Deep Learning
트랜스포머(Transformer) (4) - 인코더와 디코더
햇농nongnong
2022. 6. 4. 15:33
인코더 (Encoder)

- 트랜스포머는 하나의 인코더 층이 총 두개의 서브 층으로 이루어짐 : 셀프어텐션, 피드포워드 신경망
1) 셀프어텐션 : multi-head self-attention 블록으로 셀프 어텐션을 병렬적으로 사용함
2) 피드포워드 신경망 : position-wise FFNN 블록으로 그냥 일반적인 피드 포워드 신경망임

- self-attention : 인코더 파트에서 수행하는 어텐션
- 각각의 단어가 서로 어떤 연관성을 가지고 있는지 구하기 위해 사용 - ex) I am a teacher : 문장을 구성하는 각각의 단어 I, am, a, teacher 에 대해서 각각의 단어끼리 attention score 을 구해서 서로 어떤 단어와 높은 연관성을 갖는지에 대한 정보를 학습시킴
- 어텐션을 통해 전반적인 입력 문장에 대한 문맥 정보를 잘 학습하도록 만듦

- 성능 향상을 위해 잔여 학습(residual learning) 사용
- Residual Learning : 대표적인 이미지 분류 네트워크인 Resnet 과 같은 네트워크에서 사용되고 있는 기법
- 어떤 값을 레이어를 거쳐 반복적으로 단순하게 갱신하는 것이 아니라, 특정 레이어를 건너뛰어서 복사된 값을 그대로 넣어주는 기법
- 특정 레이어를 건너뛰어서 입력할 수 있도록 만들어주는 것이 residual connection - 이 residual learning 을 통해 전체 네트워크는 기존 정보를 입력받으면서도 추가적으로 잔여된 부분만 학습하기 때문에 학습 난이도가 전반적으로 낮으면서도 초기 모델 수렴 속도가 높음
- 따라서 더욱 더 global optimal 을 찾을 확률이 높아짐
- 이 이유로 다양한 네트워크에 residual learning 을 사용하면 성능이 높아지는데, 트랜스포머도 이 아이디어를 채택해서 성능을 높임
- 즉, 인코더에서는 어텐션을 수행해주고 나온 값과 residual connection 을 이용해 바로 더해진 값을 함께 받아 더하고, normalization 수행 - 그리고 결과 내보내기

- 그리고 인코더에서는 여러 개의 레이어를 중첩해서 위의 기능을 반복적으로 구현
- 하나의 레이어 안에서는, 위에 설명했던 것처럼 입력 값이 들어오고 - 어텐션 거치고 - residual connection - normaliation - 다시 feed forward layer - residual learning - normalization
- 어텐션과 정규화 과정 반복하는 방식으로 여러 개의 레이어를 중첩해서 사용
- 이렇게 중첩할 수 있다는 것 = 입력 값과 출력 값의 dimension 은 동일
- 각각의 레이어는 서로 다른 파라미터 값을 가진다. (같은 모델이지만 다른 파라미터 값)
- Layer 1 과 Layer 2의 attention 레이어의 파라미터 값 서로 다름. (feed forward layer 파라미터 값도)
3. 인코더와 디코더 (Encoder, Decoder)

