Phoneme mispronunciation detection by jointly learning to align - Binghuai Lin, Liyuan Wang @ ICASSP 2022
Phoneme mispronunciation detection by jointly learning to align - Binghuai Lin, Liyuan Wang @ ICASSP 2022 논문 리뷰 글입니다.
Abstract
주제 : phoneme mispronunciation detection
아이디어 : 발음 오류 탐지를 위해 alignment 도 동시에 같이 학습하겠다.
- multi task learning 을 통해 phoneme alignment 와 mispronunciation detection 을 같이 최적화하겠다.
- alignment 를 하기 위해 음성과 텍스트 정보가 필요 - 그리고 이로부터 각각 acoustic representations, canonical phoneme representations 을 얻어야 함
- 위 representations 은 각각 acoustic encoder, phoneme encoder 에서 뽑음
- attention 기법을 사용해서 두 representations 를 frame 단위에서 엮음
- MDD task 는 결국 '어떤 음성을 듣고 이건 어떤 phoneme 이다.' 하고 예측하는 classification 문제임
- 따라서 분류를 하는 판단기를 만들어야 함
- CNN 을 먼저 깔고, 그 이후 FC 를 두 개 깔아서 하나는 MD 문제, 다른 하나는 alignment 문제로 해서 두 가지를 엮는 multi task learning 의 방법으로 학습
- data 는 L2-arctic 을 사용하고 SOTA 성능을 보임
1. Introduction
Mispronunciation Detection(MD) task 를 접근하는 두 가지 방법 : ASR-based, Feature-based
ASR-based methods
그동안의 흐름
1) Extended Recognition Network (ERN) with phonological rules
- Extended Recognition Network (ERN) 사용해서 음운규칙을 같이 적용
2) Acoustic-Phonemic Model (APM) to calculate phone-state posterior probabilties based on DNN to generate recognized phoneme sequences
- acoustic phonemic model 로 발전
3) CNN-RNN-CTC based recognition achieved great improvement than previous works
- 딥러닝 적용한 cnn-rnn-ctc based
4) Hybrid CTC-Attention with anti-phone modeling technique
5) wav2vec 2.0 optimized by CTC loss
- 그 다음 wav2vec 까지 발전
ASR-based MD 예시 )

- '안녕' 을 '아넝' 이라고 잘못 발음된 음성을 phone ASR 에 넣고, ASR 결과로 'aa', 'nn', 'oo', 'ng' 가 나옴
- 하지만 잘못 발음된 실제 정답은 'oo' 가 아닌 'eo' 임
- 따라서 확률적으로 3/4 로 보고, mispronunciation detection 성능으로 75% 라고 함
* Limitations
- should be guaranteed to cover all mispronunciations in the dictionary
- wav2vec 으로 넘어가면서 조금 해소된 문제지만, ASR 이라는 것이 발음사전을 통해 인식기가 lexicon 에서 가져와서 인식하는 것. 따라서 MD task 에서도 ASR 을 통해서는 mispronunciation 조차도 발음 사전에 들어가있어야지만 인식기가 lexicon 에서 가져와서 인식할 수 있음. (이게 전통적 ASR-based methods 의 고질적인 문제점)
- Inconsistency of optimization goals between ASR and mispronunciation detection
- 전통적인 ASR-based method 의 경우, ASR 성능의 optimization 과 MD 성능의 optimization 이 일치하지 않음
- ASR 성능의 optimiation : P(O/W) 값을 최대화 하는 방향
- MD 성능의 optimization : y (canonical pronunciation) 와 y hat (predicted pronunciation) 간의 cross-entropy 최소화 하는 방향
- task 자체는 MD 인데, ASR 의 목표와 MD 의 목표가 불일치함.
