Spoken Language Processing
kaldi CSID (substitution, insertion, deletion) 발음 오류 패턴 분석, wer 계산
햇농nongnong
2022. 11. 17. 18:23
2022 AI 학습 데이터 활용 해커톤에 참여하게 되면서 외국인 학습자들의 한국어 발음 분석을 해보았다.
외국인의 한국어 발화 데이터를 활용하여 권역별(국가별) 발음 오류 패턴을 비교 분석하는 과제이고, 최종적으로 Chinese, Spanish, English L1 학습자의 한국어 발음 오류 패턴을 제시하였다.
- 발음 오류 패턴 분석을 위하여 CSID (correct, substitution, deletion, insertion) 오류를 사용함
- 위의 CSID 를 구하기 위해 칼디 툴킷을 사용함
ref 와 hyp 파일 만들기
- CSID 발음 오류 패턴 분석은 정답 음소열과 음소인식기를 돌린 결과 음소열을 일대일 대응시켜 해당 자리에 정답 음소열이 있는지 비교하는 것임
- Substitution 치환, Deletion 삭제, Insertion 삽입 으로 오류를 나타낼 수 있음
- Kaldi 를 사용하면 위의 CSID 를 쉽게 구할 수 있음
먼저 정답 음소열(ref)과 인식결과 음소열(hyp) 파일을 만들어 주어야함.
- 정답 음소열 파일명은 "ref" 로 저장
- "번호 tab 문장" 형태로 파일 만들기
ref

- 음소인식기에 넣어 인식된 결과 음소열 파일명은 "hyp" 로 저장
- "번호 tab 문장" 형태로 파일 만들기
hyp

- 위와 같이 만들기 위해 먼저 데이터셋부터 확인해보자.

위의 ans 를 받아서 ref 를 만들고, rec 를 받아서 hyp 를 만들 것이다.
ref 작성하기
import re
regex = "\(.*\)|\s-\s.*"
tsv_list = []
i = 0
ans2 = []
for answer in ans:
answer = re.sub(regex, '', answer)
answer = answer.replace("[", "")
answer = answer.replace("]", "")
answer = answer.replace(" ", "")
answer = answer.replace("',", " ")
answer = answer.replace("'", "")
answer = answer.replace(",", "")
ans2.append(answer)
tsv_line = str(i) + '\t' + answer + '\n'
tsv_list.append(tsv_line)
i = i+1
with open('/home/haeyoung/korean/ref', 'w') as f:
for line in tsv_list :
f.writelines(line)
hyp 작성하기
import re
regex = "\(.*\)|\s-\s.*"
tsv_list2 = []
i = 0
rec2 = []
for recog in rec:
recog = re.sub(regex, '', recog)
recog = recog.replace("[", "")
recog = recog.replace("]", "")
recog = recog.replace(" ", "")
recog = recog.replace("',", " ")
recog = recog.replace("'", "")
recog = recog.replace(",", "")
rec2.append(recog)
tsv_line2 = str(i) + '\t' + recog + '\n'
tsv_list2.append(tsv_line2)
i = i+1
with open('/home/haeyoung/korean/hyp', 'w') as f:
for line2 in tsv_list2:
f.writelines(line2)
이렇게 해서 만들어진 ref 와 hyp 를 가지고 칼디를 통해 CSID 를 구해보자.
Kaldi 의 compute-wer : wer(word error rate) 구하기
kaldi 의 compute-wer 를 통해 간단히 전체 utterance 에 대한 wer 결과를 구할 수 있음.
- 먼저 . ./path.sh 를 실행하여 칼디를 설치한 경로 설정을 해준다.
( /home/haeyoung/kaldi/egs/wsj/s5/path.sh 에 위치함)
. ./path.sh- 이 때 path.sh 파일에 경로 설정을 미리 해두지 않았다면, vi path.sh 로 아래 첫줄과 같이 경로를 설정해주기
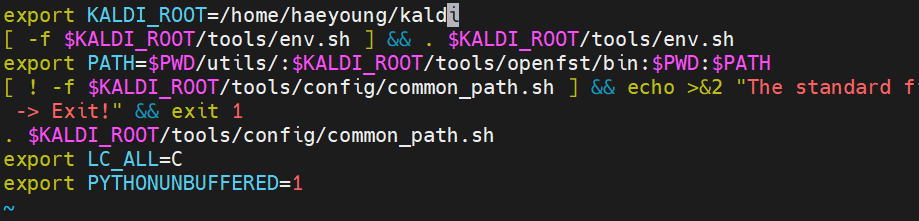
- compute-wer 명령을 통해 전체 utterance 에 대해 wer 을 계산하여 wer_results 파일로 저장
compute-wer ark:ref ark:hyp > wer_results- 문장별 wer 구하고 싶으면 문장마다 ref 와 hyp 만들어서 루프 돌리면서 compute-wer 실행
wer_results

