wav2vec 2.0 기초개념 정리

self-supervised learning (자기지도학습)
- 라벨이 없는 데이터를 이용하여 자기 자신의 특성(representation)을 배우는 학습 방법
- 라벨링된 데이터가 부족한 분야에서는 딥러닝이 큰 성능 보이지 못하고 있는데, self-supervised learning을 적용한 pre-trained 모델이 있다면 fine tuning 을 이용해 데이터가 적은 분야에서도 성능향상을 가져올 수 있음.
- 전통적인 음성인식 모델들은 전사된 annotated speech audio 에 의해 주로 훈련됨 - 좋은 시스템은 많은 양의 annotated 데이터를 필요로하는데, 이 것은 몇몇 언어에서만 가능함 - 자기지도학습이 unannotated data 을 활용하여 좋은 시스템 만드는 방법을 제공함
wav2vec 2.0
2020년에 Facebook 에서 Wav2vec 2.0 발표!!
Facebook 이 개발한 wav2vec 2.0 은 53000 시간의 라벨링 없는 데이터로 representation training 을 한 후, 10분의 라벨링 된 데이터로 음성인식기를 만들 수 있다.
- 라벨링 되어있지 않은 대량의 데이터로 representation 학습 후, 소량의 라벨링된 데이터로 fine tuning 을 하는 과정
= 즉, 음성 오디오만으로 강력한 표현(mutual information)을 pre-training 한 후, 음성인식 관련 down-stream task에 fine-tuning
- wav2vec 2.0 은 기존 wav2vec 에 비해 트랜스포머를 사용하여 성능을 더 높였다.
- 전사된 음성 10분(평균 12.5초 * 40문장)의 라벨링 된 데이터로 fine tuning 했을 때, LibriSpeech에 대해 WER 깨끗한 음성 5.2% WER / 시끄러운 음성 8.6% WER --> 40문장 읽으면 음성인식기가 만들어지는 수준
- 라벨링이 음성인식기를 만드는데 장애가 되는 점을 생각하면, 의미있는 연구
XLSR : wav2vec 2.0 과 함께 여러 언어에 공통되는 음성 단위를 학습할 수 있는 교차 언어 접근 방식도 개발됨
--> 레이블이 없는 소량의 음성만 있을 때, XLSR 을 사용 - 데이터가 거의 없는 언어는 더 많은 데이터를 가지고 있는 다른 언어로부터 도움받을 수 있음

wav2vec 2.0 핵심 3가지
1) contrastive task : latent speech representations 과 context representations 를 비슷하게 함으로써 unlabeled data 로 학습하는 방법
2) bi-directional contextualized representation : 현재 위치를 masking 하고 주변의 데이터로부터 masking 된 위치를 유추할 수 있는 트랜스포머 구조
3) vector quantized targets : gumbel softmax 방법으로 latent speech representations 에서 영향을 많이 미치는 벡터를 추출하는 방법
wav2vec 2.0 이 아닌 다른 self-supervised approaches for speech
- 오디오 신호를 reconstruct 하려는 접근법
- 모델이 음성의 모든 측면을 캡쳐해야한다는 단점 (녹음 환경, noise, 화자 정보) - 여러 옵션들을 비교하면서 화자가 다음에 무슨 말을 했는지 예측하려는 접근법
반면에, wav2vec 2.0 은?
- Wav2vec 2.0 learns a set of speech units, which are shorter than phonemes, to describe the speech audio sequence.
- 음성 오디오 시퀀스를 설명하기 위해 음소보다 짧은 음성 단위 세트 (a set of speech units) 학습 - 이 짧은 음성 단위 세트는 유한하기 때문에 background noise 와 같은 모든 변동을 나타낼 수는 없음
- Instead, the units encourage the model to focus on the most important factors to represent the speech audio.
- 대신, 이 speech units 은 모델이 음성 오디오를 표현하기 위한 가장 중요한 요소에 초점을 맞춤 - Wav2vec 2.0의 이러한 접근법이 위의 두 접근법보다 LibriSpeech 데이터셋에 대해 더 좋은 성능.
음성데이터 self-training 적용방법
1. Feature Encoder < f : X ⟼
raw waveform(음성 데이터) - multilayer CNN 인코더에 넣어 - 25ms 길이의 represent vector 로 변환
- 매 T 시점마다 latent speech representations z1, ... , zT 출력
- 변환된 represent vector = latent speech representations = 모델이 학습하고자 하는 target
- 이 representations z (z1, ... , zT ) 는 두 모듈 (quantizer, transformer) 에 공급됨

