이 글은 서울대학교 '최신 인공지능 기술' 강의 중 곽노준 교수님의 'Explainable & Responsible AI' 강의를 듣고 정리한 글입니다.
최근에는 explainable 하면, reliable, responsible 하다 라고 해서 reliable AI, responsible AI 라고도 함.
- 근본적으로 DNN이 있으면, nonlinearity로 input이 있으면 output이 나오는 black box 모델.
- adversarial attack 이 들어오는지, 다른 방법으로 manipulation 하는지 안하는지, output이 왜 이런 결정을 내렸는지에 대해 알기가 불가능.
- Explain을 해보자 하는 관점에서 이런 분야가 생겨남
- Local explainability
- 딥러닝이 나온 직후 2015년 초기부터 지금까지 연구되고 있는 분야
- 이미지가 들어와서 강아지로 판단한다면, 이미지의 어디를 보고 강아지라고 판단했는지 이미지마다 판단
- 각 이미지 샘플마다 다른 이미지를 reference하지 않고, local 이미지만 보고 강아지를 판단한 근거를 찾고자 하는 것
- 이미지 한 장에서 어텐션을 주는 CAM 같은 방식
- ex) CAM, Grad-CAM, IG, SHAP, LRP, SRD - Global explainability
- 최근에는 2020년 이후, 이미지 한장만 가지고 하는 것이 아니라, 이미지 여러 장이 있으면 공통된 feature를 찾아내는 것.
- 운동선수 이미지라고 하면, 이 이미지를 운동선수 이미지라고 판단할 때, 그 이미지 한 장만 가지고 판단하는 것이 아니라, 모자를 쓰고 있다던지, 야구방망이를 들고 있다던지 이런 컨셉을 모으는 것.
- 이미지가 여러 장이 필요하고, 거기서 공통된 부분을 뽑아내다 보니까, 기본적으로 클러스터링 방법을 사용.
- 여러장의 이미지(패치)가 있으면, 클러스터링 알고리즘을 통해 컨셉을 만들고, 클러스터의 대표값(ex. 평균)을 이용해서 컨셉이라고 정의.
- 그 컨셉이 이미지에서 activation이 얼만큼 많이 되었느냐, 어디에서 activation이 되었느냐를 찾아내는 부분이 global explainability 분야.
- ex) TCAV, ACE, CRAFT - Mechanistic explainability
- 아주 최근 (작년 2023부터) 분야
- 네트워크의 레이어가 있으면, 과거에는 local / global explainable 모델을 통해 한 layer을 잡아서 그 layer의 concept을 찾는다던지, 그 레이어에서의 feature map을 뽑아 어디에 attention을 많이 주고 있는지 연구하였음.
- Mechanistic explainability는 layer 사이의 connection.
- i 번째 layer의 concept이 i+1번째 layer의 concept에 어떤 영향을 미쳐서 최종 결론인 강아지라고 결론을 내렸는지.
- ex) i 번째 layer = abstract concept : 털(털의 색깔, 털의 굵기), 코의 모양
이런 것들이 뭉쳐져서 i+1 번째 layer : 코주변에서 털이 나고.. 이러면 포유동물
그 다음 레이어 : 코 눈 입이 합쳐져서 얼굴이 되고..
이런 것들이 뭉쳐져서 그 다음 레이어 : 몸통이 되고...
- 이런 것들을 하고자 하는 것이 mechanistic explainability 에서 추구하는 것.
- ex) GIG
Intro : Interpretability - A challenge in Deep Learning
딥러닝, MLP의 가장 큰 약점 중의 하나는 '설명이 잘 안된다. black box 모델이다'.
중간에 어떤 과정을 거쳐서 output decision을 내렸는지 판단 불가.