Kaldi 의 align-text : wer_per_utt_details.pl 사용
kaldi 의 align-text 의 wer_per_utt_details.pl 을 사용하여 전체 발화에 대한 CSID(correct, substitution, insertion, deletion) 을 구할 수 있다.
- 먼저 . ./path.sh 를 실행하여 칼디를 설치한 경로 설정을 해준다.
( /home/haeyoung/kaldi/egs/wsj/s5/path.sh 에 위치함)
. ./path.sh
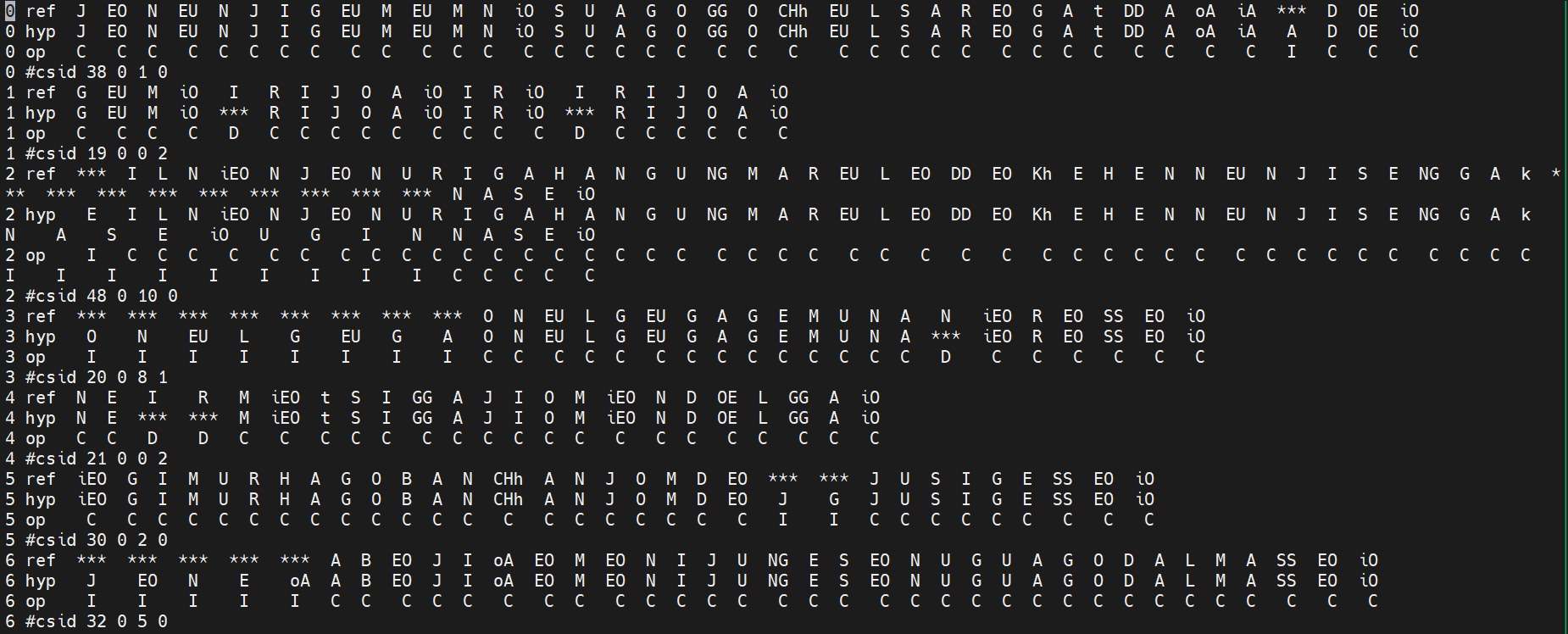
- align-text 를 통해 각 문장별 C, S, I, D 결과를 담은 per_utt_results 파일 만들기
align-text --special-symbol=“***” ark:ref ark:hyp ark,t:- | utils/scoring/wer_per_utt_details.pl --special-symbol “***” > per_utt_results
- per_utt_results 에서 문장별 C, S, I, D 결과를 확인할 수 있음
per_utt_results
Reference
GitHub - hy310/Korean_pronunciation_analysis: 외국인의 한국어 발음 오류 패턴 비교 분석입니다.
외국인의 한국어 발음 오류 패턴 비교 분석입니다. Contribute to hy310/Korean_pronunciation_analysis development by creating an account on GitHub.
github.com