Biosignal Processing for Human-Machine Interaction (Tanja Schultz) - Interspeech 2019 Keynote Talks
이 글은 Interspeech 2019 Keynote Talks 의 Biosignal Processing for Human-Machine Interaction (Tanja Schultz) 강연을 듣고 정리한 노트이다.
이 강연에서는 여러 바이오 시그널들을 활용하여 음성을 합성할 수 있는 다양한 방안을 제시하 고, 특히 muscle activities, brain activities를 통한 음성 합성 연구에 대해 설명하였다.

Acoustic signal 을 뛰어 넘어 여러 생체 시그널들을 이용하여 연구를 진행하면 acoustics signal 처리를 통 해서는 얻을 수 없었던 다양한 benefits 들이 존재하고, 그러한 연구들을 위해서는 다양한 lab 간 의 교류를 통해 다채로운 연구가 필요하다고 설명하였다.
살아있는 생명체로부터 생성되는 물리적으로 측정 가능한 자동적인 신호가 biosignal인데, 이러 한 biosignal들을 이용하여 spoken communication이 가능하다. 음성이 생성되기 위해서 인간의 몸에서는 아주 복잡한 과정이 이루어지는데, 뇌에서 시작되어 호흡, 후두, 그리고 음향 신호를 만 들어내는 관절 동작을 이끄는 근육 활동으로 이어진다. 따라서 음성 활동은 중추신경계, 말초신경 계, 근육활동전위, 언어 운동학 등의 다양한 분야에서 측정될 수 있고, 각종 센서 기술로 측정하 여 음성 관련 생체 신호들을 얻을 수 있는 것이다. 