Feature-based methods
- Focus on optimization of feature extraction
- 이전, ASR-based 방법에서는 음성 인식이 주요 issue 라면, 여기서는 음향특징을 뽑는데 관심 - Goodness of Pronunciation (GOP) for pronunciation evaluation and error detection
- 음향특징의 예시로 GOP 가 있음 (가장 전통적으로 많이 사용되었음) - LSTM to extract feature representations for speech attributes and phone features
- LSTM 딥러닝이 활용되면서 LSTM 으로 특징추출 - CNN-based feature extraction and MLP-based classifier
- CNN 으로 음향 특징 뽑고, 그 다음 MLP 분류기로 분류하는 식 - wav2vec 2.0 with external alignment
- feature based 방법도 앞의 ASR 처럼 wav2vec 2.0 이용하되, 여기에 추가적으로 alignment
Feature-based MD 예시 )

- 안녕' 을 '아넝' 이라고 잘못 발음된 음성 + 잘못 발음된 정답 텍스트 'aa', 'nn', 'eo', 'ng' 를 입력으로 넣음
- alignment 진행 - 각각의 구간이 생김
- GOP 또는 wav2vec 을 사용해 구간 별 feature extraction 진행
- wav2vec ) context representations 과 해당 위치의 latent speech representations 의 차이, 즉 contrastive loss 를 최소화하는 방향으로 학습시켜서 음성의 mutual information 을 최대화 시킨다. 이렇게 학습된 wav2vec 2.0 을 활용하면 음성에서 좋은 representation vector 를 추출할 수 있다. (따라서 이걸 이용해 feature extraction 한다는 말) - 특징 추출을 하면 n 차원의 음향 특징 representations 이 나옴
- 그 특징을 바탕으로 각 구간별 어떤 phoneme 에 해당되는지 MLP based classifier 로 분류를 함
- 그리고 그 분류된 phoneme 과 실제 정답 phoneme 과의 차이로 3/4 (75%) 의 발음 오류 정확도를 얻음
* Limitations
- Commonly rely on extra phoneme alignment
- 음향 특징을 뽑는데 구간 설정이 매우 중요함
- alignment 결과로 분절된 phoneme 구간에서 추출한 음향 특징으로 분류기를 최적화 하기 때문에, alignment 결과에 의존적 ( ==> 따라서 본 논문에서는 alignment 성능도 함께 최적화 하는 방향으로 모델 학습 진행 )
- feature-based 는 phoneme 단위에서의 alignment 가 필수적으로 따라와야하고, 이와 관련된 문제들이 많음
- 이 방식으로는 MD 가 이렇게 강제정렬에 의존적이기 때문에, 강제정렬 정확도에 따라 성능이 달라짐 - Accuracy of alignment need to be optimized separately
- alignment 자체를 optimization 하는 것 따로 진행됨
* 결론
- ASR based : ASR, MD 별개의 문제로 따로 해결해야함