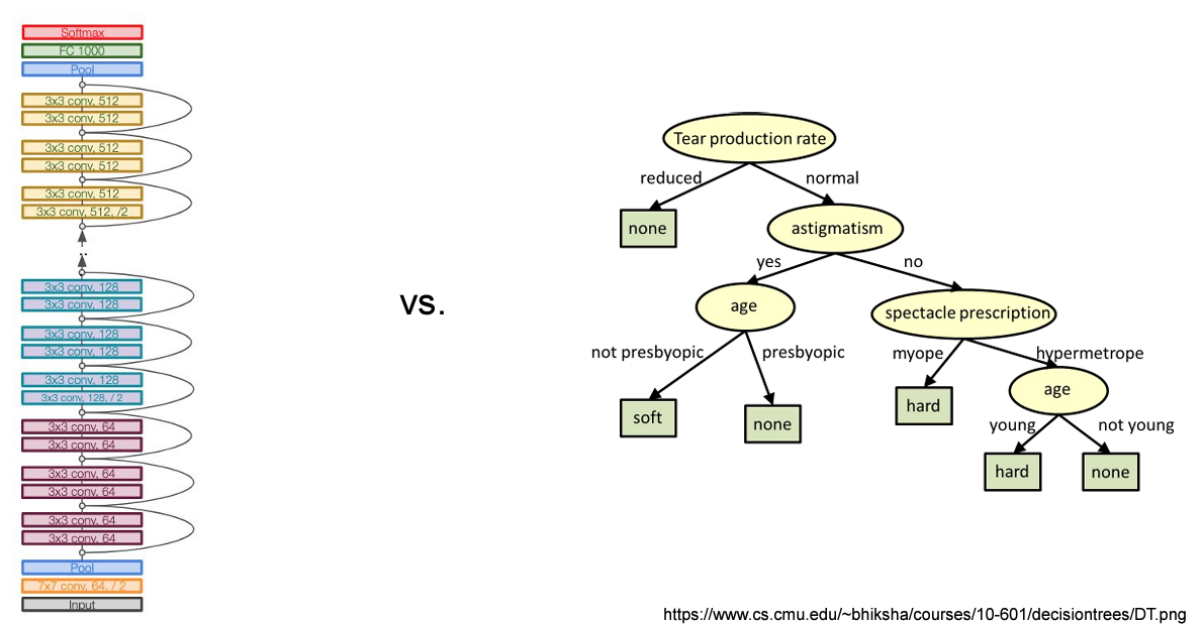
왼쪽 딥러닝이 아닌, 오른쪽 Decision Tree 방법에서는
- training data가 있을 때 feature criteria 에 따라 feature를 하나 고르고, 이 feature를 기준으로 분기를 시킴 (ex. 이것보다 크냐 작냐).
- tree를 학습시키고, 새로운 샘플이 들어오면 판단 가능.
- 이런 Decision Tree 모델은 설명이 가능해서, 이런 모델이 산업에서는 훨씬 많이 사용됨.
- 사람이 눈으로 보면 금방 이해가 가능. Targeted Marketing 분야에서는 거의 이런 모델을 사용했었음.
- ex) 50대 남성, 서초구 사람들은 Genesis를 많이 타더라.. 이런 모델 만들 때 이런 decision tree 모델이 선호되는 이유가 explainable 하기 때문.
Interpretability paradigms
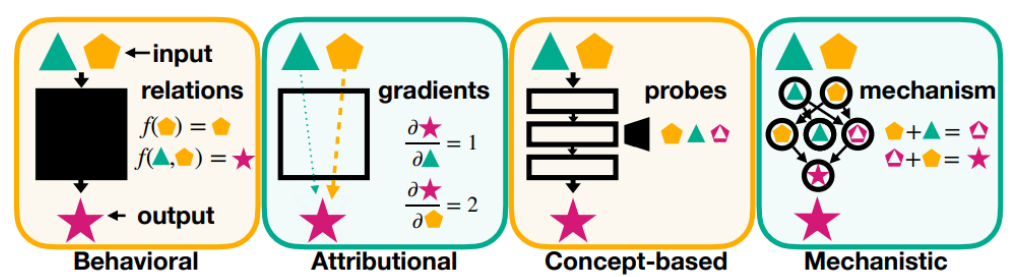
- Behavioral : analyzes input-output relations.
- 그냥 black box 모델.
- input, output 관계에만 초점 맞추고, input 들어가면 함수와 output 알 수 있음.