2. Quantization Module < Z ⟼ Q >

latent speech representation z 가 입력되는 모듈 중 하나인 quantization 모듈
- CNN 인코더를 통과한 output feature 인 zt 는 양자화 모듈(quantizer) Z ⟼ Q 를 사용하여 qt로 이산화
- quantizer 는 learned units 인벤토리 (codebook) 에서 latent audio representation (zt) 을 위한 speech unit (code words)을 선택함
- latent audio representations 의 절반은 트랜스포머에 입력되기 전 마스킹됨
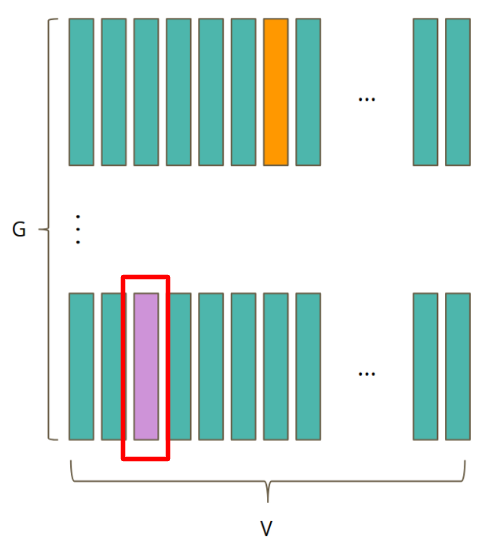
- codebook 행렬이 G개 --> G x V 크기의 multiple codebooks
- 하나의 codebook 은 V개의 code word 벡터 시퀀스 한 행에 대응됨.