- feature based : alignment, MD 별개의 문제로 따로 해결해야함
- 모두 auxiliary task 와 최적화 방향이 다르다 라는 것이 문제
핵심 : joint alignment optimization
- feature-based 방법에 있어서 alignment 가 기본적으로 들어가는데, 기존 문제는 alignment, MD 태스크를 따로 봤다는 점
- 따라서 이걸 합쳐서 생각해보자는 것이 핵심!
- many works studied on phoneme alignment
- common method is based on HMM-based generative models
- HMM for each acoustic phone is trained
- sequence of frames is aligned to phone sequence by finding hidden state sequence that maximizes utterance likelihood
- 한계 : boundary accuracy not optimized due to absense of phoneme boundary representations - 합쳐서 생각하자는 'jointly optimized' 아이디어는 본 논문이 처음은 아님
- 이 아이디어로 가장 흔했던 방법은 HMM 기반 생성 모델을 만들어서 각 음성 프레임에 대해 대응하는 phone sequence 를 하나하나 배출해서 가장 해당 발화에 대해 확률이 높은 hidden state sequence 를 뽑아내는 방법
- 이 방법의 한계는 boundary accuracy 최적화 불가능(훈련할 수 있는 representations 이 없어서)
- 어느 시점에서 어느 시점까지 잘라야하는지에 대한 것 고려 X - 따라서 이를 해결하려는 것이 'discriminative method'
: treat phoneme alignment as a sequential labelling problem for phoneme classes and boundaries
- phoneme alignment 자체를 sequential labeling 문제로 접근
- sequential 하게 딱딱 labeling 이 되면서, sequence 내에 있는 각 frame 마다 phoneme 이 나오고 그 동시에 boundary 까지 생각하는 방식 - sequence labeling
- input sequence X = [ x1, x2, x3, ... , xn ] --> y = [ y1, y2, y3, ... , yn ] 이렇게 sequential 하게 쌍이 있다고 침
- 여기서 x 는 발화 내 각 프레임이고, y 는 phoneme class
- sequential labeling 문제로 삼았다는 것은 x 각 프레임마다 대응하는 phoneme class 를 부여하는 것을 의미함
ex) frame1, frame2, frame3 = 'a' ,'a', 'h'
== > 이처럼 본 논문에서는, phoneme boundary 최적화를 sequential labeling 문제로 삼아 mispronunciation detection 과의 MTL 방식을 택해서 해결하고자 함
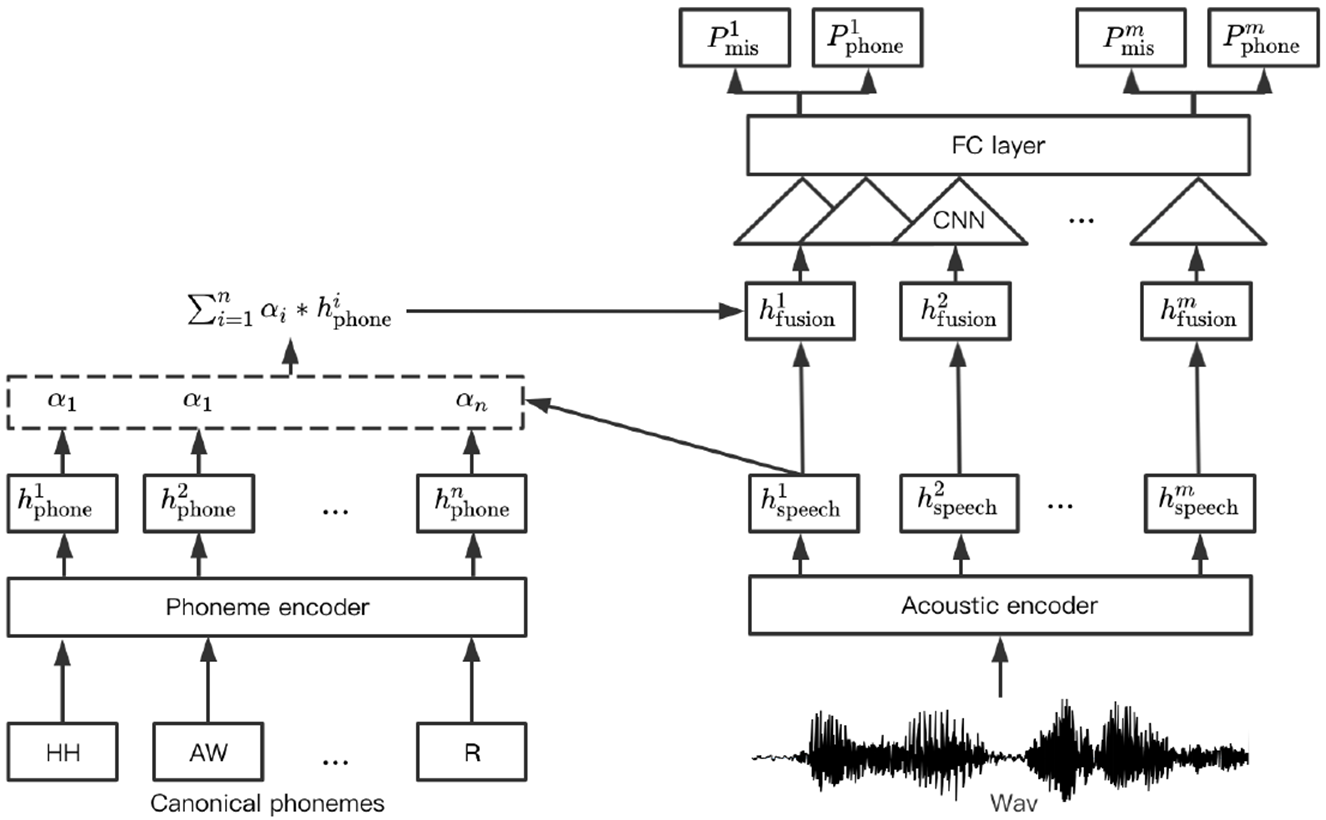
Proposal
- 따라서 본 논문에서는 phoneme 단위로 mispronunciation detection 을 하는 동시에 alignment 진행하는 것을 제안.
