Spoken Language Processing
음성인식을 위한 최신 언어 모델 <1>
햇농nongnong
2023. 4. 6. 20:11
이 글은 Kakao AI Report 의 일부 "음성인식을 위한 최신 언어 모델 리뷰"를 보고 정리한 글입니다.
언어모델이란?
- 언어모델(language model; LM) : 일련의 단어열에 대해 확률을 결정하는 기술
- 즉, 앞서 등장한 단어열을 고려하여 뒤에 이어질 단어의 등장 확률 분포 추정하여, 나왔던 단어열 다음에 어떤 단어가 뒤에 나와야 문장이 더 자연스러운지 확률적으로 추정
- 다음 단어를 추론하고 '생성'하기 때문에 text generation 이라고도 불림.

ex) '오 필승' 단어열 관측, 다음 단어 예측하는데 있어 '코리아' 라는 단어 나타날 확률이 높을 것이고, 가장 자연스러운 단어열일 것임
- 자연스러운 단어열을 찾아야하는 특성 상 2가지 특징 가짐.
- context-dependent : 이전에 관측되었던 단어열을 살피게 되고, 출력은 이러한 단어열을 고려한 결과
- LM 학습시 사용한 DB의 도메인에 민감

ex) "선생님께서 직접 ___ 드셨다" : 보통 '식사를', '분필을' 생각하지만, 의학 DB로 학습한 언어모델이라면, '메스를' 처럼 의학 관련 단어가 나타날 확률 높음.
언어모델의 활용
- 언어모델은 음성인식(ASR), 기계번역(MT), 검색어 추천 및 맟춤법 검사 등 '언어' 다루는 다양한 영역에서 유용하게 사용됨.

- ASR : 입력된 음성을 단어열로 추론하는 과정에서 LM을 이용하여 더욱 자연스러운 단어열로 완성될 수 있도록 확률 가중
- MT : 한 국가 언어의 단어열 입력되면, 해당 단어들과 비슷한 의미 가진 다른 국가 언어 단어열로 치환되어 출력
- 검색어 추천 : 사용자가 단어열을 입력하면 입력된 단어열 기반으로 LM 통해 이어줄 다음 단어열 추천
- 맞춤법 검사 : 단어열 속에 틀린 단어 있을 때 LM 으로 문법 맞도록 자연스럽게 수정
LM 구현 방식
1) 전통적 방법 - 통계 기반 언어 모델(Statistical Language Model, SLM)
2) 인공 신경망 - 신경망 기반 언어 모델(Neural Network Language Model, NNLM)
- SLM : 관측 빈도수 기반의 확률(관측된 단어열 다음에 어떠한 단어가 얼마나 자주 등장했는지 의미) 이용 모델
- 통계 기반 지식으로 확률 결정 - 구현 난이도 비교적 낮음
- 관측된 단어열 기반으로 확률이 추정되는 방식이라, 이전 단어열이 관측되지 않았을 경우 확률이 정의되지 않는 sparsity 문제 나타남
- 이를 해결하기 위해, 이전 단어열 모두를 고려하지 않고 일부만 고려하여 관측되는 빈도수를 높이는 n-gram 방식 등장 - but, 이것 역시 이전 N-1 개의 단어만을 고려하여 긴 문맥을 고려 못하는 long-term dependency 문제 가지게 됨.
- NNLM : 다양한 신경망 구조 이용해서 다음에 나타날 단어에 대한 유사도를 바탕으로 확률 결정하는 모델
- 위의 sparsity, long-term dependency 문제 해결
- 단어 간의 의미적 유사도를 학습하는 메커니즘 통해.
- 이전 단어열의 global한 context 정보 반영.
- 신경망 구조 고도화되고 커지면서 성능도 발전하고 있음.
- BERT나 GPT-3 같은 고성능의 신경망 구조 NNLM에 적용되고 있음.
- 위의 sparsity, long-term dependency 문제 해결
음성 인식을 위한 언어 모델 적용 방법론
음성인식기는 크게 GMM-HMM, E2E 음성인식기 두 가지로 나뉨.
1) GMM-HMM : Gaussian Mixture Model - Hidden Markov Model alignment 기반의 하이브리드 음성 인식
2) E2E : frame별 음소 정보나 별도의 모듈을 미리 구성해줄 필요 없이 입력 음성열을 문자열로 매핑하는 end-to-end 음성 인식
- 음성과 전사된 데이터인 label / pseudo label 이용하여 쌍으로 이루어진 데이터셋에 대해서만 학습이 이루어짐.