- feedback 도 없고, gradient 정보도 보통 이용안한다고 보면 됨.
- Local 방법임. - Attributional : quantifies individual input feature influences.
- 사람들이 관심 많이 가지고 있는 모델
- input 집어넣고 output이 나오는데, gradients 정보 활용.
- input과 output의 differential 정보 이용
- 어떤 이미지가 있었을 때 어떤 feature가 output을 만드는데 가장 영향을 많이 미쳤는가.
- linear 모델의 경우, f(x) = wx 에서, w가 가장 큰 feature 가 가장 큰 영향을 미친다라고 볼 수 있음. (sensitivity analysis)
- 즉, gradient-based 방법; individual input이 어떻게 output에 영향을 미쳤는지를 analyze 하는 것.
- Local 방법임. - Concept-based : identifies high-level representations governing behavior.
- Global 방법임; concept 따짐.
- 특정 레이어를 잡은 후, 특정 레이어의 어떤 컨셉이 output에 영향을 미치는지 찾는 것.
- 한 이미지에서 concept 찾을 수도 있지만, 기본적으로 여러 이미지를 모아서 평균적인 것을 찾아 (클러스터링) concept 찾음. - Mechanistic : uncovers precise causal mechanisms from inputs to outputs.
- 모든 레이어의 연관관계.
- 각 레이어 노드마다 concept이 있을텐데, i layer에서는 low-level의 concept, i+1 layer 에서는 high-level의 concept.
- low level의 concept이 서로 어떤 영향을 주고 받고 해서 high level의 concept을 만들어냈는지. - Behavioral --> Attributional --> Concept-based --> Mechanistic 쪽으로 갈수록 explainability 는 높아짐.
- 대신, 많은 정보를 얻으려고 하니 계산량도 많아짐.
Local (Attributional)
Local explanation

- input level 에서 강아지라고 판단내렸을 때, 어디에 초점을 맞춰서 강아지라고 판단했냐.. 이런걸 알아내는 것이 local method.
- 꼭 input에만 적용되는 것이 아니라 중간 layer에도 적용될 수 있음.
- high resolution, low resolution : 인풋은 이미지가 크고, 중간 layer에서는 feature map 이 줄어드는데, 줄어든 feature map에서 어디를 attention 하고 있는지를 찾아내는 것이 local explanation 의 목적.
Examples (in ConvNets)
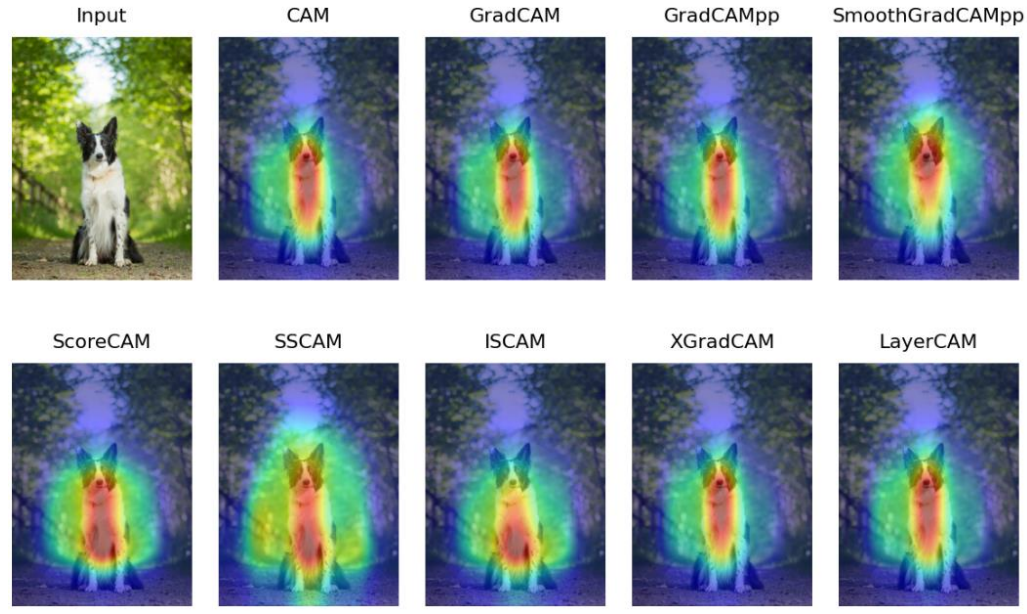
- 다 비슷한 방법들.. 다 강아지에 잘 초점 맞추고 있음..