이 신호들을 통해서 feature를 추출하고 처리 하여 output을 생성할 수 있다. 음향 신호 외의 다른 생체 신호를 통해 음성을 획득하면 현재의 한계를 극복할 수 있는 여러 장점들이 있다. 음향 신호가 공기로 운반되기 전에 음성을 캡처할 수 있고, 근육이나 뇌 활동을 통해 얻는 신호는 음향 출력보다 더 우선한다는 점을 활용할 수 있으며, 속삭이거나 심지어 소리 가 나지 않을 때까지의 음성까지 캡처할 수 있다.
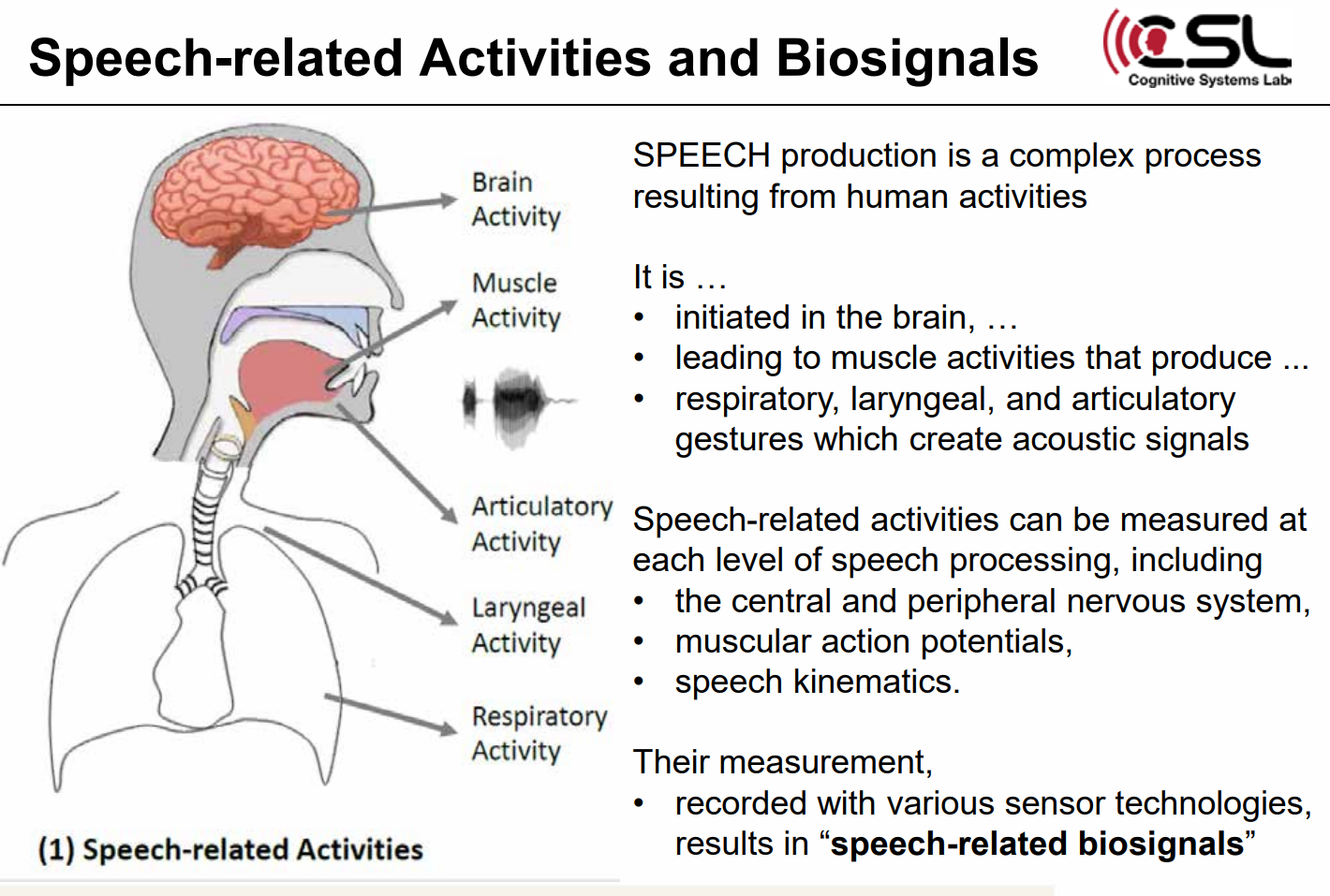
이러한 생체신호를 이용한 spoken communication 의 4가지 use cases 를 살펴보면,
1) 먼저 강력한 음성 통신이 가능하다. 불리한 노 이즈 조건에서도 성능을 향상시킬 수 있고, 상호 보완적인 생체신호를 융합할 수 있다.
2) 두번째로, 조용한 장소에서 조용히 말함으로써 disturbance를 피할 수 있어 도청방지에도 응용할 수 있다.
3) 세번째로, 말을 하지 못하는 사람들에 있어서 인공 기관을 만들어 restore spoken communication 에 도움을 줄 수 있다.
4) 네번째로, 음성 생산에 대해 발성 biofeedback을 제공하여 치료와 훈련을 위해서도 응용할 수 있다. ASR의 고전적인 3단계는 음성 신호를 캡처하고, 신호를 전 처리하고, automatic speech recognition 을 통해 text 결과를 얻는 것이다.
음향 신호 대신 근육 활동을 사용해서도 똑같은 과정이 적용된다.