- 음향모델(Acoustic Model) 또는 ASR 시스템만으로는 context dependency를 반영하는데 부족할 수 있음.
- 이를 보완하기 위해 LM 더함
- 상대적으로 수집이 쉽고 쌍으로 이뤄지지 않은 데이터로 미리 학습한 사전지식 활용
- context dependency를 사후 분포에 더욱 더 반영 가능
- 대다수의 연구에서 음성인식기에 LM 함께 사용하면 성능 오른다는 결과 보임.
하이브리드 음성인식 (GMM-HMM)
음성인식기는 크게 GMM-HMM, E2E 음성인식기 두 가지로 나뉨.
- GMM-HMM : GMM-HMM alignment 기반으로 음소를 추정하고 WFST(Weighted Finite-State Transducer)를 사용하여 주어진 음성을 단어열로 디코딩하는 방법.

- 일반적으로 별도의 AM, LM 및 발음 사전으로 구성됨.
- 디코딩 과정에 n-gram 언어 모델을 사용하여 hypothesis 도출.

- 이를 node와 연결된 arc마다 단어가 나타날 확률을 부여한 격자(Lattice)로 생성하여 최적의 경로 및 결과를 찾아내게 됨.
- 이 과정에서 n-gram 언어 모델이 전통적으로 사용됨.
- n-gram은 대표적인 SLM(Statistical Language Model) 방법 중 하나로, 앞선 n-1 개의 단어열만을 고려하여 확률을 정의하는 방식.
- 하지만, n-gram LM은 통계 기반의 LM이라는 특성상 이전 단어열이 관측되지 않았을 경우 확률이 정의되지 않는 sparsity 문제 + 이전 n-1 개의 단어만 고려해서 긴 문맥 고려 못하는 long-term dependency 문제 발생.
- 반면, NNLM은 모든 단어에 대한 확률값 출력해서 유한 상태의 static 그래프인 단어 격자 이용하는 하이브리드 음성 인식에 직접적으로 사용하기 어려움.
Rescoring
- 이를 해결하기 위해, 여러 번의 디코딩 과정 거치는 multi-pass method 이용 - sparsity, long-term dependency 문제 모두 해결하는 NNLM의 장점과 단어 격자 생성하는 n-gram 모두 이용 가능.
- 보통 간단하게 two-pass method 사용.
- 1st pass 디코딩 : n-gram 언어 모델 이용해서 단어 격자 형성
- 2nd pass : NNLM 으로 1st pass 디코딩 결과물을 입력으로 사용하여 최종적으로 결과 내는 방식.