Class Activation Map (CAM; CVPR'16)
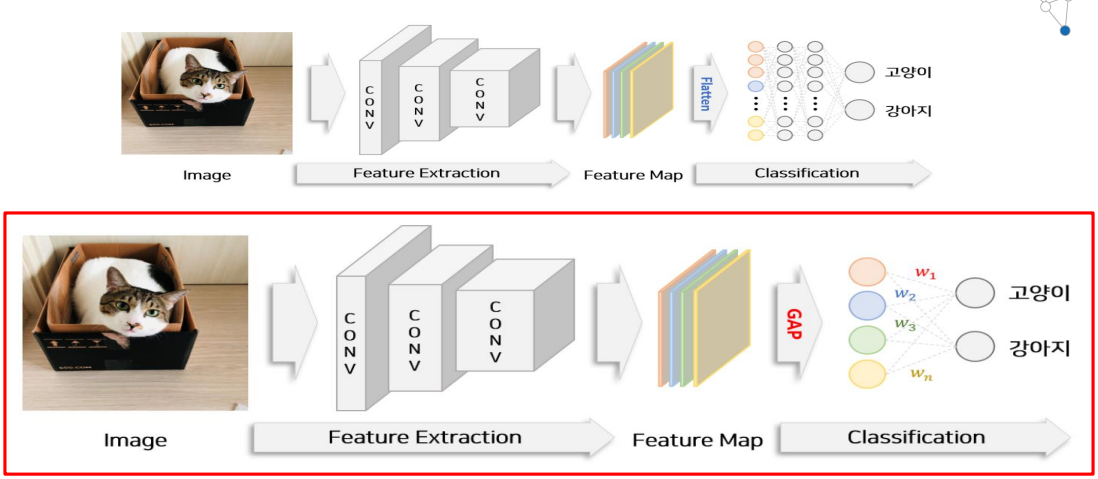
- 아카이브에 2015년에 나온 논문. 그 당시에는 CNN이 대세라서 CNN 가지고 함.
- 이미지가 있으면 CNN 을 거쳐 feature extraction 진행하고, MLP 태우기 전 마지막 레이어를 flatten 함. 그 후 MLP 거쳐서 강아지냐 고양이냐 판단함.
- 아주 최초의 CNN 에서는 flatten 후 MLP 사용하지 않고 SVM 사용했는데, 그 이후 바로 MLP로 바꿈..
- 이미지가 있으면 CNN 을 거쳐 feature extraction 진행하고, MLP 태우기 전 마지막 레이어를 flatten 함. 그 후 MLP 거쳐서 강아지냐 고양이냐 판단함.
- 고양이라고 판단할 때 뭘 보고 판단했냐 알아보려면, MLP 부분을 제거하고 GAP 를 넣어주면 됨.
- Feature Map 이 4개가 있는데, 각각 GAP(Global Average Pooling) 하여 평균.
- 노랑, 초록, 파랑, 빨강 map 모두 각각 평균 냄.
- GAP 거친 4개의 feature map가 나오고, fully connected layer를 하나 만들어서 w1, w2, w3, w4를 고양이와 연결시킴. w1이 빨간 feature map의 중요도가 되고, w2가 파랑색의 중요도... 이런식으로, 이 feature map 에다가 이 w를 곱함.