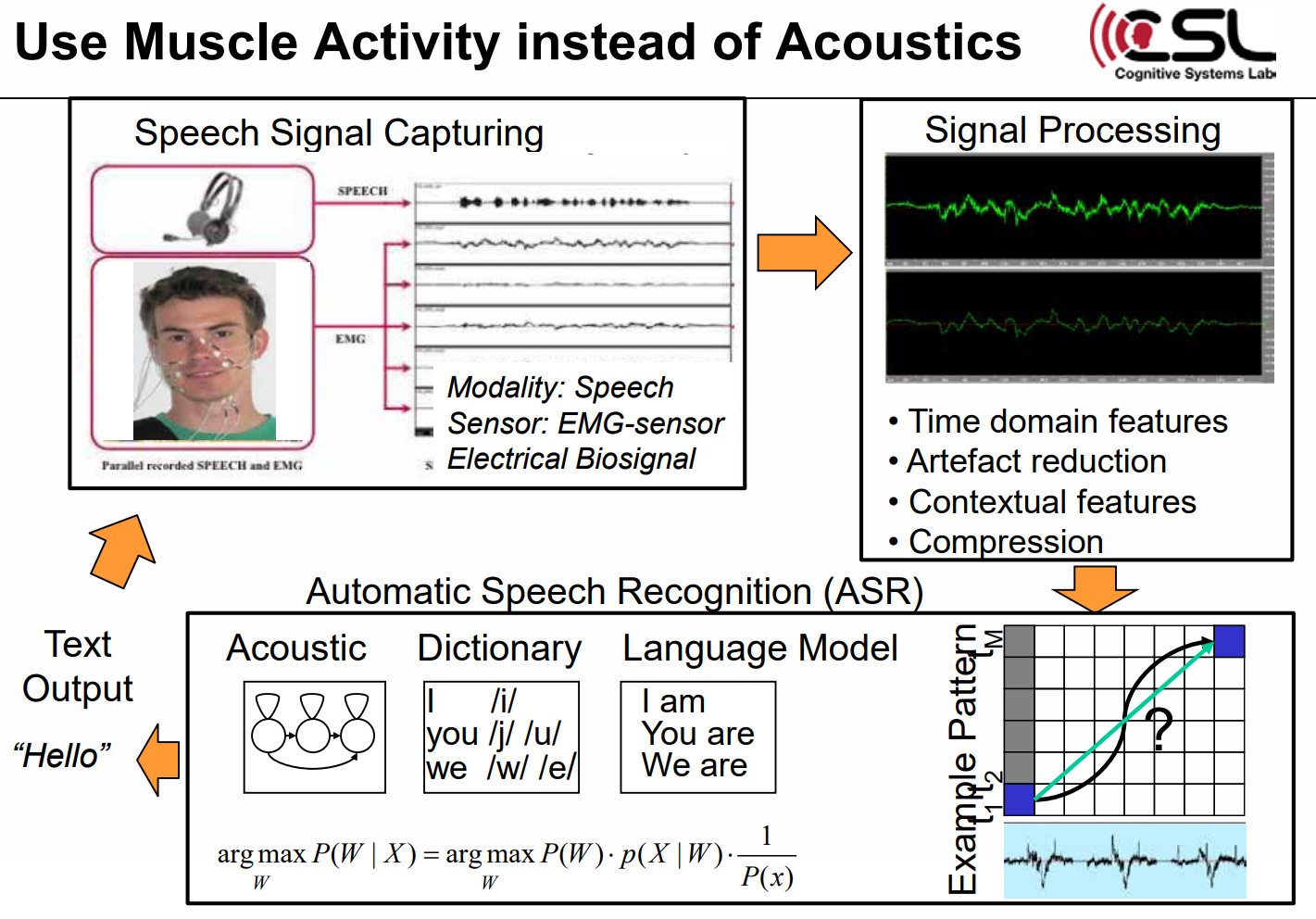
단지 센서만 microphone에서 EMG 센서로 변화하고, acoustic biosignal에서 electrical biosignal로 바뀌는 것이다.

Muscle activity를 통한 신호가 감지되면, time domain features, artifact reduction, contextual features, compression 등의 신호 처리 과정을 거치고, ASR을 통해 text output을 얻을 수 있다. 근육 활동을 통해 신호를 처리하면, EMG(ElectroMyoGraphy), 즉 피부 분절 전기 자극이 음향이 아닌 motion을 기록하기 때문에 silent speech도 처리가 가능하다. 또한, 근육 활동을 통한 신호 처리는 disturbance없이 조용한 환경에서 조용히 말하면서 측정 가능하고, 기밀 정보를 전송할 수 있어 개인 정보 보호가 가능하고, 소음 환경에서 손상이 없기 때문에 소음 강건성이 있고, 언어 장애인을 지원할 수 있기 때문에 언어 증강의 장점이 있다.