- 첫번째 인코더 레이어에 입력 값이 들어오고 여러 개의 인코더 레이어 반복해서 거침
- 가장 마지막 인코더 레이어에서 나온 출력 값이 디코더에 들어감
- Seq2seq 에서 attention 메커니즘 이용했던 것과 마찬가지로, 트랜스포머 디코더도 매번 출력할 때마다 입력 소스 문장 중에서 어떤 단어에 가장 많은 초점을 맞춰야 하는지 알기 위해 어텐션 사용
- 디코더도 여러 레이어로 구성되고, 가장 마지막 레이어의 출력 값이 최종 번역 수행 결과 출력 단어가 됨
- 디코더의 각각의 레이어는 인코더의 마지막 레이어에서 나온 출력 값을 인풋으로 받음
- 사실 인코더의 마지막 레이어 출력 값 뿐만 아니라 인코더 각 레이어의 출력 값도 같이 받는 방법도 존재하긴 함
- 하지만 기본적인 트랜스포머 아키텍쳐는 인코더의 마지막 레이어의 출력 값을 매번 디코더의 인풋으로 넣어주는 방식
- 디코더도 단어 정보를 받은 후 각 단어의 상대적인 위치 정보를 알려주기 위해 positional encoding 값 추가 한 후 디코딩 진행
하나의 디코더 레이어에는 두 개의 어텐션 작동
1) self-attention : 인코더와 마찬가지로 각 단어들이 서로에게 어떻게 영향을 주는지 가중치를 구하도록 함
2) encoder-decoder attention
- 인코더에 대한 정보를 어텐션
- 각각의 출력되고 있는 단어가 인코더의 출력 정보를 받아서 그 정보를 이용해 출력될 수 있도록
- 즉, 각각 출력되고 있는 단어가 소스 문장에서의 어떤 단어와 연관성이 있는지 구하는 것임
- 그래서 이 어텐션을 '인코더 디코더 어텐션' 이라고 부름
Encoder Decoder Attention 동작원리
- 입력 문장이 "I am a teacher" 이라면, 출력 문장은 "나는 선생님이다" 라고 차례대로 내뱉어야 함
- 이 때 이 단어들 중 '선생님' 이라고 번역했다면, '선생님' 은 'I', 'am', 'a', 'teacher' 중 어떤 단어와 가장 연관성이 높은지 계산하는 것
- 이 디코딩 된 단어와 입력 단어와의 정보를 매번 어텐션을 통해서 계산
- 따라서 인코더 파트에서 나왔던 출력 결과를 디코더에서 전적으로 활용하도록 네트워크를 설계할 수 있는 것
- 디코더도 인코더와 마찬가지로 입력 dimension 과 출력 dimension 이 같도록 해서 디코더 레이어를 여러번 중첩해서 사용
트랜스포머에서는 마지막 인코더 레이어의 출력이 모든 디코더 레이어에 입력된다.
ex) n_layers = 4 일 때의 예시
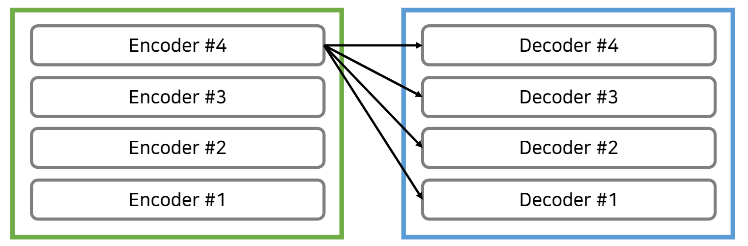
- 일반적으로 레이어의 개수는 인코더와 디코더가 동일하도록 맞춰주는 경우가 많음
- 이 예시에서도 인코더, 디코더 모두 4개의 레이어로 구성
- 인코더 파트의 마지막 레이어(4번째)의 출력 값이 각각의 디코더 레이어의 입력 값으로 들어감
- 인코더의 출력 값이 디코더로 입력된다는 의미 : 디코더의 두번째 어텐션 (인코더-디코더 어텐션) 에서 각각의 디코딩된 출력 단어가 입력 단어 중 어떤 단어와 가장 높은 연관성이 있는지 만들어준다는 의미
정리하자면, 트랜스포머도 "인코더-디코더" 구조를 따른다.
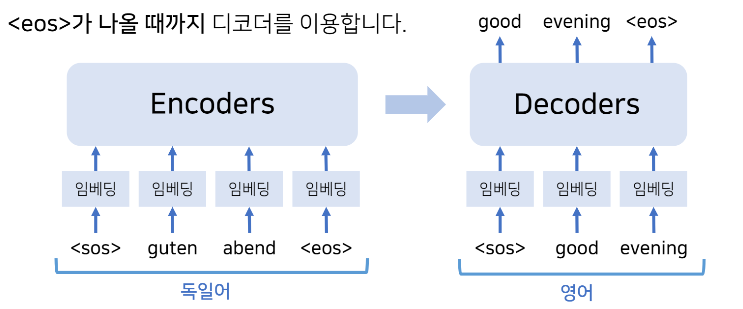
- 트랜스포머도 인코더-디코더 구조를 따르지만, "RNN" 사용하지 않고, 인코더와 디코더를 중첩해서 "다수" 사용한다는 점이 특징
- 인코딩할 때 원래 RNN/LSTM 에서는, RNN/LSTM 을 고정된 크기로 사용하고, 입력 단어가 들어오면 단어마다 다 따로 입력 단어의 개수만큼 인코더 레이어를 반복적으로 거쳐서 매번 hidden state 를 만들었음
- 트랜스포머에서는 입력 단어 자체가 하나로 쭉 연결되어서 한번에 입력이 되고, 한번에 그에 대한 어텐션 값을 구함
- RNN 과는 다르게, 위치에 대한 정보를 한꺼번에 넣어주는 것임
RNN과 비교했을 때 트랜스포머의 장점
- 한번 인코더를 거칠 때마다 병렬적으로 출력 값을 구할 수 있기 때문에 RNN 과 비교해볼 때 계산 복잡도가 더 낮음
- 또 입력 값을 전체 한꺼번에 넣을 수 있기 때문에 RNN 을 사용하지 않고도 학습을 진행할 수 있다는 점이 장점
- 다만, 실제 모델에서 출력 값을 내보낼 때는 디코더 아키텍쳐를 <eos> 가 나올 때까지 여러번 반복 수행하여 출력 값 구함
- 트랜스포머는 인코더와 디코더 중간에 context vector 로 압축하는 과정이 완전히 생략되어 있음
- 따라서 네트워크에서 LSTM 과 같은 RNN 구조 아예 사용할 필요가 없다는 점이 장점
Reference
이 글은 나동빈님의 'Transformer : Attention Is All You Need' 논문 리뷰 영상을 보고 정리한 글입니다.