NeurIPS 에서의 < Abstraction & Reasoning in AI systems : Modern perspectives > 강연을 보고 그 중에서도 Francois Chollet 의 "why abstraction is the key, and what we're still missing" 에 대해 정리해보겠다.
(해당 강연은 https://slideslive.com/38935790/abstraction-reasoning-in-ai-systems-modern-perspectives 이 링크에서 확인할 수 있다.)
<1> generalization : what is generalization and why it’s important
- to make progress towards AI, we need to measure & maximize generalization
Generalization 이란?
먼저 generalization 에 대해서 말해보자. generalization 은 무엇이고 왜 중요할까?
- generalization 은 reasoning 과 딥러닝 사이의 intersection 이다.
AI 의 발전을 위해서는 우리는 generalization 을 measure 할 수 있어야 하고, maximize 할 수 있어야 한다.

- Generalization : ability to handle situations or tasks that differ from previously encountered situations.
(이전에 보지 못했던 상황들을 처리하는 능력)
- fundamentally the ability to deal with novelty and uncertainty. (새로운 것과 불확실성)
- this is precisely what you need intelligence for.
- generalization 이 novelty 와 uncertainty 로 설명되는 것처럼, novelty와 uncertainty 자체가 knowledge 와 관련되어 각각 설명되어야지 우리가 generalization의 두가지 형태를 구분할 수 있을 것이다.
** generalization 의 두가지 형태
1) system-centric generalization : ability to adapt to situations that system itself did not previously encounter
(이전에 만나지 못했던 상황에 대해서 적응하는 능력인 일반화)
- 우리가 machine learning 할 때 자주 사용하는 것이고, 이것은 developer aware generalization 에 비하면 much weaker form of generalization 이다.
2) developer aware generalization : ability to adapt to situation that creator of the system could not have anticipated.
(창조자마저도 예상하지 못했던 상황에 대해서 적응할 수 있는 능력의 일반화)
- autonomy(자율성)과 같은 의미이고, the ability to adapt to novelty without the help of a human engineer.
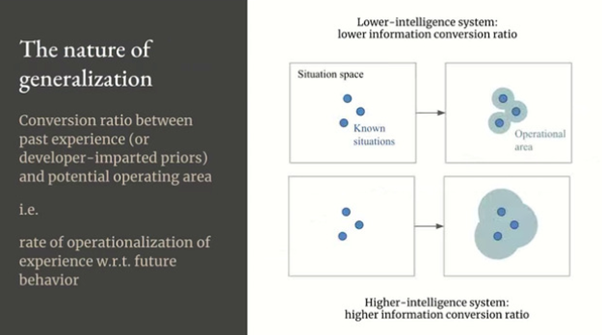
** 중요 **
- generalization characterizes the relationship between the information that you have, your priors as well as your past experience and your operational area over the space of potential future situations that you might encounter, which feature uncertainty and novelty.
(일반화는 너가 지금 가지고 있는 정보와, 너의 과거 정보와, 향후 발생할 수 있는 잠재적 상황들의 관계를 characterize 한다.)
- 따라서 generalization 은 미래 상황을 다루기 위해 과거 정보를 이용하는 효율성이다.
- so you can interpret it as a kind of conversion ratio. 그리고 you can use algorithmic information theory to precisely quantify this ratio. 따라서 generalization 은 미래 행동과 관련된 경험의 operationalizatio 비율이다.

일반화는 일반화 할 수 있고 할 수 없는 이런 양면적인게 아니다.
** it’s actually a spectrum.
- generalization 의 레벨에 따라 AI 시스템을 분류할 수 있다.
** Spectrum of generalization **
1단계) < No generalization >
- 과거 경험 적응하지 않아도 되는 소프트웨어 시스템. novelty 와 uncertainty 없이도 작동되는 정적인 시스템
- ex) 빙고게임같은거나 어떤 데이터 안에서 matching keywords 찾기 게임 같은 경우 해당
2단계) < Local generalization > (robust AI)
- 일반화의 통계적 정의에 해당된다.
- 알려진 정적 분포로부터 새로운 샘플을 처리하는 기능과 같은 known dimensions of variability 에 대한 robustness.
- 머신러닝이 모두 이 카테고리에 해당.
- 이미 알고 있는 세트 안에서 known unknown 을 adapt 하는것.
(머신러닝할 때 dataset 에서 일부 valid set unknown 처리하고 adapt 하는것처럼. 하지만 그 unknown 도 사실은 known unknowns. )
(즉, training data 안의 sample 들 안에서 다양한 정도를 handle 하는 정도.)
3단계) < Broad generalization > (flexible AI)
- adaptation to unknown unknowns within a broad domain
- 2단계와는 다르게 이제는 시스템 만든 사람도 예상 못하는 unknown task도 자율적으로 다룰 수 있는 generalization
- ex) unpredictable 상황 다룰 수 있는 자율 주행, 집에서 집안일 할 수 있는 로봇 정도
4단계) < Extreme generalization > (open-ended AI)
- 임의적인 task에 대해서도 적응할 수 있는 시스템
- 현재는 biological intelligence (생물학적 지능) 만 가능한 영역이다.
- flexible AI 처럼 adaptation to unknown unknowns 까지는 같지만 그 분야가 아까는 within a broad domain 이었다면 이번엔 across an unknown range of domains
위의 스펙트럼을 보면 지금 AI 의 과정의 역사를 볼 수 있다.