- 이 때 speech 와 canonical phoneme 각각을 acoustic, phoneme 인코더를 통해 acoustic, phoneme 임베딩으로 인코딩
- acoustic encoder 는 wav2vec 2.0 사용
- 이 두개의 representation 이 나오면 attention 메커니즘을 사용해 frame 기반으로 fusion
- attention 을 거쳐서 나온 합쳐진 phoneme, speech representation 을 CNN 에 보냄
- CNN 에서 phoneme representation 과 함께 로컬 context 로 acoustic feature 잡아내서 MLP 분류기에 보냄
- 이 때 phoneme mispronunciation 과 alignment 동시에 학습시켜야 하기 때문에, 각각의 비용 함수를 적용시키는 방법이 아니라 동시에 고려할 수 있는 multi task learning
- 결과적으로 본 논문의 실험을 통해 정렬 정확도에 따라서 발음 오류 정확도가 달라진다는 것을 확인할 수 있었음 - 더 연구할 예정
- propose a method for phoneme mispronunciation detection with joint optimization of alignment instead of separate ones
- speech and canonical phonemes are encoded into acoustic and phoneme embeddings based on acoustic and phoneme encoders, respectively
- Attention mechanism to fuse frame-based acoustic representations with phoneme embeddings
- CNN-based layer to explore local context of acoustic features with weighted phoneme representations
- phoneme mispronunciation and phoneme alignment optimized jointly with multi-task learning
- further explore relationship between alignment accuracy and phoneme mispronunciation detection accuracy
2. Proposed method
2.1. Feature representation learning
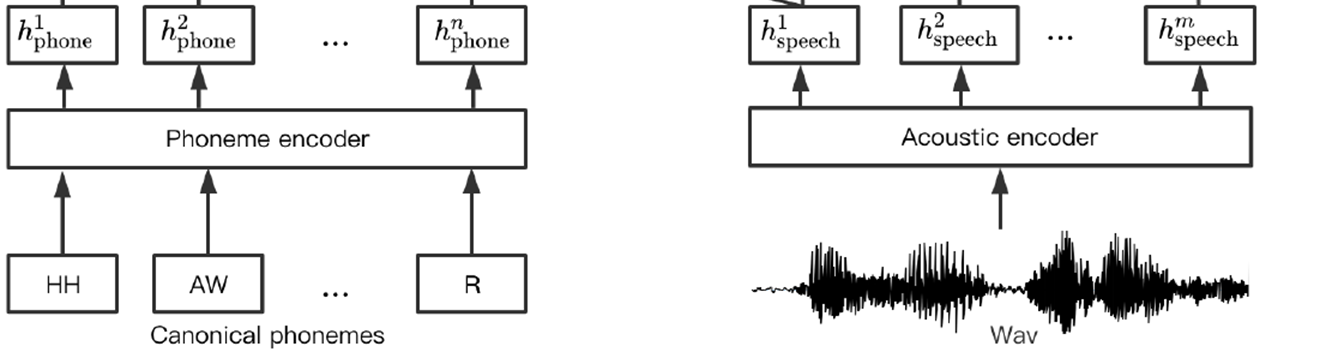
음향 특징 추출 : extracted from pre-trained wav2vec 2.0 acoustic encoder
- 음성을 pretrained 된 wav2vec 2.0 에 넣으면 음향 특징을 얻을 수 있음
- wav2vec 2.0 은 self-supervised learning
- 인풋을 따로 MFCC 나 feature 형식으로 넣는 것이 아니라 그냥 바로 오디오 시그널 넣음
- 여러 층의 convolutional layer 로 구성된 인코더에 넣어서 feature encoding
