기 위해 수 많은 과정을 거쳐야 함
- 이렇게 매우 복잡하기 때문에 진입장벽이 매우 높은 분야 중 하나였음
End-to-End(E2E) 로의 전환
- 기존 방식에서는 음성을 phoneme(음소)으로 모델링 했음
- E2E 에서는 입력 음성을 직접적인 텍스트로 전사한다는 장점
- 모델링 과정이 굉장히 축약됨
- 기존 방법에 비해 모델링 방법이 단순해졌음
E2E 기법 : Attention vs RNN-T
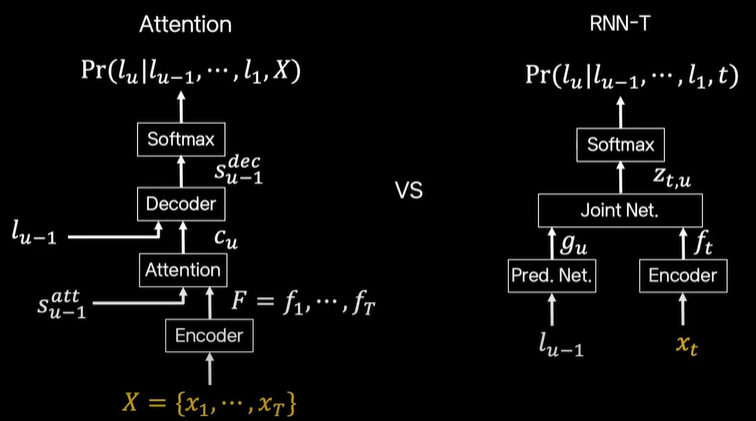
Attention
- x1 ~ xT : 시간에 따른 음성에 대한 feature
- 일정 양의 시간에 따른 음성 입력을 받아서 인코딩한 후 attention을 거치고 디코딩을 해서 lu(캐릭터) 텍스트로 전사
RNN-T
- attention 과 가장 큰 차이점 : xt 를 입력으로 받음
- 즉, 실시간 음성을 받아서 그에 맞는 텍스트를 출력함
Attention vs RNN-T
- 가장 큰 차이점
- Attention : 음성 feature 를 시간에 따라서 다 모아두고 그 다음 처리하는 배치 방식
- RNN-T : 실시간으로 음성을 받을 때마다 처리하는 스트리밍 방식 - 따라서, attention 이 정확도에서는 더 우수함
- attention 은 일정 부분 음성을 다 받고 처리하기 때문에 문맥 정보의 측면에서 장점이 있음 - delay 측면에서는 음성을 다 받고 처리하는 batch 방식인 attention 이 streaming 방식의 RNN-T 보다 느림
Reference
'Spoken Language Processing' 카테고리의 다른 글
| Huggingface 로 wav2vec2.0 실습 - 영어 (0) | 2022.08.18 |
|---|---|
| wav2vec2.0 pretrained 모델로 디코딩하기 (0) | 2022.08.17 |
| Fairseq - Wav2vec 2.0 Pretraining (3) pretraining 시키기 (0) | 2022.06.14 |
| Fairseq - Wav2vec 2.0 Pretraining (2) Preprocess 전처리하기 (1) | 2022.06.14 |
| 딥러닝으로 음향모델 모델링 (End-to-end algorithm) (0) | 2022.06.03 |




댓글