- 초창기에는 generalization 을 포함하지 않는 문제들을 봤다면, 그 후 머신러닝(concerned with local generalization) 이 떴고, 그 후 우리는 기계학습을 넘어 실제 세계의 변동성과 불확실성을 다룰 수 있는 시스템을 찾기 시작했다. 왜냐하면 실제 세계는 정적인 분포가 아니니까. 그래서 우리는 self driving, domestic robotics 같은걸 찾게 되는 것이고, 이게 flexible AI이다. 그리고 언젠가 결국 인간과 동물과 같은 수준의 지능을 가질 수 있는 진정한 open ended systems 을 만들 것이다.
** 스펙트럼의 또 하나의 흥미로운 속성은,
스펙트럼이 structure of human cognitive abilities (인간의 인지능력 구조) 를 반영한다는 것이다.

예를 들어 위의 Cattell Horn Carroll 의 인지능력구조 이론을 보면 인지능력을 계층, 계급으로 표현했는데,
가장 낮은 레벨이 task-specific skills(=local generalization), 그 위가 flexible AI(broad AI),
그리고 마지막 레벨이 general intelligence(=open ended generalization) 이다.
- 이 이론에서의 사람의 인지능력구조의 계층 발달과 AI generalization 발달 스펙트럼이 일치한다.

우리가 현재 위 이론에 따라 인간의 인지능력 hierarchy 와 generalization spectrum 을 비교하고 있는데,
먼저 cognitive skill 의 가장 아랫단계인 task specific skill 을 보면,
이 task specific skill 은 우리가 지금 말하는 generalization (=intelligence) 와는 거의 관계가 없다라고 보면 된다.
(왜냐면 generalization은 우리가 할 수 있는 능력(즉 unknown에 대해서도 deal with 할 수 있는 능력)과 우리의 과거와 경험과의 relationship 이기 때문에. 근데 이 task specific 은 given system 에 대해서만의 skill 이니 intelligence 는 거의 없는 것)
일반화의 힘(power)은 skill 과 information(priors)와의 관계로 설명될 수 있는데,
priors 이 적어도 skill 이 높으면 generalization power 이 좋은 것이고,
priors 가 많아야 적정 skill 에 도달한다면 generalization power 이 약한 것이다.
그런데 이렇게 priors 양에 따라서 generalization power 이 정해진다는 것은,
내가 priors, information 을 더 제공하면 결국 generalization 이 필요가 없어질 수 있다는 것.
training data 를 더 제공하거나 인간의 지능을 이용해 pre existing abstraction 을 이용해 시스템에 하드코딩하면 “priors” 를 더 제공할 수 있고, 이 방식으로 일반화의 힘을 키우지 않고도 increase skill 이 가능하다.
이렇게 간단히 priors 를 제공하면서(reducing uncertainty, novelty) 스킬을 increase 할 수 있으니,
skill 은 intelligence 를 characterize 하지 못한다고 할 수 있다.
(왜냐, 스킬이 올라간다고 intelligence(generalization) 가 올라가는게 아니기 때문에. 스킬이 높아도 priors 가 많아서 높아진 경우는 intelligence 가 낮으니까)
다음 글에 이어서 generalization 의 shortcut rule 에 대해 말해보겠다.
(출처 : 해당 글의 이미지들은 NeurIPS 의 < Abstraction & Reasoning in AI systems : Modern perspectives > 강연 발표자료에서 가져왔다. )
'Deep Learning' 카테고리의 다른 글
| Abstraction & Reasoning in AI systems : (3) deep learning with regard to abstraction (0) | 2021.01.30 |
|---|---|
| Abstraction & Reasoning in AI systems : (2) abstraction (0) | 2021.01.30 |
| Abstraction & Reasoning in AI systems : (1-2) generalization (0) | 2021.01.30 |
| Neuro-symbolic AI 에 대해서 (2) neural network + symbolic AI (1) | 2021.01.25 |
| Neuro-symbolic AI 에 대해서 (1) symbolism VS Connectionism (1) | 2021.01.25 |




댓글