Spoken Language Processing
딥러닝으로 음향모델 모델링 (End-to-end algorithm)
햇농nongnong
2022. 6. 3. 16:43
이 글은 ETRI 박전규 박사님의 언어교육 성과 특강 강의를 듣고 정리한 글입니다.
딥러닝을 통한 음향모델의 모델링 (end-to-end)
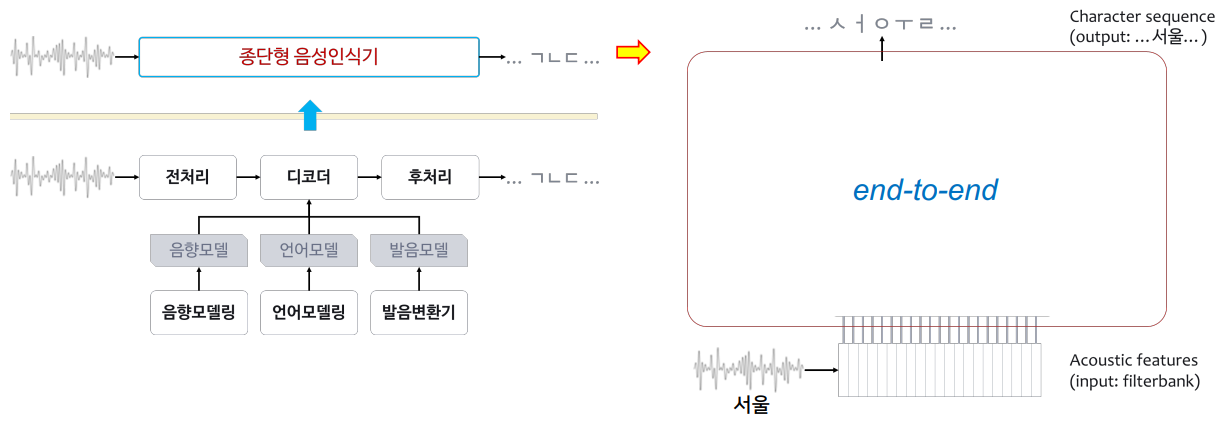
- 왼쪽 그림이 전통적인 음성인식 모델 : 음향, 언어, 발음 모델 다 별도로 모델링.
- 이전에는 음성인식 디코딩을 위해 음향모델링, 언어모델링, 발음변환기 다 따로 전문가가 만들어야했음.
- 음성인식기 하나 만드려고 하면 대략 10명 정도가 개발. (음향 전문가 2, 언어전문가 2, 발음전문가 2, 후처리 등등..)
- E2E 는 한사람이 개발 가능 - 음성 파형 & 음성 파형이 무엇을 나타내느냐(전사정보)
- 위 두 가지 정보만 넣어주면 모델 완성.
- E2E 모델 : acoustic 모델, language 모델 implicit 하게 다 가지고 있다고 보면 됨. (E2E 가 강력한 이유)
- end-to-end 알고리즘이 나오게 되면서 음성인식이 굉장히 쉬워짐 : acoustic 모델이 간편하고 정교하게 바뀜
하지만, 사실 end-to-end 의 내부를 보면 굉장히 복잡함
- 이전보다 parameter 수가 10배 정도 됨
- 감정인식은 파라미터 1000만개
- ETRI end-to-end 음성인식기의 경우 3000만개 (아래그림 음성인식기)
- DNN 이라는게 행렬연산 - 행렬연산 포함한 모든 파라미터 수가 3000만개 정도.

Acoustic modeling : a pretrained model "wav2vec"
- 음성인식에도 사전학습 모델이 있음
- 언어모델은 "GPT-3" 라는 사전학습 모델 존재
- 음향모델에도 "wav2vec" 존재
- facebook 에서 고맙게도 본인 돈 들여 열심히 학습시켜 만들어준 모델
- Pre-trained model-based transfer learning
- AM for very low-resource language
- Pre-trained model : LV-60k vs. XLSR-53-56k
- LV-60k (wav2vec 버전 1) : LibriVox audiobooks, English, 60k hours - 영어에 대해서 6만 시간 학습시켜 오픈.
- XLSR-53-56k (wav2vec 버전 2) : 53-language self-supervised speech transformer, 56k hours
- 56000시간의 53개 언어 학습시켜 오픈.
- Fine-tuning split (Korean L2, Hour) : 700, 100, 10, 1
- 100시간 내외에서 saturate
- 위의 pretrained 모델은 페이스북이 6만 시간 들여서 만들었다면, 우리는 그 모델을 가져와서 fine-tuning 을 통해서 1000시간만 쓰더라도 좋은 음성인식기 만들 수 있음.
- ex) 비원어민의 한국어 1000시간 데이터를 가지고 700시간, 100시간, 10시간, 1시간 fine-tuning 했을 때 비교

- 1시간만 학습시켜도 오류율이 16% : 정말 어마어마한 성능
- 10시간 --> 13%로 dramatic 한 향상
- 사전학습모델의 강력함을 잘 보여줌
- 100시간 정도 훈련하면 수렴.


- 왼쪽일수록 데이터 양 많고, 오른쪽일수록 데이터가 없음.
- 왼쪽은 전통적인 모델 사용해도 충분히 좋은 음성인식기 만들 수 있지만, 오른쪽의 국가들은 100시간 이하의 데이터가지고는 전통적인 음성인식기 방법론으로는 만들 수 없음.
- 하지만 wav2vec의 사전학습모델을 사용했을 때 오른쪽과 같이 데이터 양에 따른 성능 차이 크게 없음. 적은 데이터 양도 잘 만들어진 것을 볼 수 있음.
- 오른쪽과 같이 에트리에서는 wav2vec 사용하여 24개의 다국어 음성인식기를 보유하고 있음.
- 원래는 12개 언어만 음성인식기 있었는데, wav2vec 사용한 후 12개 추가.
Reference
- 2022.06.02 ETRI 언어교육 성과 특강 (ETRI 박전규 박사님)