- contrastive loss 로 최적화
- 가장 큰 특징 : 굉장히 많은 unlabeled data 로 학습된 pre-trained 모델 사용
- 결국 wav2vec 2.0 의 음향인코더를 통과하면 h speech 라는 음향 특징 representation 이 나옴
- framework for self-supervised learning for representation from raw audio data
- multi-layer convolutional feature encoder
- optimized by contrastive loss based on large amounts of unlabeled data
phoneme embeddings
- mispronounced 된 canonical phonemes 을 넣어주면 phoneme encoder 를 통해 h phone 생성
- phone set 에 있는 각 phone type 들은 음향 특징 등등 각자 고유의 특징을 갖고 있음
- 그래서 각각의 phoneme 들을 글자 그대로 쓰지 않고 일련의 수치적 표현으로 나타냄
- 그 수치적 표현이 phoneme embedding 임
- each phone type in the phone set shows distinct characteristics
- different numerical representations for different phonemes
Attention mechanism
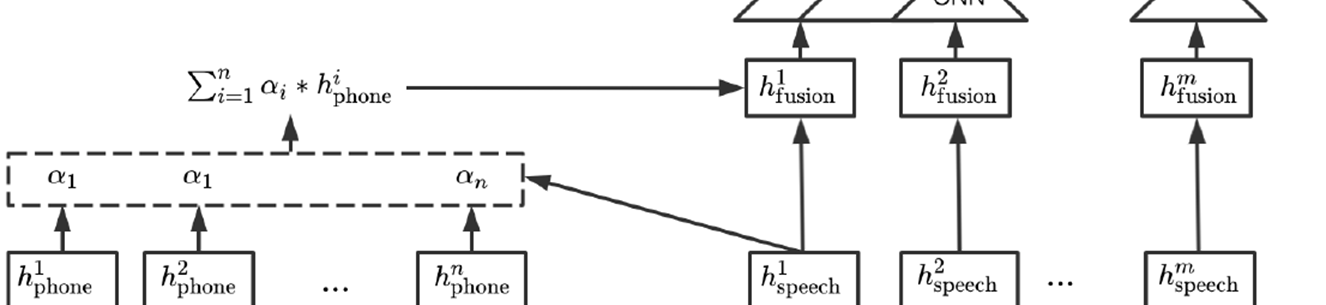
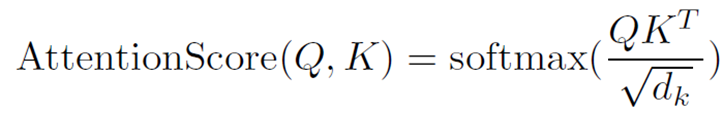
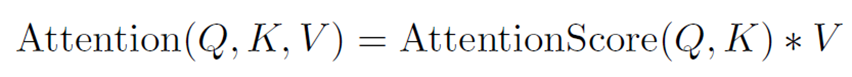
- 쿼리와 키 값이 들어가면 둘 사이의 관계를 attention score 로 뽑아내서 그 score 인 weight 값을 value 에 곱하는 형식 (dot product)
- 그래서 speech 와 phoneme 사이의 attention 은 정확히, value 에 대한 attention 값 구하는 것임
- speech representation 은 쿼리, phoneme representation 은 키와 value
- 결국 phoneme 이 주인공이고, speech 가 support 해주는 형식임
- 결과적으로 음성 특징과 관련이 큰 phoneme 에 좀 더 무게가 실리게 되는 것임
- h speech(쿼리) 와 h phone(키) 사이의 어텐션 스코어 = 가중치
- 그리고 그 ( 가중치 * h phone(value) ) + h speech (원본 음향특징) = h fusion (최종 fusion 값)
- 즉, h fusion 은 각 phoneme 에 대해서 음성 특징과 더 관련 있는 phoneme 이 weight 값 높을텐데, 그 가중치 값을 반영한 summed phoneme representations 과 원본 speech representation 을 단순히 나란히 붙여놓은 최종 값을 h fusion 이라고 함
- feature 준비 완료.