또한, adversarial training을 독립적인 EMG 기반 ASR에 적용하면 서로 다른 세션의 데이터를 더욱 복잡 하게 만들 수 있기 때문에 목표 분류 정확도도 향상시킬 수 있다. 하지만, 이 신호처리에서는 청각 피드백이 부족하다는 난제가 있다. Audible speech를 통해 얻는 신호와 EMG 신호는 다르고, 숙련된 스피커들에게는 잘 들릴 때나 속삭일 때나 무음일 때의 EMG 전력 스펙트럼 밀도가 현저하게 작은 변화만 있다는 어려움이 있다. 따라서 이를 보완하기 위해 spectral mapping algorithm을 사용하고, 즉각적인 청각 피드백을 제공하기 위해 “direct synthesis” 방법을 사용한다. ASR의 output인 text를 사용한 EMG-to-Text, feature transform과 vocoding(E MG-2-MFCC)의 output을 사용한 EMG-to-Speech의 두 가지 방법이 있다. 또한, 근육 활동뿐 아니라, 뇌 활동을 통해서도 biosignal를 얻어 음성을 얻을 수 있다.
Acoustic speech recognition은 전통적인 speech to text를 통해서 가능했고, silent speech recognition은 EMG를 통해 가능했다면, Imagined speech recognition은 뇌를 통해 가능하다. ElectroCorticoGraphy(EcoG)는 EEG처럼 뇌의 전기적 활동을 잡아내고, 높은 temporal resolution을 가진다. 또한, EcoG는 EEG와는 다르게 뇌 표면에 직접 기록함으로써 높은 spatial resolution도 잡 아낼 수 있다. Brain-to-text에는 피험자가 말하는 동안 감마 활동을 하고, 이를 통해 likelihoods 를 예측하고, 이 likelihoods와 언어 정보를 결합하여 단어를 디코딩하고 결국 spoken sentences를 디코딩 할 수 있다. Brain-to-speech에서는 음성 생성과 관련된 두개골 내 뇌 활동에서 직접 음성 을 합성할 수 있는데, 먼저 데이터를 기록하고 테스트 데이터와 훈련 데이터 window를 각각 비교하여 코사인 유사성이 최대인 윈도우를 선택하여 해당되는 오디오 구간을 선택해 이를 결합하 여 재구성된 오디오 출력을 만드는 것이다.
이 강연을 듣고, 소리를 내어 얻을 수 있는 음향 신호 외의 다양한 바이오 시그널들을 활용하 면 음성 합성에 있어서의 많은 한계점을 보완할 수 있을 것이라고 생각하였다. 또한, airborne 전 의 음성을 캡처함에 있어서 언어 장애인들에게 도움을 줄 수 있는 연구를 할 수 있을 것 같다. 당연히 audible signal를 통해서만 음성 처리가 가능하다고 생각했었는데, 다양한 biosignal을 통해 음성을 합성할 수 있는 연구들을 보니 더 많은 바이오 정보들의 응용에 대해 연구하고 싶고, 다 양한 생체 신호들을 테스트해보아 좋은 성능을 보이는 신호를 찾아 더 깊이 연구해보고 싶다. 또 한, 이 강연을 들으면서 인지과학의 중요성을 다시 한 번 알 수 있었다. 신경과학, 언어, 인공지능, 심리학 등의 학제적인 연구를 통해서 음향신호 이외의 신호를 가지고 음성을 결합할 수 있는 단 계가 온 것을 보고, 더더욱 여러 연구들을 융합하고 서로 연결해야 하는 필요성을 알 수 있었다. 휴먼기계바이오공학을 전공하면서 여러 기계적 요소들, 세포공학 등의 바이오 요소들, 인공지능을 배웠는데, 다양한 분야를 더 깊이 공부하면서 서로 연결시켜 여러 biosignal에 대한 연구를 해보고 싶다.