Spoken Language Processing
wav2vec2.0 pretrained 모델로 디코딩하기
햇농nongnong
2022. 8. 17. 20:26
Facebook - wav2vec2.0 개념 설명
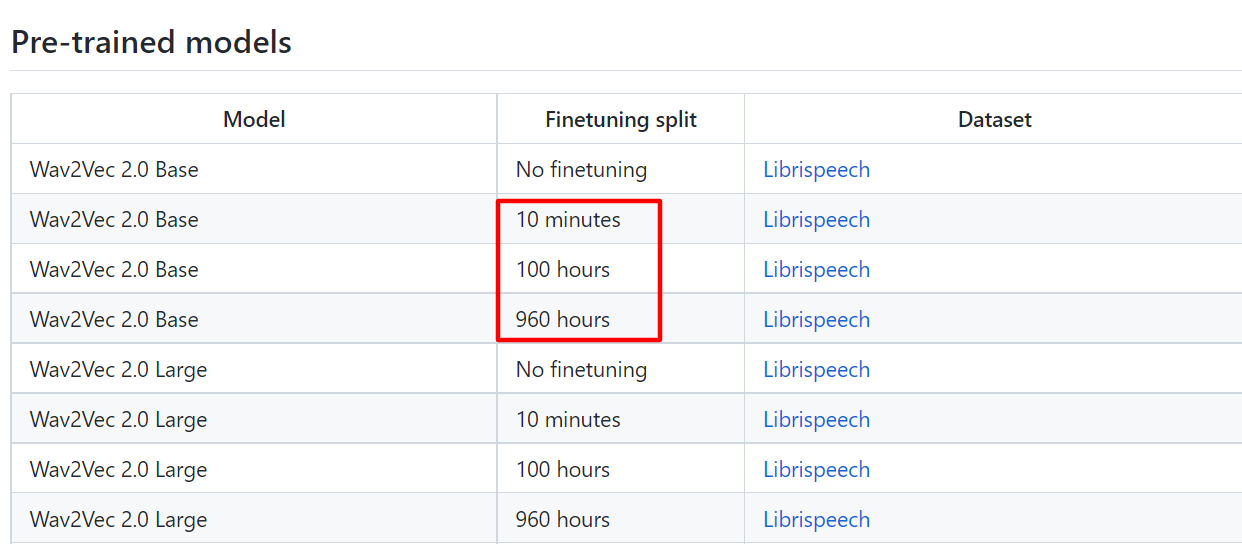
- Facebook 에서 약 5만 시간의 데이터를 훈련시켜 음성인식 pretrained 모델을 만들었음
- 5만 시간이라는 대량의 데이터로 훈련할 수 있었던 이유는 label 이 없는 데이터이기 때문에 가능했었음
- 즉, 라벨이 없는 데이터를 이용하여 자기 자신의 특성(representation)을 배우는 학습 방법인 self-supervised learning (자기지도학습)을 통해 만든 pretrained 모델 - 물론 finetuning 할 때 더 큰 데이터일수록 좋지만, 960hrs, 100hrs, 10m 비교했을 때 10m 모델로 fine-tuning 해도 충분히 좋은 결과가 나옴
- 즉, pre-trained 모델만 잘 만들어두면, 내가 가지고 있는 데이터셋이 많지 않아도 fine-tuning 했을 때 어느정도 성능이 나옴 --> 대단한 발전

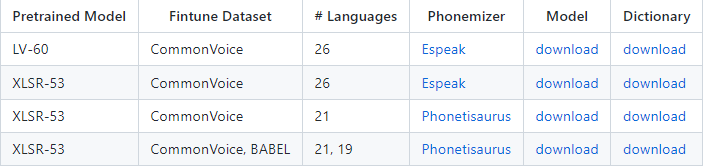
- 이 컨셉을 더 확장시켜 보면 --> XLSR-53 모델
- MLS(Multilingual libriSpeech), CommonVoice, BABEL 의 데이터셋을 이용하여 53개의 언어 & 약 56000 시간의 데이터를 모아 pretrained model 인 XLSR-53 모델을 만들었음
- 이 pretrained 모델을 가지고 각 언어별로 fine-tuning 해서 모델을 공개하기도 함
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
즉, 정리하자면
facebook/wav2vec2-base-960h
: wav2vec2.0 backbone 모델(약 5만 시간의 모델)을 이용해서 Librispeech 960hrs finetuning을 해서 나온 모델
모델을 살펴보면,