- multi-head attention (MHA)
- Queries(Q), Keys(K), Values(V)
- speech representations : Q, Phoneme representations : K, V
- result : weighted sum of representations of relevant phonemes
- fused representation : concatenate acoustic and summed phoneme representations
2.2. Training and inference of phoneme mispronunciation
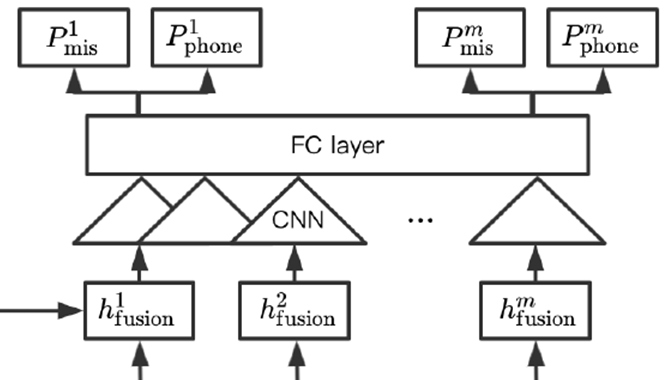
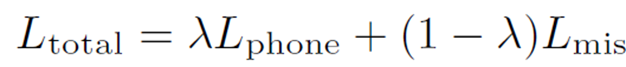
- feature 준비완료 된 것을 바로 FC layer 로 넘기지 않고 CNN 거침
- 아까 앞에서 feature 준비할 때, RNN 을 사용하지는 않았지만 인풋이 순서대로 들어가긴 했음
- 그래서 아까 인코딩하는 과정에서 sequential 요소를 global 하게 잡았다고 치면, 이 CNN 레이어를 통과하면서는 local 하게 국지적인 중요한 부분에 포커스 맞춰서 정보를 얻음
- 이 전에 feature 준비하는 multi-head attention 과정은 global 문맥 정보 얻는 과정. 지금 CNN 은 local 문맥 정보 얻는 과정
- CNN 통과 후 드디어 두개의 FC 레이어 통과 - 하나는 발음오류 레이어, 하나는 phoneme 분류 (alignment) 레이어
- phoneme 분류 레이어 통과하면 predicted 된 phoneme sequence 가 나옴
- 각각의 층에서 mispronunciation, phoneme alignment 쌍을 뽑아냄
- 그리고 이 둘 사이의 값을 cross-entropy loss 사용해서 학습
CNN-based layer
- fused frame representations contain weighted sum of phoneme representations of global context through MHA
- explore local context around one frame
Two separate FC layers
- each for mispronunciation and phoneme classification, respectively
- phoneme alignment : sequential labelling of phoneme clases
Cross-entropy classification loss
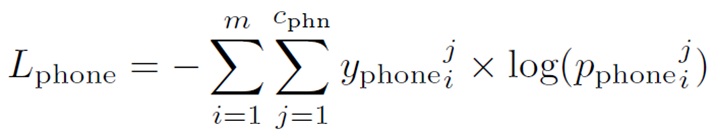
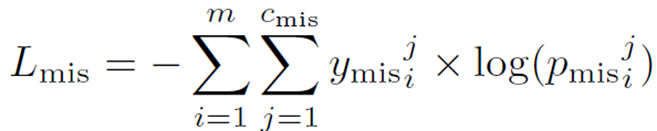
Multi-task learning (MTL)
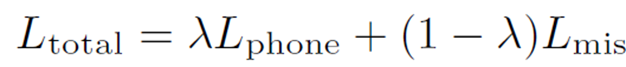
- mispronunciation, phoneme alignment 의 두 개의 cross-entropy 값의 balance 를 맞춰주는 MTL
- 람다 값을 통해 어느 쪽에 더 무게를 줄지 조정
- 최종 L total 을 구하면, 이제 이 L total 를 통해 back propagation 등등 진행하며 모델 학습
- total loss defined with a hyper-parameter to balance between two losses
Inference
- frame 단위에서 phoneme alignment, mispronunciation prediction 별로 probability sequence 가 각 sequence 마다 딱딱 나올 것임.
- a / a / h 이런식으로 똑같은 phoneme 이 연달아 나왔을 때는 이걸 묶어서 평균화함
- 따라서 똑같은 phoneme 에 대해서는 같은 mispronunciation probabilty 나오도록 계산
- 결과적으로 phoneme 연쇄에 있어서는 똑같은 mispronunciation probability 나옴 - 정답 값인 canonical sequence 와 추측된 phoneme sequence 합쳐서 alignment 진행함
- 이렇게 predicted 된 sequence 와 canonical sequence 와 비교해서 다르면 (mismatch면) - mispronouced
- 또 predicted 랑 canonical 이랑 맞긴 맞아도 특정 threshold 보다 발음 오류 확률이 높으면 - mispronounced
- probability sequences of phoneme and mispronunciation predictions at frame-level
- mispronunciation probabilities averaged for adjacent frames in case of the same predicted phoneme
- a series of identical phonemes with the same average mispronunciation probability - align predicted phoneme sequence with canonical sequence