- 즉, 위 빨간 박스 codebook e 가 G 개 존재하여 G x V 크기의 multiple codebooks 을 이룸.
- 이 multiple codebooks 행렬은 모두 학습가능한 파라미터로 구현
(내 생각 : 따라서 이 과정이 features 들을 학습하는 과정이고 여기서 계속 unsupervised learning 으로 가장 좋은 features 들을 뽑고 찾는 것인데, 이 과정들을 들여다보고 싶다.) - codebook 을 embedding matrix로, code word 를 embedding vector 로 생각하면 됨.
(wav2vec 2.0 에서는 G = 2, V = 320 사용) - codeword = 일종의 음소에 대한 representation 이라고 생각하면 됨.
- 아무리 언어가 다 달라도, 인간이 발음할 수 있는 음소들은 공통적인 부분이 있고 유한함. 이것을 마치 embedding vector 로 표현한 것임.
- codeword = 인간이 발음할 수 있는 phoneme 에 대한 representation = embedding vector
- 그리고 위의 codeword 를 모아 만든 행렬이 codebook.
- 즉, 하나의 codebook e 안에서 V 개의 음소(codeword) 중 현 시점에서 벡터 zt 와 가장 적절하게 대응될 음소 벡터 codeword 를 이산화 과정을 통해 고른 것이 qt.
Quantization 모듈 내부 작동 과정
- 인코딩된 zt가 레이어를 통과하면서 (codebook 내부의) logit 으로 변환
* G개의 multiple codebook 사용 - gumbel softmax / argmax 를 거쳐 one-hot encoding 되는 이산화 과정을 거침
* g번째 codebook 에서 v번째 code word 벡터가 선택될 확률을 gumbel softmax 로 표현한다면,
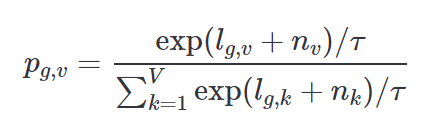
-
- 위의 원핫인코딩 결과를 가지고, 각 codebook 내에서 하나의 code word 벡터를 골라냄
(마치 NLP - embedding matrix에서 특정 단어에 해당되는 embedding 벡터 뽑아내듯) - code word 벡터는 G개의 codebook 행렬에서 각각 하나씩 추출됨.
- 따라서 총 G개의 e1, e2, ..., eG 벡터 추출.
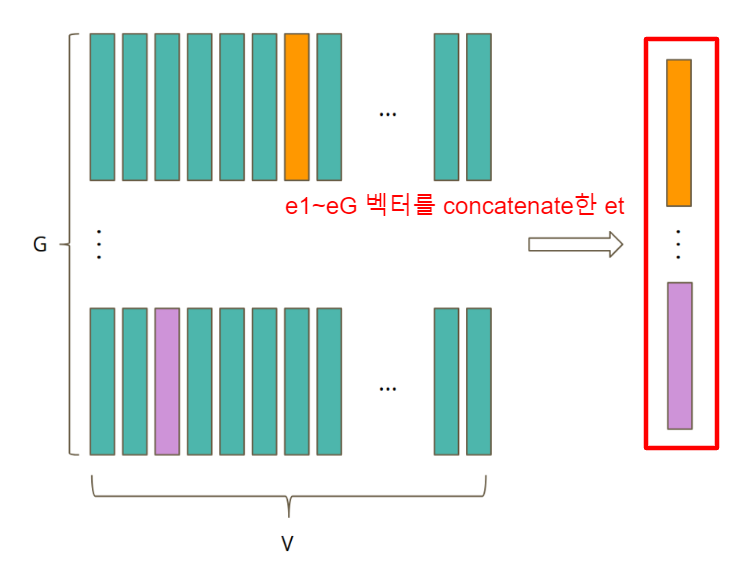
- 이 G 개의 벡터 모두를 concatenate 하여 et 를 만듦.
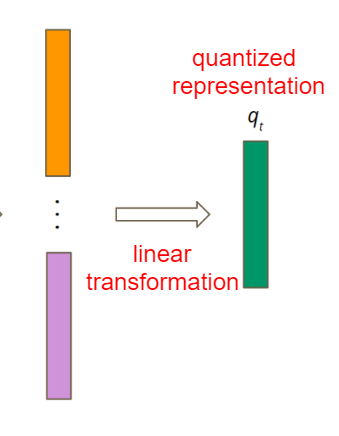
- linear transformation
(참고)
- quantization : 양자화
- 연속된 변화량(아날로그신호)을 유한개의 레벨(불연속적)로 구분하고, 각 레벨에 대해 특정 값을 부여하는 것.
- 따라서 vector quantization : 연속적으로 샘플링된 진폭들을 그룹핑하여 대표 값 몇개로 양자화
- N 개의 특징 벡터 집합 x 개를 K 개의 특징 벡터 집합 y 로 mapping 하는 것
- ex) 양자화 연산자 f(*) --> y = f(x) 와 같이 mapping 하면,
x = {유재석, 이정재, 강호동, 싸이, 아이유}
y = {가수, 영화배우, 개그맨} 일 때,
가수 = {싸이, 아이유}. 영화배우 = {이정재}, 개그맨 = {유재석, 강호동} 으로 mapping됨.
y의 각 원소(feature)들은 codeword 또는 cluster 이라고 하고, y 를 codebook 이라고 함. - 즉, 음성인식에서 wav2vec 2.0 에서 행해지는 vector quantization 이란
- 학습가능한 embedding matrix 를 codebook 으로 사용하여, 특징벡터들을 codebook 내의 codeword features 들로 mapping 시키는 과정이다.
- encoder 를 거친 특징 벡터 z 를 Gumbel softmax 또는 K-means 클러스터링으로 codeword 에 mapping 시키는 과정.
(내생각 : 여기서 codeword 가 무엇인지를 알아내면, downstream task 에서 유의미한 feature 가 무엇인지 알 수 있지 않을까.. 이 과정을 시각화해보고 싶네.. 그리고 embedding matrix 를 codebook 으로 사용하는데, embedding matrix 가 무엇을 나타내지??)
3. Transformer Module < Z ⟼
- 트랜스포머는 전체 오디오 시퀀스의 정보를 추가함
- representations 인 z를 - masking 트랜스포머에 넣으면 - 주변 정보 이용하여 복원된 context representations 생성됨
--> context network 트랜스포머 이용 - 전체 시퀀스로부터 c1, ... , cT 정보를 capturing 함
- 트랜스포머의 출력은 contrastive task 를 푸는데 사용 - 이를 위해 모델은 마스크된 위치에 대한 correct quantized speech units 를 식별해야 함
--> 목표 : context representations 와 해당 위치의 latent speech representations 이 유사하도록 학습
= contrastive loss
이 contrastive loss 를 최소화하면 음성 데이터 안에 공통적으로 가지고 있는 mutual information 최대화 가능
이런식으로 학습된 wav2vec 2.0 을 활용하면 음성에서 좋은 representation vector 추출 가능
--> 이를 fine-tuning 하면 적은 데이터만으로도 좋은 성능 보장
+ masking
전체 오디오 구간 중 6.5 를 랜덤하게 고르고 - 선택된 zt 에서 z(t+10) 만큼 마스킹 - 전체 T 의 49% 가 평균 span length 인 299ms 로 마스킹됨
** 모델 훈련
오디오의 마스킹된 부분에 대한 올바른 speech unit 를 예측 + 그 speech unit 이 무엇이어야 하는지 학습하도록
--> 트랜스포머의 bidirectional encoder representations 과 유사하게, wav2vec 2.0 도 오디오의 마스킹된 부분에 대한 speech units 을 예측하여 훈련됨.
--> 주요 차이점 : 음성 오디오는 단어나 다른 단위로의 명확한 분할 없이 녹음의 많은 측면을 포착하는 연속 신호
--> 이 연속 신호 처리 위해 25ms 길이의 basic units 을 학습하여 높은 수준의 상황별 표현 학습할 수 있도록 함
--> 이 basic units 들은 다른 음성 오디오 녹음들을 describe 하고 + wav2vec 을 더 robust 하게 함
--> 이를 통해 레이블된 훈련데이터를 100배 적게 사용하더라도 최고의 semi-supervised 방법을 능가할 수 있는 음성인식시스템 wav2vec 2.0 구축
Reference
- https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/
- http://dsba.korea.ac.kr/review/?mod=document&uid=1408
- https://smilegate.ai/2020/08/05/wav2vec-2/
- https://kaen2891.tistory.com/83
- https://zerojsh00.github.io/posts/Wav2Vec2/
- https://zerojsh00.github.io/posts/Vector-Quantization/