- 이를 rescoring 방식으로 진행 - 현재의 언어 모델에 더 global한 context 정보 반영하기 위해 제안된 방법
- 하이브리드 음성인식에서 rescoring 방법 크게 두가지
- N개의 최상 결과물 이용하는 N-best list rescoring
- n-gram 결과물인 격자의 score 재설정하는 lattice rescoring.
- 하이브리드 음성인식에서 rescoring 방법 크게 두가지
N-best list Rescoring
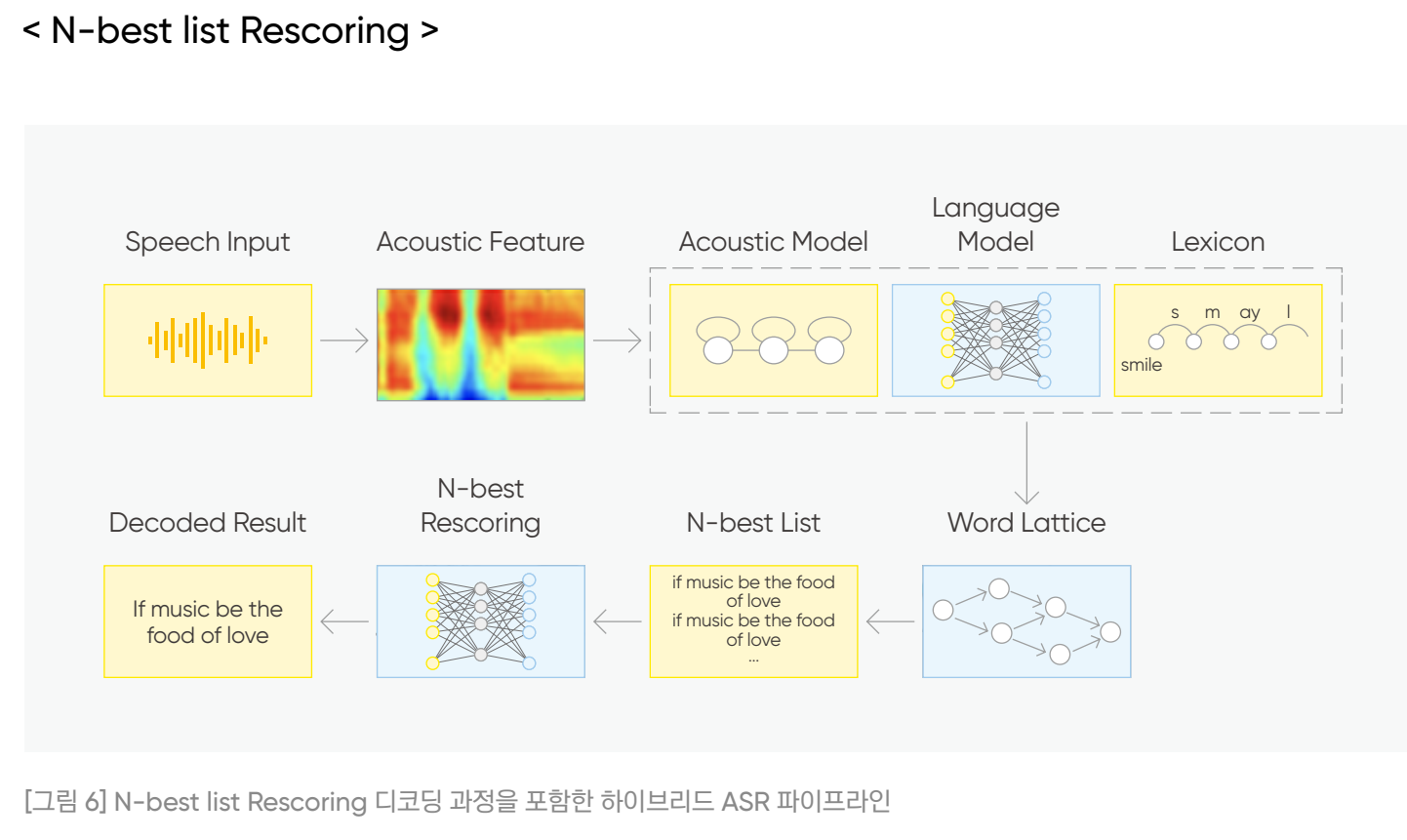
- N-best list rescoring : 이전 디코딩 과정으로 n-best hypotheses 도출 후, 각각의 hypothesis에 대한 score를 새로운 LM으로 재설정하여 다시 순위를 매기는 방식.
- 하이브리드 음성 인식에서 N-best list rescoring은 1st pass 이후 단어 격자 생성되면, path 별로 AM과 LM의 결합 확률을 내림차순 정렬하여 상위 N개의 path 도출됨.

- (1) : 1st-pass 디코딩 - tri-gram LM 사용
- π : 최종 결과물인 단어열
- A[πN] : AM으로부터 도출된 단어열인 경로 πN에 대한 log 확률
- Lold[πN] : tri-gram LM의 log 확률
- (2) : 2nd-pass로 RNNLM 사용
- Lnew[πN] : RNNLM의 log 확률
- 기존에는 단순하게 디코딩 한번을 통해 생성한 격자 내에서 1-best 결과물을 최종출력했지만,
- 이를 (1) 식과 같이 top-N 개 결과물인 AM과 LM 결합 확률을 내고
- (2) 식처럼 long-term dependency를 더 반영할 수 있는 RNNLM으로 score를 다시 매겨 1-best를 출력하는 것.
- 기존의 n-gram 통한 N개 결과물을 보다 고성능의 LM으로 global context 정보 반영하여 조금 더 '그럴듯한' 문장 선택하는 방식.
- N-best list rescoring은 간단하고 직관적이라는 장점 때문에 자주 이용되지만,
- 이전 디코딩 결과에서 확률 높은 N개 추출하여 multi-pass 디코딩에 사용 - 이전 디코딩에 사용된 언어 모델에 편향되기 쉽고, 계산이 N 설정에 따라 선형적으로 증가한다는 단점.