- mismatched canonical phonemes - mispronounced
- average mispronunciation probability higher than threshold - mispronounced
3. Experiments
3.1. Experimental setup
Acoustic representations
- 음향 특징은 처음에 384 dimension --> 나중에 phoneme embedding 과 attention 위해 32 dimension 으로 축소
- initially 384 dimensions - transformed to 32 dims to match phoneme embeddings
Phoneme embeddings
- 총 phoneme 은 40개 클래스이고, 각 32차원임
- 40 phonemes (1 silence + 39 different phonemes)
- encoded into an embedding of 32 dims
Alignment
- multi-head 어텐션으로 정렬 (사실 one-head 사용) - 음향 특징과 canonical phoneme sequence 묶음
- frame-level acoustic representations aligned to canonical phoneme sequences based on one-head MHA
CNN layer
- input channel : 64 // 아까 음향 특징 32, phoneme embedding 32 --> 32 + 32 = 64
- output channel : 64 // output 도 64
- kernel size : 9 // 그냥 9 로 정함
Two FC layers
- each for mispronunciation and phoneme classification, respectively
- 64 * 2 dims ==> input 으로는 64차원이 들어오고 output 으로는 2개의 FC 이기 때문에 2차원이 나옴
MTL loss balance parameter
- λ = 0.5
TIMIT corpus for phoneme classification pre-training
- for better initialization (랜덤으로 하는것보다 미리 pretrained 된 값이 더 나아서 TIMIT 에서 얻은 값으로 초기화)
- native English corpus of 6,300 utterances (10 sentences by 630 speakers)
- Includes time-aligned orthographic, phonetic, and word transcriptions for each utterance
L2-ARCTIC corpus <본격적인 데이터셋>
- 일반적으로 MD 를 위한 코퍼스 - non-native speaker 로 이루어짐.
- used for joint optimization and evaluation of mispronunciation detection
- non-native English corpus for mispronunciation detection
- includes different types of mispronunciation errors
- substitutions, deletions, and additions (insertions) - map 61-phone setting of TIMIT to 39-phone setting of L2-ARCTIC
- pretrained 한 TIMIT 은 61 개로 셋팅되어있어서 실제 데이터셋인 L2-ARCTIC 39 개에 맞춤
- 이 39 개에 맞추기 위해 아까 phoneme embedding 도 39 + 1 (silence) 였음
Evaluation metrics
- precision (PR), recall (RE), F1-score
- TA / TR : phonemes with correct/incorrect pronunciation that are correctly classified
- 맞는 발음, 틀린 발음 모두 정확하게 prediction 되는 확률 - FA / FR : wrong classification results
- 이 TA/TR/FA/FR 이용해 PR, RE, F1 구함
3.2. Comparative study
Performance comparison
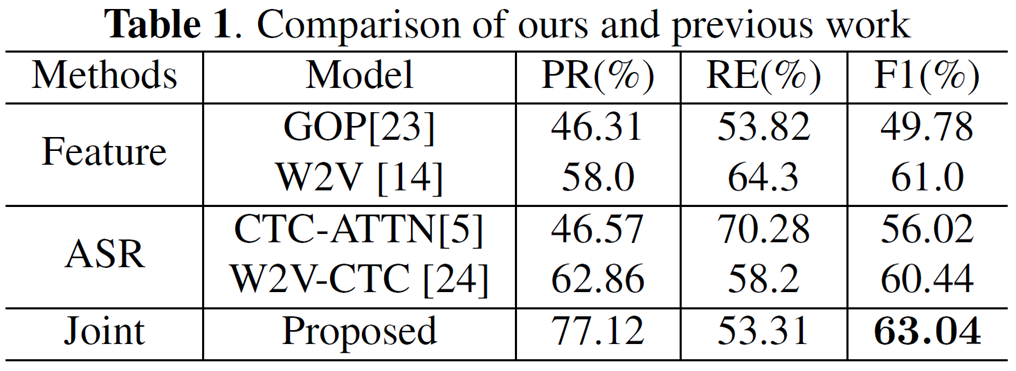
- 본 논문에서 제안하는 joint 방식은
- feature-based 에 비해 2퍼센트 성능 개선
- ASR-based 에 비해 3퍼센트 성능 개선 - SOTA 성능 갱신
- phoneme alignment 와 mispronunciation detection 을 같이 생각하면 더 좋은 결과가 나올 수 있다는 것을 말함
* 그런데 사실 F1 으로 비교하면 가장 좋지만, recall 값이 낮긴함..