- 모델 안에 submodel 들이 다 존재
- feature extractor, feature projection, encoder 등등

- 맨 앞에 feature extractor 부터 시작해서, 마지막에 dropout 과 linear layer 까지
- out_features = 32 : 알파벳 + 특수기호
- backbone 인 pretrained model 에서 feature 를 추출해서 마지막 output 알파벳으로 뭐가 나와야할까
= 32개로 맞춰주는 것 - 이런식으로 fine-tuning 하게 됨 - fine-tuning
- target description 이 있고, 그것에 맞춰 Loss 값을 정의, optimizer 이용해서 gradient 계산해서 update 해줌
wav2vec2.0 의 pretrained 모델을 이용하여 디코딩하기
def map_to_array(batch):
speech, sr = sf.read(batch["file"])
batch["sampling_rate"] = sr
batch["speech"] = speech
return batch
- 데이터셋 : vector, list 를 다루는 대표적인 3가지 함수인 map, reduce, filter 중 mapping function 사용
- batch 를 input 으로 넣어줌
- batch["file"] : <file> 경로의 input batch file
- 해당 파일을 soundfile 이용해서 speech 와 sampling rate 로 바꿔줌
- batch 로 return
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
- Librispeech 의 데이터를 가져와서 map_to_array를 실행하면 sampling_rate 와 speech 가 추가된 것 확인 가능
input_values = processor(ds["speech"][0], sampling_rate=16000, return_tensors="pt").input_values # Batch size 1
input_values.shape # torch.Size([1, 174160])
- 여기서 speech는 모든 speech data 가능. ex) 감정분류데이터, 마비말장애데이터, 방언데이터
- 위의 speech vector 하나를 넣어주고 sampling rate 를 넣어주는 등 input_value 만들어주기
- 인풋의 크기(차원)를 살펴보면 174160
- raw waveform 을 썼기 때문에 엄청 김 : 16000 sampling rate 라면, 174160 / 16000 = 약 11초 분량의 데이터
logits = model(input_values).logits
logits.shape # torch.Size([1, 544, 32])
- 이런 파일을 pretrained model 에 넣어주게 되면 logits 이 나오게 됨
- 32 는 알파벳 + 특수기호의 output projection
- 이렇게 해서 나온 features : concatenate / attention 해서 사용
predicted_ids = torch.argmax(logits, dim=-1)
predicted_ids.shape # torch.Size([1, 544])
- argmax 를 하면 logits 값 중 가장 큰 것이 나옴
- argmax 를 통해 pretrained + fine-tuning 중 가장 대표적인 값을 뽑기
transcription = processor.decode(predicted_ids[0])
transcription # BECAUSE YOU ARE SLEEPING INSTEAD OF CONQUERING THE LOVELY ROSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BAW WHILE POOR SHAGGY SITS THERE A COOLING DOVE"
# compute loss
target_transcription = "BECAUSE YOU ARE SLEEPING INSTEAD OF CONQUERING THE LOVELY ROSE PRINCESS HAS BECOME A FIDDLE WITHOUT A BAW WHILE POOR SHAGGY SITS THERE A COOLING DOVE"
# wrap processor as target processor to encode labels
with processor.as_target_processor():
labels = processor(target_transcription, return_tensors="pt").input_ids
loss = model(input_values, labels=labels).loss
print(loss) # tensor(12.9110, grad_fn=<SumBackward0>)
- predicted_ids[0] 이 다 숫자로 되어있기 때문에, 이것을 다시 디코딩해서 문자로 바꿔주기
- 이렇게 해서 나온 "transcription" 이 모델에서 추측한 output 이고, 이 것을 정답 값인 target_transcription 과 비교해서 그 차이를 줄여주는 방식으로 fine-tuning 을 하게 됨 - 이렇게 나온 loss 12.9110 은 첫번째 문장 하나에 대해서 정답 값과 추측 값을 비교해서 나온 첫번째 loss 값
- 이제 데이터 전체에 대해서 위의 과정으로 훈련시키면 여러개의 loss 가 나오고, optimize 해서 학습
- 모델 자체는 위 model 에서 보여줬던 아주 깊은 딥러닝 pretrained 모델을 이용하는 것임
** 총정리
import torch
from transformers import Wav2Vec2FeatureExtractor, Wav2Vec2ForPreTraining
from transformers.models.wav2vec2.modeling_wav2vec2 import _compute_mask_indices
from datasets import load_dataset
import soundfile as sf
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("patrickvonplaten/wav2vec2-base")
model = Wav2Vec2ForPreTraining.from_pretrained("patrickvonplaten/wav2vec2-base")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
ds = ds.map(map_to_array)
input_values = feature_extractor(ds["speech"][0], return_tensors="pt").input_values # Batch size 1
# compute masked indices
batch_size, raw_sequence_length = input_values.shape
sequence_length = model._get_feat_extract_output_lengths(raw_sequence_length)
mask_time_indices = _compute_mask_indices((batch_size, sequence_length), mask_prob=0.2, mask_length=2, device=model.device)
with torch.no_grad():
outputs = model(input_values, mask_time_indices=mask_time_indices)
# compute cosine similarity between predicted (=projected_states) and target (=projected_quantized_states)
cosine_sim = torch.cosine_similarity(
outputs.projected_states, outputs.projected_quantized_states, dim=-1
)
# show that cosine similarity is much higher than random
assert cosine_sim[mask_time_indices].mean() > 0.5
# for contrastive loss training model should be put into train mode
model.train()
loss = model(input_values, mask_time_indices=mask_time_indices).loss
print(loss)
* 결과화면

Reference
- SpeechJJong 님의 <Timit Dataset을 이용한 huggingface wav2vec2.0 colab 실습 - part1> 강의
https://www.youtube.com/watch?v=pwX0IvO0YTU