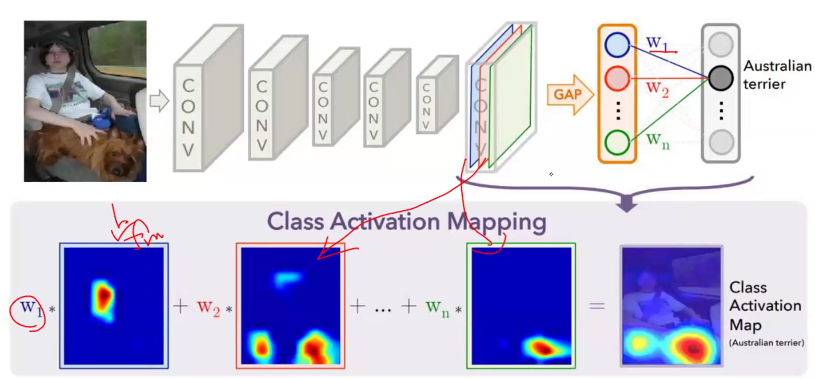
- Feature Map 각각과 w 각각을 곱해준 것을 더한 것 = Class Activastion Map
- 아이디어는 굉장히 간단함.
- 그럼 문제는?
- 이미 training이 끝난 것을 가져와 analysis 하는 것인데, 마지막에 Fully connected layer를 떼버리고 마지막 Feature Map 만 가져와서 feature map에 Global Average Pooling 한 후, w1, w2, .. 값을 얻어내야함.
- 하지만 이 w1, w2, w3.. 값은 아까 떼어버린 마지막 fully connected layer 와는 관련 없는 값이기에, 다시 학습시켜야 함.
- 얕은 layer라서 학습은 빨리 가능하지만, w1, w2, w3, .. 를 포함한 마지막 fully connected layer를 제외한 부분은 freeze 시키고, 이 부분만 다시 training 데이터를 가지고 학습시켜야 한다는 점이 단점.
- 이걸 간단하게 해결한 것이 Grad-CAM.
Grad-CAM (ICCV'17)
- Grad-CAM은 그야말로 gradient 정보를 사용. 기존 CAM은 gradient 정보를 전혀 이용하지 않았음.

- 위 식에서 GAP 부분;
- Z : number of pixels, A : activation map, k : k번째의 채널, i : k번째 채널에서의 i번째의 pixel (spatial) location
- global average pooling 된 feature map 에다가 k번째 feature map의 scalar 값 weight 가 곱해져서 다 더해주는 꼴. 아까 class activation mapping 다 더해주는 그림과 동일.
- 아까 위의 GAP 거치고 pixel 수로 나누어준 상태를 (위의 GAP 빨간 박스) Fk 라고 하면,
- wk는 linear layer 이기 때문에, wk는 y를 Fk로 미분한 값.
- Fk는 모든 픽셀의 average한 것.
--> 각각의 픽셀에 average 를 취한 다음 그걸 summation 했다고 볼 수 있음.
--> 중요한 것은 w의 상대적인 비율이지, w의 절댓값이 아니기 때문에, sum을 하던 average 를 하던 결과는 비슷하게 나옴. - c는 class가 고정된 것을 말함. yc : 강아지 클래스로 고정된 상태.
- 이미지면 logits; 1000개 중 300번째가 강아지라면, 그것만 1, 나머지는 다 0으로 하고 vector gradient 취한 것이라고 보면 됨. 그 gradient를 다 더하면 weight가 나온다는 식이 w의 맨 아래 식.