아무리 F1 이 높아도 recall (a 로 예측한 게 진짜로 a 인 확률) 이 낮으면 믿을 수가 없음
(이런 현상은 주로 특정 class 가 다른 나머지 class 에 비해 압도적으로 데이터 양이 많아서 weight 값이 쏠려서 한 쪽으로 치우쳐졌을 때 발생할 수도 있음)
3.3. Ablation studies
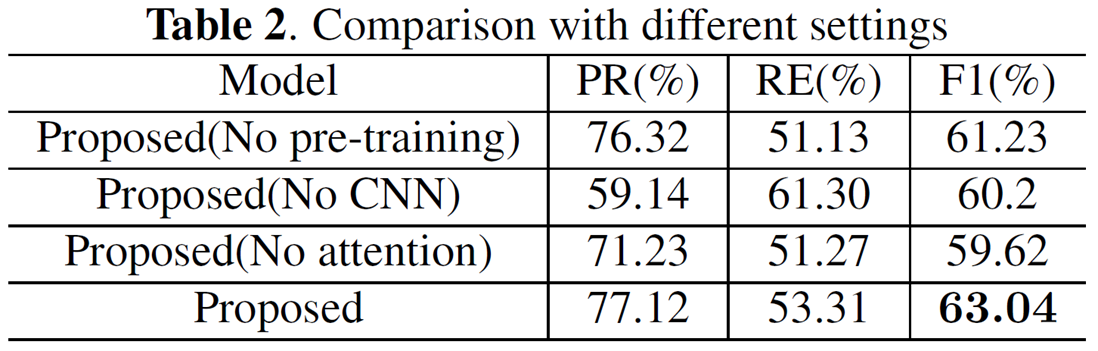
- 모델에 들어가있는 각각의 요소들을 하나씩 빼보면서 어떤 것이 가장 영향력이 있었는지 평가
- TIMIT 코퍼스의 pre-training 을 뺐을 때
- CNN 뺐을 때 recall 값 (53 --> 61) 많이 상승
- attention 뺐을 때 - canonical phone 을 학습 안한다는 것이니 영향력이 큼 = 따라서 가장 낮게 나옴
- attention 이 가장 중요하다!
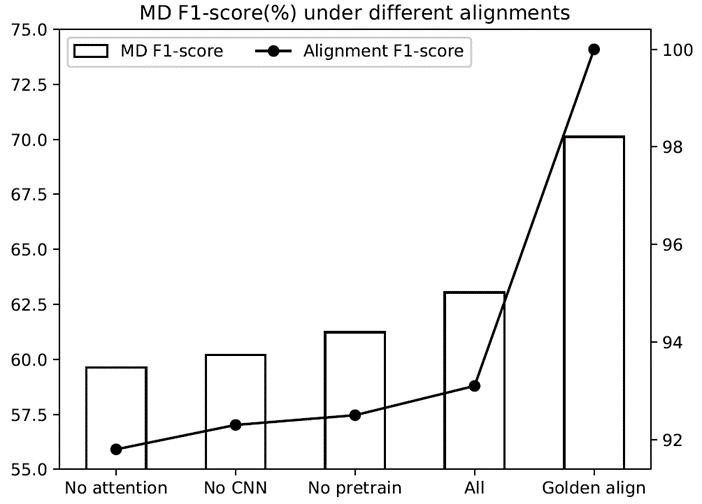
3.4. Relationship between phoneme alignment and mispronunciation detection
Effectiveness of joint optimization
- 추가적으로 alignment 성능에 따라서 MD task 성능이 어떻게 달라지나 살펴보기
- alignment F1 score 에 따라서 MD F1 score 달라지는 것 살펴보기
- human-labelled alignments 를 golden alignment 로 보고 100으로 함
==> 결론 : alignment 성능이 좋을수록 MD 성능도 좋아짐 <그만큼 alignment 중요하다>
4. Conclusion
Summary
- proposed a method for phoneme mispronunciation detection by jointly learning to align
- attention mechanism implemented for fusing acoustic and phoneme representations
- feature representations derived from pre-trained encoders - experiments on L2-ARCTIC and achieved SOTA performance of 63.04% F1-score
- relationship between MD performance and alignment accuracy
- importance of good alignment and advantage of joint optimization
Future plan
- investigate other factors that influence mispronunciation detection performance
Reference
- 서울대 음성언어처리연습 논문리뷰 이주영님 발표 Phoneme mispronunciation detection by jointly learning to align - Binghuai Lin, Liyuan Wang @ ICASSP 2022
- Phoneme mispronunciation detection by jointly learning to align - Binghuai Lin, Liyuan Wang @ ICASSP 2022