Lattice Rescoring
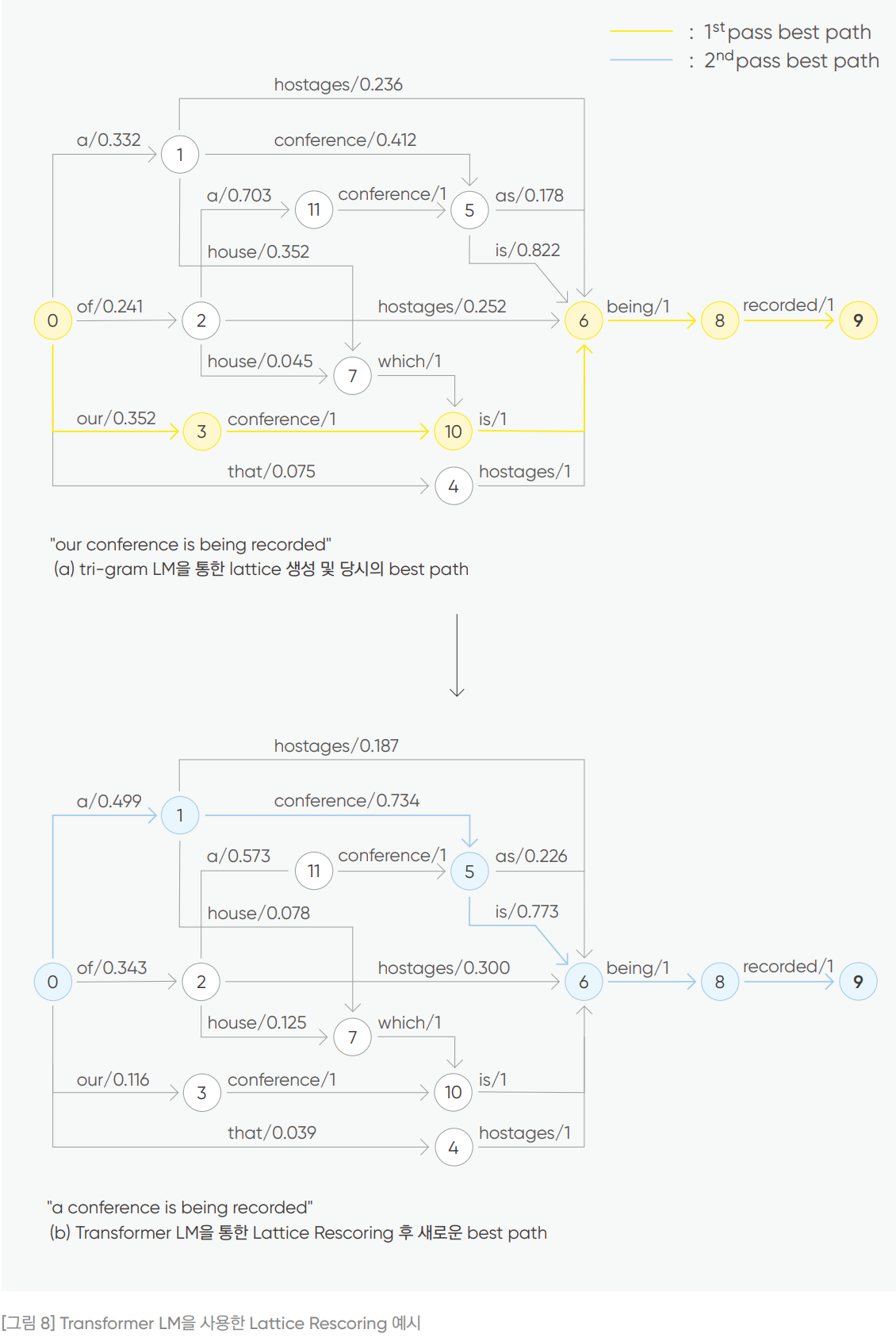
- N-best list Rescoring 단점 보완 위해 Lattice Rescoring 제안됨.
- 기존 n-gram LM 통해 생성된 격자를 바탕으로 격자 내 모든 경로의 score에 대해 새로운 LM으로 rescoring 하는 방식.
- 격자가 형성되면, 위 그림8의 (a) 처럼 arc 마다 단어의 확률이 할당되어 있는데, n-gram LM 통해 이 격자 구조는 그대로 유지 + 다른 LM 이용 arc 확률 score 다시 매기게 됨.
- 이후 새롭게 score 가 형성된 격자 구조에서 1-best 단어열 도출.
- 격자 구조 전체를 고려하기 때문에, 이전 top-N개의 단어열만을 각각 고려하는 N-best list Rescoring보다 계산량과 global context 정보 반영에 있어 효율적.
Reference
- Kakao AI Report "음성 인식을 위한 최신 언어 모델 리뷰" - 강지훈