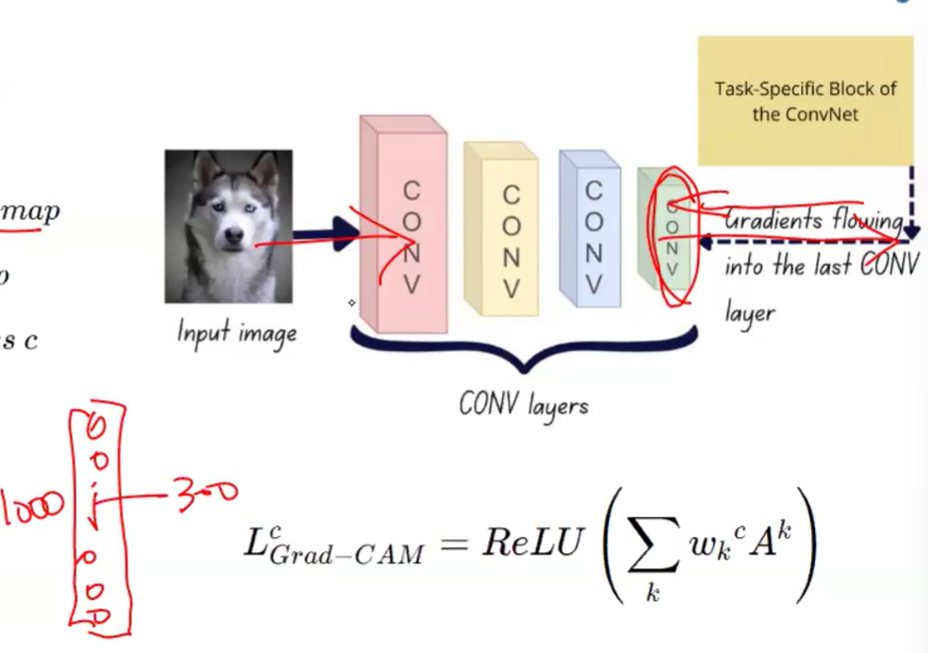
- 즉, Grad-CAM은 아까 CAM과 똑같은 방식인데, weight를 따로 학습하는 것이 아니라, 그냥 이미지만 집어 넣고 forward pass를 한번 거치고, backward를 last cnn layer 까지 거치면, 마지막 cnn output 각각의 pixel 들이 이 output에 얼만큼 영향을 미쳤는지 알 수 있음.
- 그래서 마지막 layer만 계산하면 되니까, 비교적 계산이 빨리 됨.
- Grad-CAM은 마지막 MLP 그대로 쓰는 것임; gradient만 얻으면 되기 때문에, 마지막 부분이 MLP건 뭐건 상관없이, layer가 몇 개든 상관없이 미분만 가능하면 gradient 얻을 수 있음.
- 이제 여기에 변형들이 많이 나오는데, 저 합에 ReLU를 취하기도 함. ReLU 는 negative 가 나오면 무시하겠다는 것.

- Counter factual explanations도 가능; cat에다 gradient를 취하는데, negative gradient를 취해보면 cat이 아닌 곳에 초점을 맞춘다는 것을 볼 수 있음.
- 이런식으로 counterfactual explanation 도 가능.
- Guided Grad-CAM : pure(vanilla) grad-cam 같은 경우, 마지막 feature map에다가만 gradient를 하기 때문에 resolution 이 낮을 수밖에 없음. 따라서 resolution을 좋게, input resolution까지 끌고 오게 하기 위해서 "Guided Grad-CAM"
- Guided back-propagation : 아까처럼 300번째가 강아지라고 했을 때 (target을 [0,0,0,0,..,1,...,0,0,0] 이라고 했을 때) gradient를 마지막 cnn layer 뿐만 아니라 첫번째 cnn layer 까지 계산.
- Guided Grad-CAM : 별건 아니고, 그냥 high frequency 를 exaggerate 한다... 라고 볼 수 있음. gradient 자체가 원래 high frequency에 sensitive 하기 때문에, high frequency를 찾아낸다라고 할 수 있음.
- guided grad-cam은 grad-cam 의 결과에 guided backprop 을 곱한 것이라고 할 수 있음.
- 위 그림을 보면 (c), (i)의 grad cam 결과부분이 guided backprop 느낌처럼 high frequency 부분이 강조되어 나옴.
Grad-CAM++ (WACV'18)
- 기존 grad-cam은 픽셀 위치마다 wk 다 똑같은 것을 사용했었음. 하나의 feature map에서 다 똑같은 scalar w1 값을 곱해주었음.
- ++ 버전은, w 다 다른 값을 픽셀 위치마다 곱해줌. 예를 들어 feature map의 (i,j) 위치마다 다 다른 w값을 곱해줌.
- 그렇게 했더니, 조금 더 성능 좋아지더라~ 정도..
Reference
- Explainable & Responsible AI - Prof. Nojun Kwak, Seoul National University
'Recent Topics in AI' 카테고리의 다른 글
| Explainable AI(XAI), Integrated Gradients [2] (0) | 2024.12.13 |
|---|

댓글